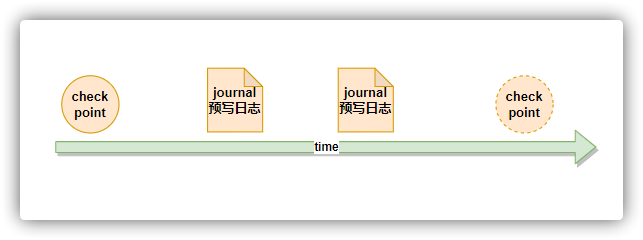
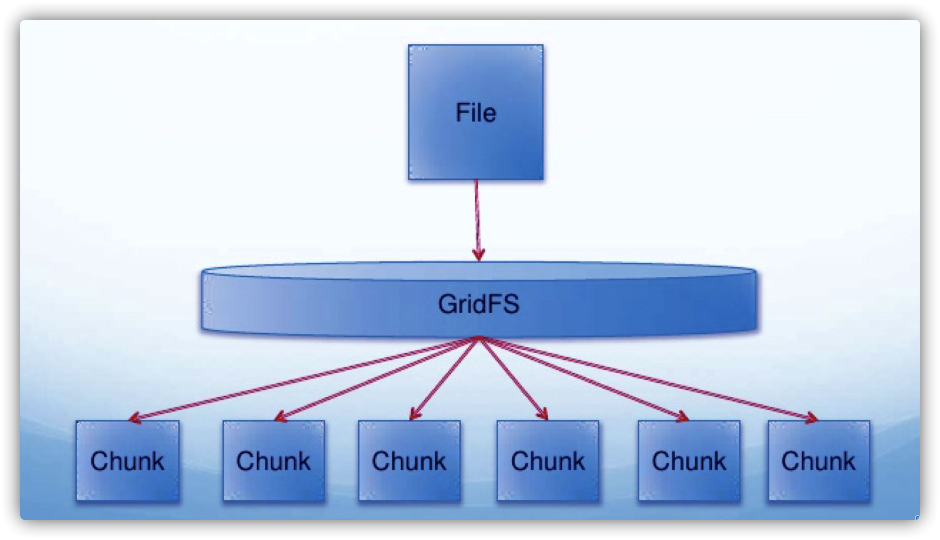
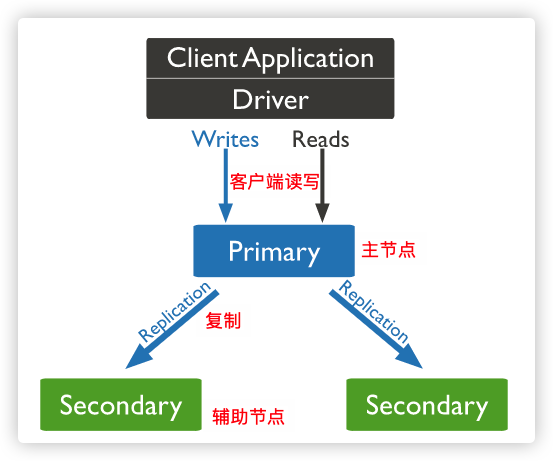
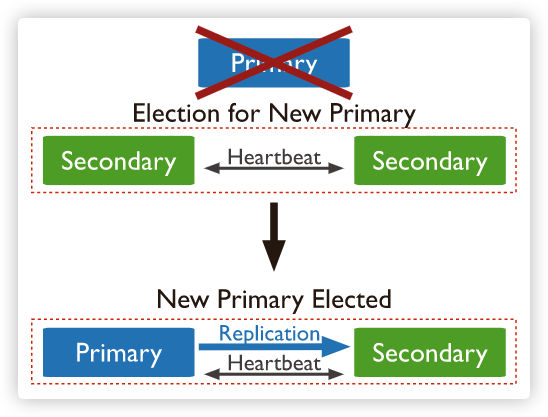
思维导图
MongoDB 是一款开源的分布式文档数据库,介于关系型数据库和非关系型数据库之间。它是功能最丰富、最像关系型数据库的非关系型数据库产品之一。 MongoDB 支持以 JSON(BSON 是一种类似于 JSON 的二进制格式) 格式存储和查询文档,其底层由 C++ 语言编写。
在 MongoDB 中,每个记录都是一个 JSON 文档,类似于 JSON 对象。字段的值可以包括其他文档、数组和对象数组,因此可以存储相对复杂的数据类型。而且,MongoDB 最大的特点是支持强大的查询语言,其语法类似于面向对象的查询语言,可以实现关系型数据库单表查询的绝大部分功能,并支持对数据建立索引。这使得 MongoDB 在处理大量非结构化数据时非常适合使用。
使用文档的优点:
文档(即对象)对应于许多编程语言中的内置数据类型。 嵌入式文档和数组减少了对昂贵连接(join)的需求。 动态模式(不需要事先定义表结构或字段)支持流畅的多态性。 与关系型数据库对比
MongoDB 关系型数据库 数据库 数据库 集合 表 文档 行 字段 列 索引 索引 _id 主键 视图 视图 聚合操作($lookup) 表连接
数据模型
数据模型 定义 数据库 最外层的概念,可以理解为逻辑上的名称空间,一个数据库包含多个不同名 称的集合。 集合 相当于SQL中的表,一个集合可以存放多个不同的文档。 文档 一个文档相当于数据表中的一行,由多个不同的字段组成。 字段 文档中的一个属性,等同于列(column)。 索引 索引是一种辅助存储技术,用于加速查询。索引是一种特殊的文档,它包含一个或多个键值对,这些键值对与查询的键值对匹配。 _id _id 是 MongoDB 文档中的一个特殊字段,用于唯一标识每个文档。它是一个内置字段,类似RDBMS的主键。 视图 可以看作一种虚拟的(非真实存在的)集合,与SQL中的视图类似。从MongoDB 3.4版本开始提供了视图功能,其通过聚合管道技术实现 聚合 ($lookup) 用于在集合之间进行关联查询。它类似于 SQL 中的内连接,但可以支持更多的查询操作。
支持的数据类型
数据类型 类型描述 整数类型 (Integer) 支持正整数、负整数和零值。 浮点数类型 (Float) 支持单精度浮点数和双精度浮点数。 字符串类型 (String) 支持任意长度的字符串。 布尔类型 (Boolean) 支持 true 和 false 两个值。 数组类型 (Array) 支持任意长度的数组。 对象类型 (Object) 支持包含多个字段的对象。 嵌套类型 (Deep Object) 支持嵌套对象,即包含多个嵌套对象的类型。 日期类型 (Date) 支持 JavaScript 日期对象。 数字类型 (Number) 支持任意精度的数字。 二进制数据 (BinData) 支持二进制数据。 自定义类型 (Custom Type) 支持用户定义的数据类型。
MongoDB基于灵活的JSON文档模型,非常适合 敏捷式的快速开发。与此同时,其与生俱来的高可用、 高水平扩展能力使得它在处理海量、高并发的数据应用时颇具优势
动态模式
反范式:相对RDBMS错中复杂的表关系,mongoDB的JSON模型允许数组、嵌套对象结构,在数据结构上更接近对象关系,开发代码量低
字段扩展:mongoDB支持动态新增字段,不需要修改表结构,开发灵活,快速响应业务变化
强大的查询语言
相比其他非关系型数据库,MongoDB支持丰富的查询语言,支持读和写操作(CRUD),比如数据聚合、文本搜索和地理空间查询等。
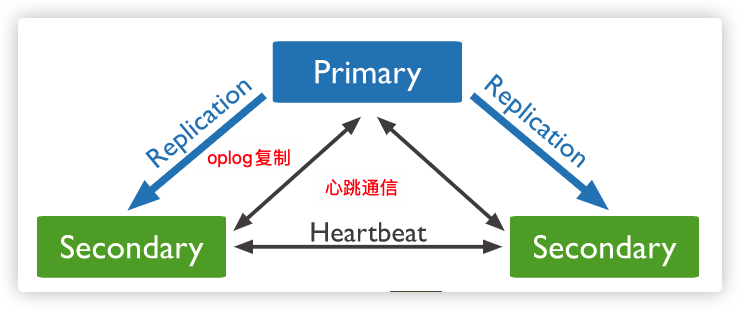
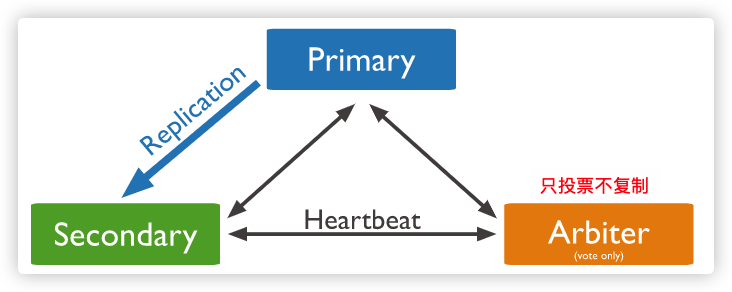
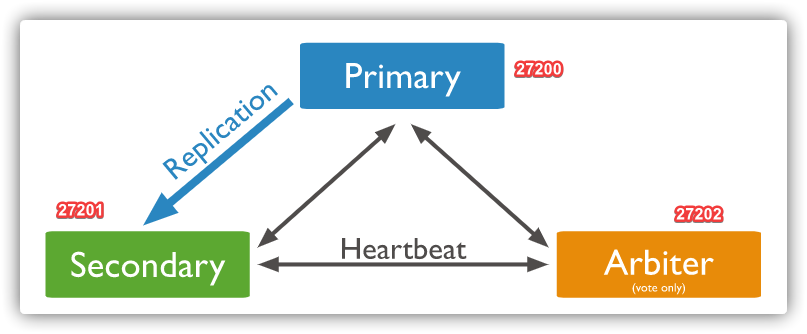
高可用
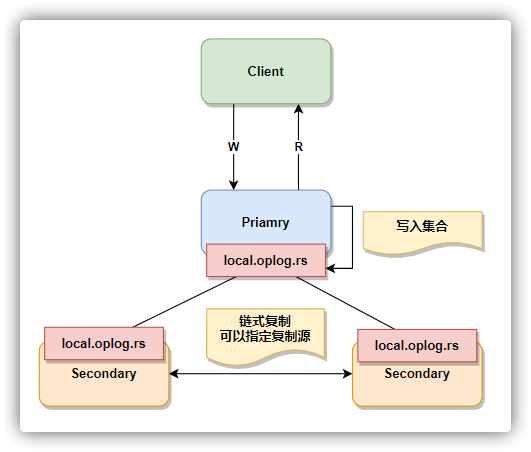
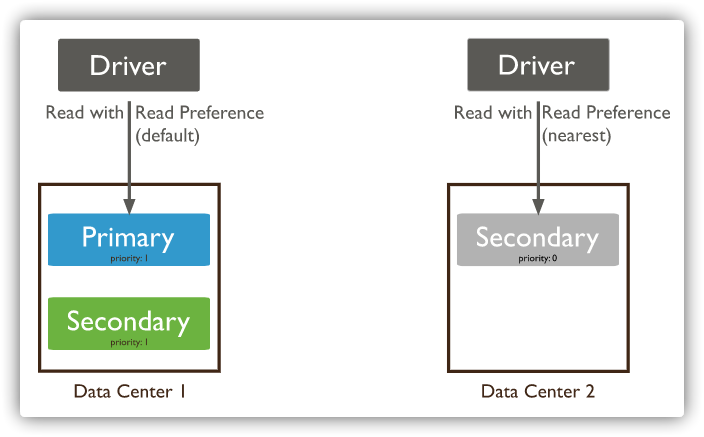
副本集 是一组维护相同数据集合的 mongod实例,提供了冗余和提高了数据可用性
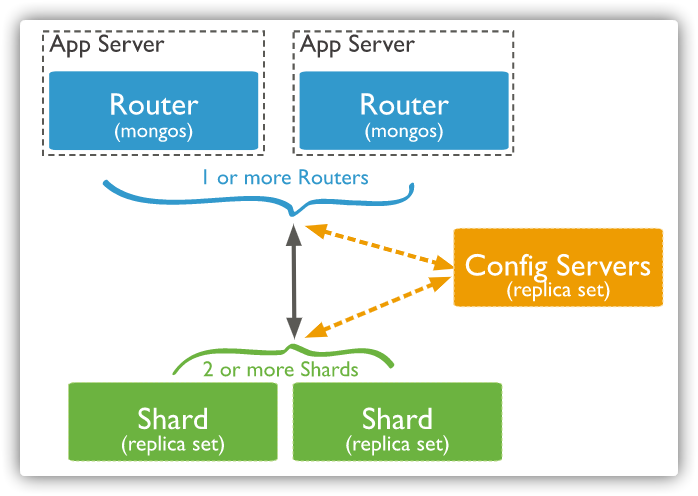
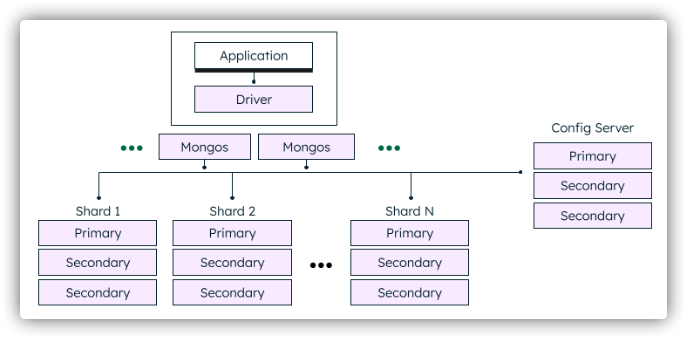
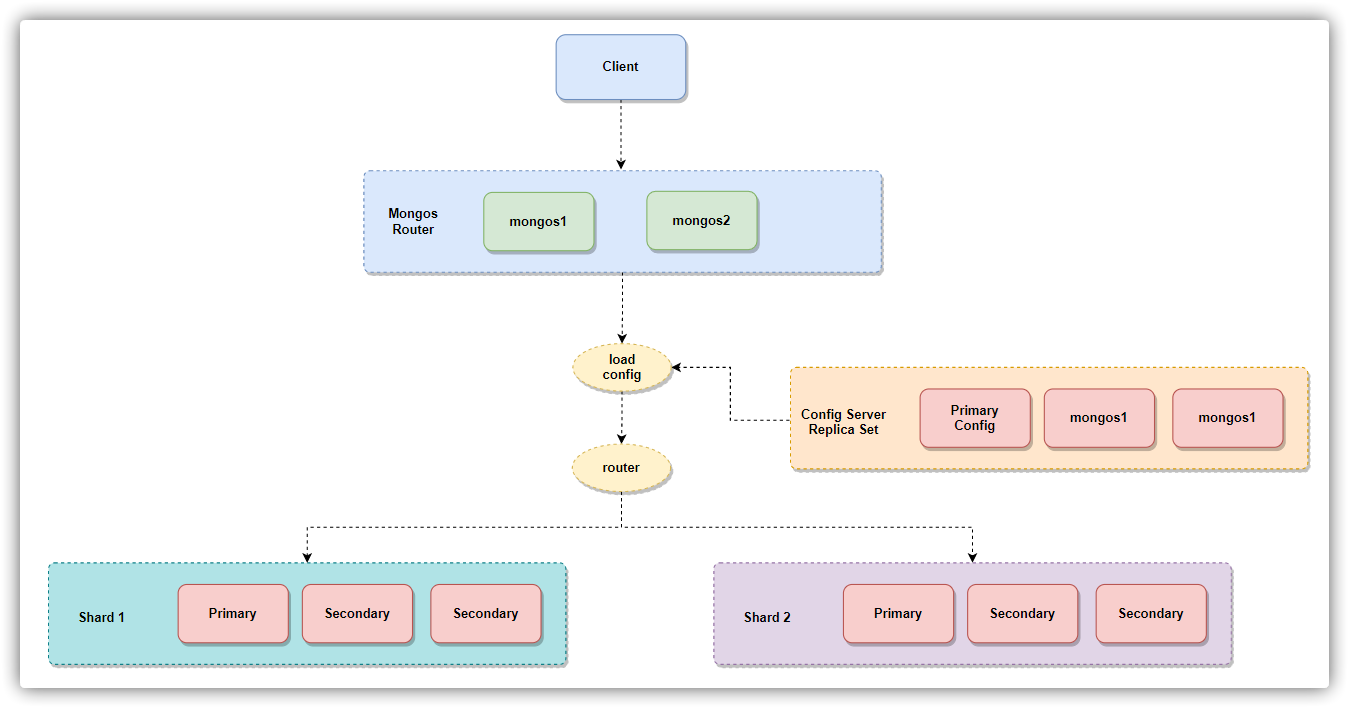
水平扩展
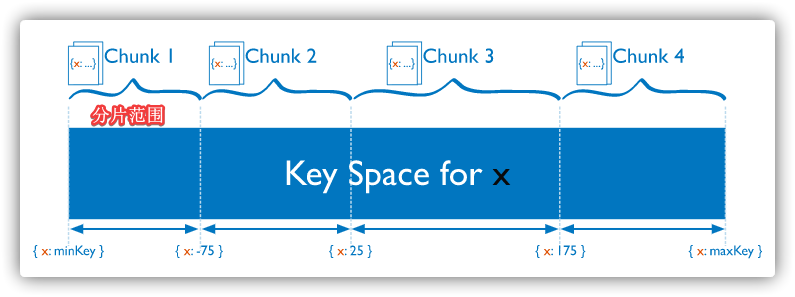
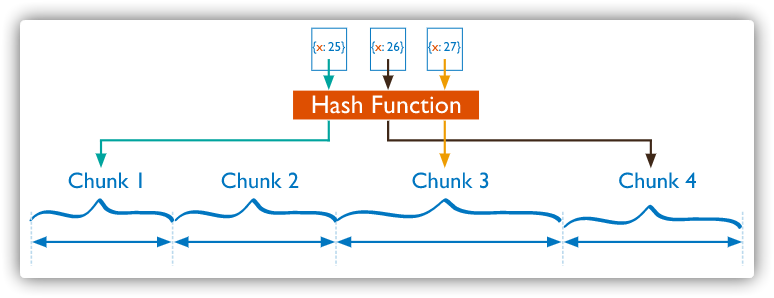
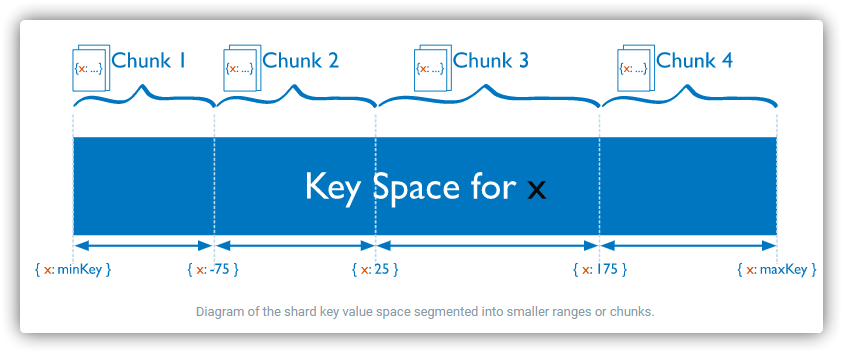
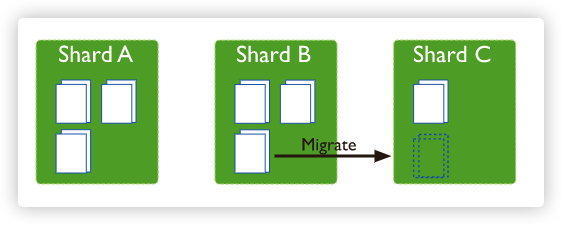
分片 将数据分布在一个集群的机器上,支持集群节点扩展从3.4开始,MongoDB支持基于分片键 创建数据区域 。在平衡群集中,MongoDB仅将区域覆盖的读写定向到区域内的那些分片 支持多种存储引擎
存储引擎
应用场景 MongoDB 优势 实时数据处理 MongoDB 支持实时数据处理,可以实时存储和查询数据 关系型数据库替代品 MongoDB 可以存储非结构化数据,可以轻松替代关系型数据库 大规模数据处理 MongoDB 支持高效的批量查询和数据批量插入、更新、删除 日志记录 MongoDB 支持高效的日志记录和查询,可以实时记录和查询日志数据 API 存储 MongoDB 可以存储 API 文档和数据,支持实时查询和更新 分布式文件系统 MongoDB 可以充当分布式文件系统的数据库,支持读写分离和数据备份 分布式消息队列 MongoDB 可以充当分布式消息队列的数据库,支持消息存储和查询 社交场景 存储存储用户信息,以及用户发表的朋友圈信息 物流场景 订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来 物联网场景 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析
选型原因
不需要复杂join查询以及事务处理 需要更高的读写QPS(3000以上) 需要至少TB或PB级别的数据存储 业务发展迅速,需要快速水平扩展 要求应用高可用 需要地理位置查询,文本查询 安装平台为Linux,安装版本为社区6.x版本
TODO
创建配置和数据目录
1 2 3 4 5 6 7 8 9 mkdir -p /data/mongodb/db
在配置目录下创建 mongod.conf 配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 net:
安装MongoDB
1 2 3 4 5 6 7 8 9 docker run -d \27017 :27017 \/data/m ongodb/db/ data:/data/ db \/data/m ongodb/backup:/ data/backup \/data/m ongodb/log:/ data/log \/data/m ongodb/config:/ data/conf \true mongo \
添加账号
1 2 3 4 5 docker exec -it mongodb /bin/ bash"admin" ,pwd:"123456" ,roles:[{role:'root' ,db:'admin' }]})exit
Mongo shell是一个命令行工具,用于连接和操作MongoDB数据库。并为开发人员提供了直接测试数据库查询和操作的方法
–port:指定端口,默认为27017
–host:连接的主机地址,默认127.0.0.1
Mongo shell 是基于 JavaScript 语法实现的,MongoDB使用了SpiderMonkey作为其内部的JavaScript解释器引擎,这是由Mozilla官方提供的JavaScript内核解释器,该解释器也被同样用于大名鼎鼎的Firefox浏览器产品之中。 SpiderMonkey对ECMA Script标准兼容性非常好,可以支持ECMA Script 6。可以通过下面的命令检查JavaScript解释器的版本
1 2 interpreterVersion ()MozJS -60
命令行帮助
要查看选项列表和启动mongo--help
Shell帮助
要查看选项列表和启动mongo--help
数据库帮助
当需要查看服务器上的数据库列表,请使用 show dbs 命令
当需要查看可在db对象上使用的方法的帮助列表,请调用db.help()
当需要查看在 shell中查看某些方法的具体实现,请键入不带括号()的db.<method name>,如以下示例所示,它将返回方法db.updateUser()
表级别帮助
要查看当前数据库中的集合列表,请使用 show collections 命令
要查看收集对象上可用方法的帮助(例如db.<collection>),请使用db.<collection>.help()方法
创建集合 db.createCollection(name, options)
游标相关帮助
在mongo shell中使用find()方法执行读取操作时,可以使用各种游标方法来修改find()行为,并可以使用各种JavaScript方法来处理从find()方法返回的游标
处理游标的一些有用方法是:处理游标的一些有用方法是:
选择和创建数据库
如果数据库不存在则自动创建,当刚开始创建一个数据库的时候信息存储在内存中,所以刚创建的数据库是查询不到的。当数据库创建一个集合后,才会把数据库信息持久化到磁盘,此时数据库才能被检索
查看数据库
1 show dbs 或 show databases
查看当前数据库
删除数据库
用于删除已持久化的数据库
数据库命名规则
默认数据库
admin:这个特殊的数据库主要用于管理 MongoDB 实例,可以创建、删除用户和管理角色。local:用来存储本地数据的,比如保存自己的复制集状态、操作日志等信息,这个数据库数据不会被复制(可以存储不想被其他节点复制的数据)。config:用来存储分片集群的配置信息的,如果正在使用 MongoDB 的分片集群功能,则该集群的配置信息将保存在此数据库中。特殊集合:
操作 说明 db.createCollection(name, options[可选])创建集合 show collections查看集合 db.test.drop()删除集合
集合的创建分 显式 和 隐式
显式:db.createCollection(name, options[可选]) 隐式:当使用插入方法(insert)插入到一个不存在的集合时,会自动创建该集合 注意
通常采用隐式创建集合,即当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合。
集合参数 描述 capped 固定集合(Capped Collections)是性能出色且有着固定大小的集合,对于大小固定,我们可以想象其就像一个环形队列,当集合空间用完后,再插入的元素就会覆盖最初始的头部的元素 timeseries 指定集合是否为时间序列集合。时间序列集合包含时间戳和数据值,用于记录时间序列数据。 expireAfterSeconds 指定集合中文档的过期时间,单位为秒。当文档的过期时间到达时,该文档将被删除。_id 自动删除文档,并且值必须是日期类型。请参阅 TTL Indexes. clusteredIndex 指定集合是否使用聚簇索引。集群索引是将集合中的文档按照某种规则进行排序的索引,可以提高查询效率。 changeStreamPreAndPostImages 指定集合是否使用 changeStream。changeStream 是一种用于监视集合中文档更改的 API,可以实时获取集合中文档的更改。 size 指定集合的大小,单位为字节。可以使用 size 命令查询集合的大小。 max 指定集合中文档的最大数量。如果集合中已经有很多文档,则创建集合时可能会失败。 storageEngine 指定集合使用的存储引擎。 validator 指定集合中的文档验证器。验证器用于检查文档是否符合特定的验证规则。 validationLevel 指定集合中的文档验证级别。验证级别越高,验证器的要求也越高,可以提高查询效率,但可能会导致文档验证时间较长。 validationAction 指定集合中的文档验证失败后的行为。可以设置为 drop 或 continue,分别表示验证失败时将文档删除或继续验证。 indexOptionDefaults 指定集合中索引默认的属性。 viewOn 指定集合中文档的视图名称。可以使用 viewOn 命令查询文档的视图名称。 pipeline 指定查询语句中的过滤条件。 collation 指定集合中文档的排序规则。 writeConcern 指定写入操作的可靠性。writeConcern 文档包含了有关写入操作可靠性的详细信息。
CURD操作指的是文档的创建、读、更新以及删除操作
SQL到mongo的操作映射
创建 或 插入 操作将新文档添加到集合中。如果该集合当前不存在,则插入操作将创建该集合
MongoDB提供以下将文档插入集合的方法:
MongoDB中的所有写入操作在单个文档的级别上都是原子的,参考原子性和事务
将一个文档插入到一个集合中,支持 writeConcern 写关注
1 2 3 4 5 6 db.collection .insertOne (document >,writeConcern : <document >
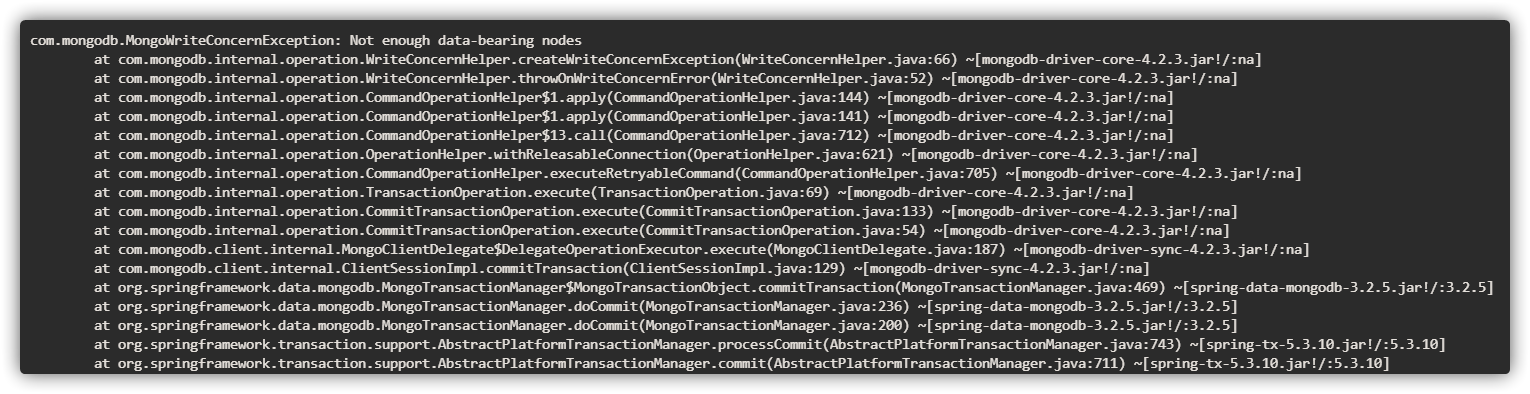
writeConcern 写关注 决定一个写操作落到多少个节点上才算成功。writeConcern w 属性的取值包括:
0: 发起写操作,不进行写操作确认1: 请求确认写入操作已传播到复制集中的独立副本或主节点。是MongoDB的默认写关注点n: 写操作需要被复制到指定节点数才算成功(默认为1,主分片写入成功)majority:写操作需要被复制到大多数节点上才算成功(半数以上)1 2 3 4 5 6 7 8 9 10 11 db.user .insertOne ({ "userName" : "wgf" , "age" : 20 , "sex" : 1 , "address" : "shenzhen" } )"acknowledged" : true ,"insertedId" : ObjectId ("64414ce28dddba084284aa92" )
指定插入1个副本后才算写入成功
1 2 3 4 5 6 7 8 9 10 db.user .insertOne ({"userName" : "test" ,"age" : 21 ,"sex" : 1 ,"address" : "shanghai" writeConcern : {w : 1
将多个文档插入到一个集合中
1 2 3 4 5 6 7 db.collection .insertMany (
writeConcern 写关注 ordered: 是否按照顺序写入,默认为truetrue:顺序插入,如果某个文档插入失败,那么后面的插入操作也会终止false:无序插入,如果某个文档插入失败,MongoDB 会记录错误,但不会停止插入操作(提高插入性能) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 db.user .insertMany ( [ { "userName" : "zhangsan" , "age" : 18 , "sex" : 1 , "address" : "beijing" }, { "userName" : "lisi" , "age" : 26 , "sex" : 1 , "address" : "hainan" }, ], { "ordered" : true } "acknowledged" : true ,"insertedIds" : [ ObjectId ("644169568dddba084284aaa5" ), ObjectId ("644169568dddba084284aaa6" )
将一个或多个文档插入集合
1 2 3 4 5 6 7 db.collection .insert (
1 2 3 4 5 6 7 8 9 10 11 12 13 14 db.user .insert ({"userName" : "luliu" ,"age" : 28 ,"sex" : 0 ,"address" : "tianjing" "writeConcern" : {"w" : 1 Inserted 1 record (s) in 115ms
覆盖现有的文档或插入新文档,具体取决于其document参数
1 2 3 4 5 6 db.collection .save (document >,writeConcern : <document >
1 db.products .save ( { _id : 100 , item : "water" , qty : 30 } )
如果 _id=100 的记录存在则更新文档(全量覆盖),否则新增文档
查询语法如下
1 db.collection .find (query, projection, options)
参数说明:
query projection <field>: <1 or true>,不返回 <field>: <0 or false>options 如果查询返回的条目数量较多,mongo shell则会自动实现分批显示。默认情况下每次只显示20条,可以输入 it 命令读取下一批
测试数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 [ { "_id" : ObjectId("5e7835466b6f69d428000001" ), "name" : "Alice" , "age" : 30.0 , "address" : { "city" : "New York" , "state" : "NY" , "zip" : "10001" } } , { "_id" : ObjectId("5e7835476b6f69d428000002" ), "name" : "Bob" , "age" : 25.0 , "address" : { "city" : "Chicago" , "state" : "IL" , "zip" : "60606" } } , { "_id" : ObjectId("5e7835486b6f69d428000003" ), "name" : "Charlie" , "age" : 28.0 , "address" : { "city" : "Houston" , "state" : "Texas" , "zip" : "77002" } } , { "_id" : ObjectId("5e7835496b6f69d428000004" ), "name" : "Dave" , "age" : 35.0 , "address" : { "city" : "San Francisco" , "state" : "CA" , "zip" : "94107" } } , { "_id" : ObjectId("5e7835496b6f69d428000005" ), "name" : "Eve" , "age" : 20.0 , "address" : { "city" : "New York" , "state" : "NY" , "zip" : "10001" } } , { "_id" : ObjectId("5e7835496b6f69d428000006" ), "name" : "Adam" , "age" : 25.0 , "address" : { "city" : "London" , "state" : "GB" , "zip" : "E1 4ST" } } , { "_id" : ObjectId("5e7835496b6f69d428000007" ), "name" : "Greg" , "age" : 30.0 , "address" : { "city" : "New York" , "state" : "NY" , "zip" : "10001" } } , { "_id" : ObjectId("5e7835496b6f69d428000008" ), "name" : "Jack" , "age" : 25.0 , "address" : { "city" : "London" , "state" : "GB" , "zip" : "E1 1AA" } } , { "_id" : ObjectId("5e7835496b6f69d428000009" ), "name" : "Emily" , "age" : 20.0 , "address" : { "city" : "Paris" , "state" : "FR" , "zip" : "10003" } } ]
查询
1 2 3 4 5 6 7 8 9 10 db.getCollection('user').find({ : "Alice" } , { : 1 , : 1 } , { : 5 } )
SQL Mongo 运算符 说明 a = 1 {a: 1} 或 {a: {$eq: 1}} $eq 等于 a != 1 {a: {$ne: 1}} $ne 不等于 a > 1 {a: {$gt: 1}} $gt 大于 a >= 1 {a: {$gte: 1}} $gte 大于等于 a < 1 {a: {$lt: 1}} $lt 小于 a <= 1 {a: {$lte: 1}} $lte 小于等于 a IN (1, 2, 3) {a: {$in: [1, 2, 3]}} $in 多值查询 a NOT IN (1,2,3) {a: {$nin: [1,2,3]}} $nin 多值查询取反
SQL Mongo 运算符 说明 a = 1 AND b = 1 {a: 1, b: 1}或{$and: [{a: 1}, {b: 1}]} $and 并且 a = 1 OR b = 1 {$or: [{a: 1}, {b: 1}]} $or 或者 a != 1 {a: { $not: { $eq: 1}}} $not 逻辑否定 a!=1 AND b!=1 {$nor: [{a:1}, {b: 1}]} $nor 用于实现多个查询条件之间的逻辑否定
SQL Mongo 运算符 说明 a IS NULL {a: {$exists: false}} $exists 判断对应字段值是否存在 - {“title” : {$type : ‘string’}} BSON 数据类型 $type 获取某个字段为指定类型的文档
Mongo 运算符 说明 { tags: { $all: [ “ssl” , “security” ] } } $all 匹配包含查询中指定的所有元素的数组 { results: { $elemMatch: { product: “xyz”, score: { $gte: 8 } } } } $elemMatch 匹配数组字段,该数组至少有一个元素满足所有查询条件 { tag: { $size: 1 } } $size 查询特定长度的数组
db.collection.find(query, projection, options)
查询一个或多个文档,默认返回前20个文档,输入 it 继续迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 db.getCollection('user').find({ : { : 32 } } , { : true , : true } { "_id" : ObjectId("5e7835496b6f69d428000004" ), "name" : "Dave" , "age" : 35.0 }
db.collection.findOne(query, projection, options)
查询单个文档,返回一个满足集合或视图上指定查询条件的文档。如果有多个文档满足查询,则该方法按照反映文档在磁盘上的顺序的 自然顺序返回第一个文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 db.getCollection('user').findOne({ } , { : true , : true } { "_id" : ObjectId("5e7835466b6f69d428000001" ), "name" : "Alice" , "age" : 30.0 }
db.collection.findAndModify(document)
以原子方式修改并返回单个文档。默认情况下,返回的文档不包括对更新所做的修改(旧文档)。要返回包含更新修改的文档,请使用 new 选项(新文档)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 db.collection.findAndModify({ : <document>, : <document>, : <boolean>, : <document or aggregation pipeline>, : <boolean>, : <document>, : <boolean>, : <boolean>, : <document>, : <document>, : [ <filterdocument1>, ... ] , : <document> } );
比较
和 findOneAndUpdate() 比较,findAndModify()方法则可以执行更复杂的操作,如删除、插入、修改等。该方法也可以返回更新前的文档或更新后的文档。
参数 类型 描述 querydocument 可选的。修改的选择标准。 query字段使用与db.collection.find()方法中使用的query selectors相同的query selectors。虽然查询可能匹配多个文档,但findAndModify() 只会选择一个文档来修改 。 如果未指定,则默认为空文档。 从 MongoDB 3.6.14(和 3.4.23)开始,如果查询参数不是文档,则操作错误。 sortdocument 可选的。如果查询选择多个文档,则确定操作修改的文档。 findAndModify()修改此参数指定的 sort order 中的第一个文档。 从 MongoDB 3.6.14(和 3.4.23)开始,如果 sort 参数不是文档,则操作错误。 removeboolean 必须指定remove或update字段。删除query字段中指定的文档。将其设置为true以删除所选文档。默认值为false。 updatedocument 必须指定remove或update字段。执行所选文档的更新。 update字段使用相同的更新 operators或field: value规范来修改所选文档。 newboolean 可选的。当true时,返回修改后的文档而不是原始文档。 findAndModify()方法忽略remove操作的new选项。默认值为false。 fieldsdocument 可选的。 return 的字段子集。 fields文档指定包含1的字段,如:fields: { <field1>: 1, <field2>: 1, ... }。见投影。 从 MongoDB 3.6.14(和 3.4.23)开始,如果 fields 参数不是文档,则操作错误。 upsertboolean 可选的。与update字段结合使用。 当true,findAndModify()时: 如果没有文件匹配query,则创建一个新文档。有关详细信息,请参阅upsert 行为。 更新与query匹配的单个文档。 要避免多次 upsert,请确保query字段为唯一索引。 默认为false。 bypassDocumentValidationboolean 可选的。允许db.collection.findAndModify在操作期间绕过文档验证。这使您可以更新不符合验证要求的文档。 version 3.2 中的新内容。 writeConcerndocument 可选的。表示写关注的文件。省略使用默认写入问题。 version 3.2 中的新内容。 maxTimeMSinteger 可选的。指定处理操作的 time 限制(以毫秒为单位)。 collationdocument 可选的。 指定要用于操作的整理。 整理允许用户为 string 比较指定 language-specific 规则,例如字母和重音标记的规则。 排序规则选项具有以下语法: 排序规则:{ locale:, caseLevel:, caseFirst:, strength:, numericOrdering:, alternate:, maxVariable:, backwards :} 指定排序规则时,locale字段是必填字段;所有其他校对字段都是可选的。有关字段的说明,请参阅整理文件。 如果未指定排序规则但集合具有默认排序规则(请参阅db.createCollection()),则操作将使用为集合指定的排序规则。 如果没有为集合或操作指定排序规则,MongoDB 使用先前版本中用于 string 比较的简单二进制比较。 您无法为操作指定多个排序规则。对于 example,您不能为每个字段指定不同的排序规则,或者如果使用排序执行查找,则不能对查找使用一个排序规则,而对排序使用另一个排序规则。 version 3.4 中的新内容。 arrayFiltersarray 可选的。过滤器文档的 array,用于确定要在 array 字段上为更新操作修改哪些 array 元素。 在更新文档中,使用$ []过滤后的位置 operator 来定义标识符,然后在 array 过滤器文档中进行 reference。如果标识符未包含在更新文档中,则不能为标识符提供 array 过滤器文档。 注意 <identifier>必须以小写字母开头,并且只包含字母数字字符。 您可以在更新文档中多次包含相同的标识符;但是,对于更新文档中的每个不同标识符($[identifier]),您必须指定恰好一个 对应的 array 过滤器文档。也就是说,您不能为同一标识符指定多个 array 过滤器文档。对于 example,如果 update 语句包含标识符x(可能多次),则不能为arrayFilters指定以下内容,其中包含 2 个单独的x过滤器文档: [ { “x.a”: { $gt: 85 } }, { “x.b”: { $gt: 80 } } ] 但是,您可以在同一标识符上指定复合条件单个过滤器文档,例如以下示例: // Example 1 [ { or: [{"x.a": {gt: 85}}, {“x.b”: {$gt: 80}}] } ] // Example 2 [ { and: [{"x.a": {gt: 85}}, {“x.b”: {$gt: 80}}] } ] // Example 3 [ { “x.a”: { $gt: 85 }, “x.b”: { $gt: 80 } } ] 例如,请参阅为 Array Update Operations 指定 arrayFilters。 version 3.6 中的新内容。
更新并返回新的文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 db.user.findAndModify({ : { : ObjectId("5e7835466b6f69d428000001" )} , : { : { age: 1 } } , : true } ){ "_id" : ObjectId("5e7835466b6f69d428000001" ), "name" : "Alice" , "age" : 31.0 , "address" : { "city" : "New York" , "state" : "NY" , "zip" : "10001" } }
db.collection.findOneAndDelete(filter, options)
根据 filter 和 sort 条件删除单个文档,返回已删除的文档
1 2 3 4 5 6 7 8 9 10 db.collection.findOneAndDelete(, { : <document>, : <document>, : <document>, : <number>, : <document>}
参数 类型 描述 filterdocument 更新的选择标准。可以使用与find()方法相同的query selectors。 指定空文档{ }以删除集合中返回的第一个文档。 如果未指定,则默认为空文档。 从 MongoDB 3.6.14(和 3.4.23)开始,如果查询参数不是文档,则操作错误。 projectiondocument 可选的。 return 的字段子集。 要_返回返回文档中的所有字段,请省略此参数。 从 MongoDB 3.6.14(和 3.4.23)开始,如果投影参数不是文档,则操作错误。 sortdocument 可选的。为filter匹配的文档指定排序 order。 从 MongoDB 3.6.14(和 3.4.23)开始,如果 sort 参数不是文档,则操作错误。 见cursor.sort()。 maxTimeMSnumber 可选的。指定操作必须在其中完成的 time 限制(以毫秒为单位)。如果超出限制则引发错误。 collationdocument 可选的。 指定要用于操作的整理。 整理允许用户为 string 比较指定 language-specific 规则,例如字母和重音标记的规则。 排序规则选项具有以下语法: 排序规则:{ locale:, caseLevel:, caseFirst:, strength:, numericOrdering:, alternate:, maxVariable:, backwards :} 指定排序规则时,locale字段是必填字段;所有其他校对字段都是可选的。有关字段的说明,请参阅整理文件。 如果未指定排序规则但集合具有默认排序规则(请参阅db.createCollection()),则操作将使用为集合指定的排序规则。 如果没有为集合或操作指定排序规则,MongoDB 使用先前版本中用于 string 比较的简单二进制比较。 您无法为操作指定多个排序规则。对于 example,您不能为每个字段指定不同的排序规则,或者如果使用排序执行查找,则不能对查找使用一个排序规则,而对排序使用另一个排序规则。 version 3.4 中的新内容。
按照名称排序,删除第一个文档并返回删除的文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 db.user.findOneAndDelete({ : { $gte: 30 } } , { : { : 1 } } { "_id" : ObjectId("5e7835466b6f69d428000001" ), "name" : "Alice" , "age" : 31.0 , "address" : { "city" : "New York" , "state" : "NY" , "zip" : "10001" } }
db.collection.findOneAndReplace(filter, replacement, options)
根据filter和sort条件修改和替换单个文档(全量替换,除了 _id字段)
1 2 3 4 5 6 7 8 9 10 11 12 db.collection.findOneAndReplace(, , { : <document>, : <document>, : <number>, : <boolean>, : <boolean>, : <document>}
参数 类型 描述 filterdocument 更新的选择标准。可以使用与find()方法相同的query selectors。 指定一个空文档{ }以替换集合中返回的第一个文档。 如果未指定,则默认为空文档。 从 MongoDB 3.6.14(和 3.4.23)开始,如果查询参数不是文档,则操作错误。 replacementdocument 替换文件。 不能包含更新 operators。 <replacement>文档无法指定与替换文档不同的_id value。 projectiondocument 可选的。 return 的字段子集。 要_return 匹配文档中的所有字段,请省略此参数。 从 MongoDB 3.6.14(和 3.4.23)开始,如果投影参数不是文档,则操作错误。 sortdocument 可选的。为filter匹配的文档指定排序 order。 从 MongoDB 3.6.14(和 3.4.23)开始,如果 sort 参数不是文档,则操作错误。 见cursor.sort()。 maxTimeMSnumber 可选的。指定操作必须在其中完成的 time 限制(以毫秒为单位)。如果超出限制则引发错误。 upsertboolean 可选的。当true,findOneAndReplace()时: 如果没有文档与filter匹配,则从replacement参数插入文档。插入新文档后返回null,除非returnNewDocument是true。 用replacement文档替换与filter匹配的文档。 MongoDB 将_id字段添加到替换文档中,如果未在filter或replacement文档中指定。如果两者都存在_id,则值必须相等。 要避免多次 upsert,请确保query字段为唯一索引。 默认为false。 returnNewDocumentboolean 可选的。当true时,返回替换文档而不是原始文档。 默认为false。 collationdocument 可选的。 指定要用于操作的整理。 整理允许用户为 string 比较指定 language-specific 规则,例如字母和重音标记的规则。 排序规则选项具有以下语法: 排序规则:{ locale:, caseLevel:, caseFirst:, strength:, numericOrdering:, alternate:, maxVariable:, backwards :} 指定排序规则时,locale字段是必填字段;所有其他校对字段都是可选的。有关字段的说明,请参阅整理文件。 如果未指定排序规则但集合具有默认排序规则(请参阅db.createCollection()),则操作将使用为集合指定的排序规则。 如果没有为集合或操作指定排序规则,MongoDB 使用先前版本中用于 string 比较的简单二进制比较。 您无法为操作指定多个排序规则。对于 example,您不能为每个字段指定不同的排序规则,或者如果使用排序执行查找,则不能对查找使用一个排序规则,而对排序使用另一个排序规则。 version 3.4 中的新内容。
替换文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 db.user .findOneAndReplace ( { _id: ObjectId("5e7835476b6f69d428000002" ) }, { "name" : "wgf" , "age" : 25 , "address" : { "city" : "shenzhen" , "state" : "guangdong" , "zip" : "518111" } } "_id" : ObjectId ("5e7835476b6f69d428000002" ),"name" : "Bob" ,"age" : 25.0 ,"address" : {"city" : "Chicago" ,"state" : "IL" ,"zip" : "60606"
db.collection.findOneAndUpdate(filter, update, options)
根据 filter 和 sort 条件更新单个文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 db.collection .findOneAndUpdate (
参数 类型 描述 filterdocument 更新的选择标准。可以使用与find()方法相同的query selectors。 指定一个空文档{ }以更新集合中返回的第一个文档。 如果未指定,则默认为空文档。 从 MongoDB 3.6.14(和 3.4.23)开始,如果查询参数不是文档,则操作错误。 updatedocument 更新文件。 必须仅包含更新 operators。 projectiondocument 可选的。 return 的字段子集。 要_返回返回文档中的所有字段,请省略此参数。 从 MongoDB 3.6.14(和 3.4.23)开始,如果投影参数不是文档,则操作错误。 sortdocument 可选的。为filter匹配的文档指定排序 order。 从 MongoDB 3.6.14(和 3.4.23)开始,如果 sort 参数不是文档,则操作错误。 见cursor.sort()。 maxTimeMSnumber 可选的。指定操作必须在其中完成的 time 限制(以毫秒为单位)。如果超出限制则引发错误。 upsertboolean 可选的。当true,findOneAndUpdate()时: 如果没有文件匹配filter,则创建一个新文档。有关详细信息,请参阅upsert 行为。插入新文档后返回null,除非returnNewDocument是true。 更新与filter匹配的单个文档。 要避免多次 upsert,请确保filter字段为唯一索引。 默认为false。 returnNewDocumentboolean 可选的。当true时,返回更新的文档而不是原始文档。 默认为false。 collationdocument 可选的。 指定要用于操作的整理。 整理允许用户为 string 比较指定 language-specific 规则,例如字母和重音标记的规则。 排序规则选项具有以下语法: 排序规则:{ locale:, caseLevel:, caseFirst:, strength:, numericOrdering:, alternate:, maxVariable:, backwards :} 指定排序规则时,locale字段是必填字段;所有其他校对字段都是可选的。有关字段的说明,请参阅整理文件。 如果未指定排序规则但集合具有默认排序规则(请参阅db.createCollection()),则操作将使用为集合指定的排序规则。 如果没有为集合或操作指定排序规则,MongoDB 使用先前版本中用于 string 比较的简单二进制比较。 您无法为操作指定多个排序规则。对于 example,您不能为每个字段指定不同的排序规则,或者如果使用排序执行查找,则不能对查找使用一个排序规则,而对排序使用另一个排序规则。 version 3.4 中的新内容。 arrayFiltersarray 可选的。过滤器文档的 array,用于确定要在 array 字段上为更新操作修改哪些 array 元素。 在更新文档中,使用$ []过滤后的位置 operator 来定义标识符,然后在 array 过滤器文档中进行 reference。如果标识符未包含在更新文档中,则不能为标识符提供 array 过滤器文档。 注意 <identifier>必须以小写字母开头,并且只包含字母数字字符。 您可以在更新文档中多次包含相同的标识符;但是,对于更新文档中的每个不同标识符($[identifier]),您必须指定恰好一个 对应的 array 过滤器文档。也就是说,您不能为同一标识符指定多个 array 过滤器文档。对于 example,如果 update 语句包含标识符x(可能多次),则不能为arrayFilters指定以下内容,其中包含 2 个单独的x过滤器文档: // INVALID [ { “x.a”: { $gt: 85 } }, { “x.b”: { $gt: 80 } } ] 但是,您可以在同一标识符上指定复合条件单个过滤器文档,例如以下示例: // Example 1 [ { or: [{"x.a": {gt: 85}}, {“x.b”: {$gt: 80}}] } ] // Example 2 [ { and: [{"x.a": {gt: 85}}, {“x.b”: {$gt: 80}}] } ] // Example 3 [ { “x.a”: { $gt: 85 }, “x.b”: { $gt: 80 } } ] 例如,请参阅为 Array Update Operations 指定 arrayFilters。 version 3.6 中的新内容。
更新当个文档,并返回旧文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 db.user .findOneAndUpdate ( { name: "wgf" }, { $inc: { age: 1 } } "_id" : ObjectId ("5e7835476b6f69d428000002" ),"name" : "wgf" ,"age" : 25.0 ,"address" : {"city" : "shenzhen" ,"state" : "guangdong" ,"zip" : "518111"
测试数据
1 2 3 4 5 6 7 db.inventory .insertMany ( [item : "journal" , qty : 25 , size : { h : 14 , w : 21 , uom : "cm" }, status : "A" },item : "notebook" , qty : 50 , size : { h : 8.5 , w : 11 , uom : "in" }, status : "A" },item : "paper" , qty : 100 , size : { h : 8.5 , w : 11 , uom : "in" }, status : "D" },item : "planner" , qty : 75 , size : { h : 22.85 , w : 30 , uom : "cm" }, status : "D" },item : "postcard" , qty : 45 , size : { h : 10 , w : 15.25 , uom : "cm" }, status : "A" }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 db.inventory .find ( { size: { h: 14 , w: 21 , uom: "cm" } } "_id" : ObjectId ("646c8f4baf188546f987c4f9" ),"item" : "journal" ,"qty" : 25.0 ,"size" : {"h" : 14.0 ,"w" : 21.0 ,"uom" : "cm" "status" : "A"
对嵌套文档做 等值 查询时,使用查询筛选器文档 { <field>: <value> } ,其中 <value> 是要匹配的文档。
对嵌套文档做等值查询时,要求指定的 <value> 文档(包括字段和顺序)完全匹配,例如一下文档字段调换位置就不满足等值查询,查询不出结果
1 2 3 4 5 6 7 8 9 db.inventory .find (size : {w : 21 ,h : 14 ,uom : "cm"
要在嵌套文档中的字段上指定查询条件,请使用点符号 ( "field.nestedField" )
注意
当在查询语句中使用 ".",字段和嵌套文档字段必须在引号内
下面例子选择嵌套在 size 字段中的字段 uom 等于 "in" 的所有文档:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 db.inventory .find ( { "size.uom" : "in" } )"_id" : ObjectId ("646c8f4baf188546f987c4fa" ),"item" : "notebook" ,"qty" : 50.0 ,"size" : {"h" : 8.5 ,"w" : 11.0 ,"uom" : "in" "status" : "A" "_id" : ObjectId ("646c8f4baf188546f987c4fb" ),"item" : "paper" ,"qty" : 100.0 ,"size" : {"h" : 8.5 ,"w" : 11.0 ,"uom" : "in" "status" : "D"
测试数据
1 2 3 4 5 6 7 db.inventory .insertMany ( [item : "journal" , instock : [ { warehouse : "A" , qty : 5 }, { warehouse : "C" , qty : 15 } ] },item : "notebook" , instock : [ { warehouse : "C" , qty : 5 } ] },item : "paper" , instock : [ { warehouse : "A" , qty : 60 }, { warehouse : "B" , qty : 15 } ] },item : "planner" , instock : [ { warehouse : "A" , qty : 40 }, { warehouse : "B" , qty : 5 } ] },item : "postcard" , instock : [ { warehouse : "B" , qty : 15 }, { warehouse : "C" , qty : 35 } ] }
查询库存对象数组中,仓库为 “A”,库存为 5 的库存数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 db.inventory .find ( { instock: { warehouse: "A" , qty: 5 } } "_id" : ObjectId ("644628c7f6e1b1a011924011" ),"item" : "journal" ,"instock" : [ "warehouse" : "A" ,"qty" : 5.0 "warehouse" : "C" ,"qty" : 15.0
当对整个嵌套文档使用等值匹配的时候是要求精确匹配指定文档,包括字段顺序。比如,下面的语句并没有查询到 inventory 集合中的任何文档:
1 db.inventory.find( { "instock" : { qty: 5 , warehouse: "A" } } )
如果你不知道嵌套在数组中的文档的索引位置,请将数组字段的名称与一个点 ( . ) 和嵌套文档中的字段名称连接起来,这样就会返回符合文档数组条件的整个文档
注意
嵌套文档数组中,只要有一个嵌套文档满足条件,就会返回整个文档
当在查询语句中使用 ".",字段和嵌套文档字段必须在引号内
查询嵌套文档数组 instock 库存大于等于40的文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 db.inventory .find ("instock.qty" : {$gte : 40 "_id" : ObjectId ("644628c7f6e1b1a011924013" ),"item" : "paper" ,"instock" : [ "warehouse" : "A" ,"qty" : 60.0 "warehouse" : "B" ,"qty" : 15.0 "_id" : ObjectId ("644628c7f6e1b1a011924014" ),"item" : "planner" ,"instock" : [ "warehouse" : "A" ,"qty" : 40.0 "warehouse" : "B" ,"qty" : 5.0
查询所有文档中,instock 数组的第一个元素的 qty 小于等于5的文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 db.inventory .find ("instock.0.qty" : {$lte : 5 "_id" : ObjectId ("644628c7f6e1b1a011924011" ),"item" : "journal" ,"instock" : [ "warehouse" : "A" ,"qty" : 5.0 "warehouse" : "C" ,"qty" : 15.0 "_id" : ObjectId ("644628c7f6e1b1a011924012" ),"item" : "notebook" ,"instock" : [ "warehouse" : "C" ,"qty" : 5.0
单个嵌套文档中的字段满足多个查询条件
$elemMatch 操作符为数组中的嵌套文档指定多个查询条件,最少一个嵌套文档同时满足所有的查询条件
查询数组中的嵌套文档,至少有一个嵌套文档满足 qty 小于等于5,并且 warehouse 为A的文档数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 db.inventory .find ( { instock: { $elemMatch: { qty: { $lte: 5 }, warehouse: "A" } } } "_id" : ObjectId ("644628c7f6e1b1a011924011" ),"item" : "journal" ,"instock" : [ "warehouse" : "A" ,"qty" : 5.0 "warehouse" : "C" ,"qty" : 15.0
多个元素联合满足查询条件
如果数组字段上的联合查询条件没有使用 $elemMatch 运算符,查询返回数组字段中多个元素联合满足所有的查询条件的所有文档
换言之,如果不使用 $elemMatch 运算符,那么对数组文档的查询的多个条件是 or 关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 db.inventory .find ( { "instock.qty" : 5 , "instock.warehouse" : "A" } "_id" : ObjectId ("644628c7f6e1b1a011924011" ),"item" : "journal" ,"instock" : [ "warehouse" : "A" ,"qty" : 5.0 "warehouse" : "C" ,"qty" : 15.0 "_id" : ObjectId ("644628c7f6e1b1a011924014" ),"item" : "planner" ,"instock" : [ "warehouse" : "A" ,"qty" : 40.0 "warehouse" : "B" ,"qty" : 5.0
在这个查询中,只要数组中的多个文档组合起来,满足所有查询条件即可
测试数据
1 2 3 4 5 6 7 db.inventory .insertMany ([item : "journal" , qty : 25 , tags : ["blank" , "red" ], dim_cm : [ 14 , 21 ] },item : "notebook" , qty : 50 , tags : ["red" , "blank" ], dim_cm : [ 14 , 21 ] },item : "paper" , qty : 100 , tags : ["red" , "blank" , "plain" ], dim_cm : [ 14 , 21 ] },item : "planner" , qty : 75 , tags : ["blank" , "red" ], dim_cm : [ 22.85 , 30 ] },item : "postcard" , qty : 45 , tags : ["blue" ], dim_cm : [ 10 , 15.25 ] }
数组字段做等值查询的时候,使用查询文档 { <field>: <value> } ,其中 <value> 是要精确匹配的数组,包括元素的顺序
下面的查询返回 inventory 集合中数组字段 tags 值是只包含两个元素 "red" 和 "blank" 并且按照指定顺序的数组的所有文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 db.inventory .find ( { "tags" : ["red" , "blank" ] } "_id" : ObjectId ("644646dcf6e1b1a011924017" ),"item" : "notebook" ,"qty" : 50.0 ,"tags" : [ "red" , "blank" "dim_cm" : [ 14.0 , 21.0
如果想检索数组中包含 red和 blank两个元素并且不在乎元素顺序或者数组中是否有其它元素 。可以使用 $all
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 db.inventory .find (tags : {$all : ["red" , "blank" ]"_id" : ObjectId ("644646dcf6e1b1a011924016" ),"item" : "journal" ,"qty" : 25.0 ,"tags" : [ "blank" , "red" "dim_cm" : [ 14.0 , 21.0 "_id" : ObjectId ("644646dcf6e1b1a011924017" ),"item" : "notebook" ,"qty" : 50.0 ,"tags" : [ "red" , "blank" "dim_cm" : [ 14.0 , 21.0 "_id" : ObjectId ("644646dcf6e1b1a011924018" ),"item" : "paper" ,"qty" : 100.0 ,"tags" : [ "red" , "blank" , "plain" "dim_cm" : [ 14.0 , 21.0 "_id" : ObjectId ("644646dcf6e1b1a011924019" ),"item" : "planner" ,"qty" : 75.0 ,"tags" : [ "blank" , "red" "dim_cm" : [ 22.85 , 30.0
要查询数组字段是否包含至少一个具有指定值的元素,请使用过滤器 { <field>: <value> } ,其中 <value> 是元素值
下面的查询是对 tags 数组元素进行查询,要求数组至少包含一个 red 元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 db.inventory .find (tags : "red" "_id" : ObjectId ("644646dcf6e1b1a011924016" ),"item" : "journal" ,"qty" : 25.0 ,"tags" : [ "blank" , "red" "dim_cm" : [ 14.0 , 21.0 "_id" : ObjectId ("644646dcf6e1b1a011924017" ),"item" : "notebook" ,"qty" : 50.0 ,"tags" : [ "red" , "blank" "dim_cm" : [ 14.0 , 21.0 "_id" : ObjectId ("644646dcf6e1b1a011924018" ),"item" : "paper" ,"qty" : 100.0 ,"tags" : [ "red" , "blank" , "plain" "dim_cm" : [ 14.0 , 21.0 "_id" : ObjectId ("644646dcf6e1b1a011924019" ),"item" : "planner" ,"qty" : 75.0 ,"tags" : [ "blank" , "red" "dim_cm" : [ 22.85 , 30.0
在对数组元素进行查询时,可以使用 查询操作符
下面的查询是查询数组 dim_cm 包含至少一个值大于 25 的元素的所有文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 db.inventory .find ( { dim_cm: { $gt: 25 } } "_id" : ObjectId ("644646dcf6e1b1a011924019" ),"item" : "planner" ,"qty" : 75.0 ,"tags" : [ "blank" , "red" "dim_cm" : [ 22.85 , 30.0
使用多条件查询数组中的元素时,可以在查询语句中指定单个数组元素满足所有查询条件还是多个数组中的元素联合满足所有条件
使用多条件查询数组中的元素
下面对 dim_cm 数组的查询,一个元素可以满足大于 15 的条件,而另一个元素可以满足小于 20 的条件,或者一个元素可以 同时满足 这两个条件,条件之间是 OR 关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 db.inventory .find (dim_cm : {$gt : 15 ,$lt : 20 "_id" : ObjectId ("644646dcf6e1b1a011924016" ),"item" : "journal" ,"qty" : 25.0 ,"tags" : [ "blank" , "red" "dim_cm" : [ 14.0 , 21.0 "_id" : ObjectId ("644646dcf6e1b1a011924017" ),"item" : "notebook" ,"qty" : 50.0 ,"tags" : [ "red" , "blank" "dim_cm" : [ 14.0 , 21.0 "_id" : ObjectId ("644646dcf6e1b1a011924018" ),"item" : "paper" ,"qty" : 100.0 ,"tags" : [ "red" , "blank" , "plain" "dim_cm" : [ 14.0 , 21.0 "_id" : ObjectId ("644646dcf6e1b1a01192401a" ),"item" : "postcard" ,"qty" : 45.0 ,"tags" : [ "blue" "dim_cm" : [ 10.0 , 15.25
数组中的一个元素同时满足多个查询条件
使用 $elemMatch
下面的查询返回数组字段 dim_cm 中最少一个元素同时满足大于 22 和 小于 30,条件之间是 AND 关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 db.inventory .find (dim_cm : {$elemMatch : {$gt : 22 ,$lt : 30 "_id" : ObjectId ("644646dcf6e1b1a011924019" ),"item" : "planner" ,"qty" : 75.0 ,"tags" : [ "blank" , "red" "dim_cm" : [ 22.85 , 30.0
使用 点号 ,可以为数组中指定下标的元素指定查询条件,数组下标从0开始
下面的查询返回数组字段 dim_cm 中第二个元素大于 25 的所有文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 db.inventory .find ("dim_cm.1" : {$gt : 25 "_id" : ObjectId ("644646dcf6e1b1a011924019" ),"item" : "planner" ,"qty" : 75.0 ,"tags" : [ "blank" , "red" "dim_cm" : [ 22.85 , 30.0
使用 $size
下面的查询返回数组字段 tags 中有三个元素的所有文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 db.inventory .find ("tags" : {$size : 3 "_id" : ObjectId ("644646dcf6e1b1a011924018" ),"item" : "paper" ,"qty" : 100.0 ,"tags" : [ "red" , "blank" , "plain" "dim_cm" : [ 14.0 , 21.0
默认情况下,MongoDB的查询语句返回匹配到文档的所有字段,为了限制MongoDB返回给应用的数据,可以通过 projection (投影文档)来指定或限制返回的字段
测试数据
1 2 3 4 5 6 7 db.inventory .insertMany ( [item : "journal" , status : "A" , size : { h : 14 , w : 21 , uom : "cm" }, instock : [ { warehouse : "A" , qty : 5 } ] },item : "notebook" , status : "A" , size : { h : 8.5 , w : 11 , uom : "in" }, instock : [ { warehouse : "C" , qty : 5 } ] },item : "paper" , status : "D" , size : { h : 8.5 , w : 11 , uom : "in" }, instock : [ { warehouse : "A" , qty : 60 } ] },item : "planner" , status : "D" , size : { h : 22.85 , w : 30 , uom : "cm" }, instock : [ { warehouse : "A" , qty : 40 } ] },item : "postcard" , status : "A" , size : { h : 10 , w : 15.25 , uom : "cm" }, instock : [ { warehouse : "B" , qty : 15 }, { warehouse : "C" , qty : 35 } ] }
返回指定的字段
通过 projection 指定或排除返回字段后,_id 默认是返回的。如果不需要 _id 字段,需要显式指定
1或true:表示要返回的字段 0或false:表示不返回的字段 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 db.inventory .find (status : "A" item : 1 ,status : 1 "_id" : ObjectId ("64466a70f6e1b1a01192401b" ),"item" : "journal" ,"status" : "A" "_id" : ObjectId ("64466a70f6e1b1a01192401c" ),"item" : "notebook" ,"status" : "A" "_id" : ObjectId ("64466a70f6e1b1a01192401f" ),"item" : "postcard" ,"status" : "A"
上面的操作等价于SQL的
1 SELECT _id, item, status from inventory WHERE status = "A"
去除_id字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 db.getCollection ('inventory' ).find (status : "A" item : 1 ,status : 1 ,_id : 0 "item" : "journal" ,"status" : "A" "item" : "notebook" ,"status" : "A" "item" : "postcard" ,"status" : "A"
注意
除 _id 字段外,不能在映射文档中同时使用 包含 和 去除 语句
去除指定字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 db.getCollection ('inventory' ).find ("size.h" : 10 item : 0 ,instock : 0 "_id" : ObjectId ("64466a70f6e1b1a01192401f" ),"status" : "A" ,"size" : {"h" : 10.0 ,"w" : 15.25 ,"uom" : "cm"
返回嵌套文档中的指定字段
通过 点号 引用嵌套文档字段并且在映射文档中将该字段设置为1来实现返回嵌套文档中的指定字段
1 2 3 4 5 6 7 8 9 10 db.inventory .find (status : "A" item : 1 ,status : 1 ,"size.uom" : 1
去除嵌套文档中的指定字段
通过 点号 引用嵌套文档字段并且在映射文档中将该字段设置为0来实现去除嵌套文档中的指定字段
1 2 3 4 5 6 7 8 db.inventory .find (status : "A" "size.uom" : 0
映射数组中的嵌套文档的指定字段
通过使用 点号 来映射数组中嵌套文档的指定字段
1 2 3 4 5 6 7 8 9 10 db.inventory .find (status : "A" item : 1 ,status : 1 ,"instock.qty" : 1
映射返回数组中指定的数组元素
对于数组字段,MongoDB 提供了以下用于操作数组的映射运算符: $elemMatch$slice$.
$elemMatch
在嵌套文档数组中,这个对象数组仅返回与 $elemMatch 匹配的 第一个元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 db.inventory .find (item : "postcard" instock : {$elemMatch : {qty : 35 "_id" : ObjectId ("64466a70f6e1b1a01192401f" ),"instock" : [ "warehouse" : "C" ,"qty" : 35.0
$slice
1 2 3 4 db.collection .find ($slice : <number> } }
number >= 0:返回这个数组的 n 个元素 number < 0:返回这个数组的最后一个元素 1 2 3 4 db.collection .find ($slice : [ <number>, <number> ] } }
第一个参数类似 offset
第二个参数类似 limit
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 db.inventory .find (status : "A" ,"instock.qty" : 35 item : 1 ,status : 1 ,instock : {$slice : -1 "_id" : ObjectId ("64466a70f6e1b1a01192401f" ),"item" : "postcard" ,"status" : "A" ,"instock" : [ "warehouse" : "C" ,"qty" : 35.0
$
$ 运算符限制数组返回的内容以返回与数组中的查询条件匹配的 第一个元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 db.inventory .find (instock : {$elemMatch : {"C" ,qty : 35.0 "instock.$" : 1 "_id" : ObjectId ("64466a70f6e1b1a01192401f" ),"instock" : [ "warehouse" : "C" ,"qty" : 35.0
在MongoDB中不同的查询操作符对于 null 值处理方式不同
测试数据
1 2 3 4 db.inventory .insertMany ([_id : 1 , item : null },_id : 2 }
等值匹配
当使用 { item : null } 作为查询条件的时候,返回的是 item 字段值为 null 的文档或者 不包含item 字段的文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 db.getCollection ('inventory' ).find (item : null "_id" : 1.0 ,"item" : null "_id" : 2.0
类型检查
当使用 {item:{$type:10}} 作为查询条件的时候,仅返回 item 字段值为 null 的文档。item 字段的值是 BSON Type Null(type number 10)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 db.getCollection ('inventory' ).find (item : {$type : 10 "_id" : 1.0 ,"item" : null
存在检查
当使用 {item:{$exists:false}} 作为查询条件的时候,返回不包含 item 字段的文档
1 2 3 4 5 6 7 8 9 10 11 12 db.getCollection ('inventory' ).find ( { item: { $exists: false } } "_id" : 2.0
db.collection.find() 方法返回一个游标。要访问文档,您需要迭代游标。 但是,在mongo shell中,如果未使用 var 关键字将返回的游标分配给变量,则该游标将自动迭代多达20次,以打印结果中的前20个文档 (查询默认返回前20个文档)
手动迭代游标
在 mongo Shellvar 关键字将find()
您可以在shell程序中调用cursor变量以进行多达20次迭代并打印匹配的文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 var myCursor = db.user .find ({ age : {$gt : 30 } });"_id" : ObjectId ("5e7835496b6f69d428000004" ),"name" : "Dave" ,"age" : 35 ,"address" : {"city" : "San Francisco" ,"state" : "CA" ,"zip" : "94107"
您还可以使用游标方法 next()printjson()辅助方法替换print(tojson())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 var myCursor = db.user .find ({ age : {$gt : 30 } });while (myCursor.hasNext ()) {printjson (myCursor.next ())"_id" : ObjectId ("5e7835496b6f69d428000004" ),"name" : "Dave" ,"age" : 35 ,"address" : {"city" : "San Francisco" ,"state" : "CA" ,"zip" : "94107"
您可以使用游标方法 forEach()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 var myCursor = db.user .find ({ age : {$gt : 30 } });forEach (printjson);"_id" : ObjectId ("5e7835496b6f69d428000004" ),"name" : "Dave" ,"age" : 35 ,"address" : {"city" : "San Francisco" ,"state" : "CA" ,"zip" : "94107"
迭代器索引
toArray()RAM 中; toArray()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 var myCursor = db.user .find ({ age : {$gt : 30 } });var documentArray = myCursor.toArray ();var document = documentArray[0 ];printjson (document );"_id" : ObjectId ("5e7835496b6f69d428000004" ),"name" : "Dave" ,"age" : 35 ,"address" : {"city" : "San Francisco" ,"state" : "CA" ,"zip" : "94107"
此外,一些驱动程序通过使用光标上的索引(即 cursor[index] )提供对文档的访问。这是先调用 toArray() 方法然后在结果数组上使用索引的快捷方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var myCursor = db.user .find ({ age : {$gt : 30 } });var document = myCursor[0 ];printjson (document );"_id" : ObjectId ("5e7835496b6f69d428000004" ),"name" : "Dave" ,"age" : 35 ,"address" : {"city" : "San Francisco" ,"state" : "CA" ,"zip" : "94107"
更新方法
更新参数
附加方法
测试数据
1 2 3 4 5 6 7 8 9 10 11 12 db.inventory .insertMany ( [item : "canvas" , qty : 100 , size : { h : 28 , w : 35.5 , uom : "cm" }, status : "A" },item : "journal" , qty : 25 , size : { h : 14 , w : 21 , uom : "cm" }, status : "A" },item : "mat" , qty : 85 , size : { h : 27.9 , w : 35.5 , uom : "cm" }, status : "A" },item : "mousepad" , qty : 25 , size : { h : 19 , w : 22.85 , uom : "cm" }, status : "P" },item : "notebook" , qty : 50 , size : { h : 8.5 , w : 11 , uom : "in" }, status : "P" },item : "paper" , qty : 100 , size : { h : 8.5 , w : 11 , uom : "in" }, status : "D" },item : "planner" , qty : 75 , size : { h : 22.85 , w : 30 , uom : "cm" }, status : "D" },item : "postcard" , qty : 45 , size : { h : 10 , w : 15.25 , uom : "cm" }, status : "A" },item : "sketchbook" , qty : 80 , size : { h : 14 , w : 21 , uom : "cm" }, status : "A" },item : "sketch pad" , qty : 95 , size : { h : 22.85 , w : 30.5 , uom : "cm" }, status : "A" }
更新集合中的文档
为了更新文档,MongoDB 提供了 更新运算符 ,例如 $set
要使用更新运算符,请将以下形式的更新文档传递给更新方法:
1 2 3 4 5 {
如果字段不存在,则某些更新操作符 (例如 $set
字段
数组
修饰符
名称 描述 $each修改$push和$addToSet运算符以附加多个项以进行数组更新。 $position修改$push运算符以指定要添加元素的数组中的位置。 $slice修改$push运算符以限制更新数组的大小。 $sort修改$push运算符以对存储在数组中的文档重新排序。
按位运算
名称 描述 $bit执行按位AND,OR和XOR整数值的更新。
查找与过滤器匹配的第一个文档,并应用指定的更新修改
语法
1 2 3 4 5 6 7 8 9 10 db.collection.updateOne(, , { : <boolean>, : <document>, : <document>, : [ <filterdocument1>, ... ] }
使用例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 db.inventory .updateOne (item : "paper" $set : {"size.uom" : "cm" ,status : "P" $currentDate : {lastModified : true "acknowledged" : true ,"matchedCount" : 1.0 ,"modifiedCount" : 1.0 "_id" : ObjectId ("64493abb802c33de71430e81" ),"item" : "paper" ,"qty" : 100.0 ,"size" : {"h" : 8.5 ,"w" : 11.0 ,"uom" : "cm" "status" : "P" ,"lastModified" : ISODate ("2023-04-26T14:58:14.173Z" )
使用 $setsize.uom 字段的值更新为 "cm" 并将 status 字段的值更新为 "P"
使用 $currentDatelastModified 字段的值更新为当前日期。如果 lastModified 字段不存在, $currentDate
更新与集合的指定过滤器匹配的所有文档
语法
1 2 3 4 5 6 7 8 9 10 11 db.collection.updateMany(, , { : <boolean>, : <document>, : <document>, : [ <filterdocument1>, ... ] , : <document|string> }
使用例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 db.inventory .updateMany (qty : {$lt : 50 $set : {"size.uom" : "in" ,status : "P" $currentDate : {lastModified : true
更新所有 qty 小于5的文档
使用 $setsize.uom 字段的值更新为 "in",将状态字段的值更新为 "P"
使用 $currentDatelastModified 字段的值更新为当前日期。如果 lastModified 字段不存在, $currentDate
db.collection.replaceOne(filter, replacement, options) 根据过滤器替换集合中的单个文档,替换 _id 字段以外的文档的全部内容
语法
1 2 3 4 5 6 7 8 9 10 db.collection.replaceOne(, , { : <boolean>, : <document>, : <document>, : <document|string> }
使用例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 db.inventory .replaceOne (item : "paper" item : "paper" ,instock : [warehouse : "A" ,qty : 60 warehouse : "B" ,qty : 40 "acknowledged" : true ,"matchedCount" : 1.0 ,"modifiedCount" : 1.0 "_id" : ObjectId ("64493abb802c33de71430e81" ),"item" : "paper" ,"instock" : [ "warehouse" : "A" ,"qty" : 60.0 "warehouse" : "B" ,"qty" : 40.0
原子性
MongoDB中的所有写操作都是 单个文档级别上的原子操作。有关MongoDB和原子性的更多信息,请参见原子性和事务
_id 字段
设置后,无法更新 _id 字段的值,也无法将现有文档替换为具有不同 _id 字段值的替换文档
字段顺序
对于写操作,MongoDB 保留文档字段的顺序,但以下情况除外:
_id 字段始终是文档中的第一个字段包含 rename 修改或新增
如果updateOne()updateMany()replaceOne()upsert:true,并且没有文档与指定的过滤器匹配,则该操作将创建一个新文档并将其插入。 如果存在匹配的文档,则该操作将修改或替换一个或多个匹配的文档
从 MongoDB 4.2 开始,可以使用聚合管道进行更新操作,通过更新操作,聚合管道可以包括以下阶段
使用聚合管道允许使用表达性更强的update语句,比如根据当前字段值表示条件更新,或者使用另一个字段的值更新一个字段
使用聚合表达式变量
测试数据
1 2 3 4 5 db.students .insertMany ( [_id : 1 , test1 : 95 , test2 : 92 , test3 : 90 , modified : new Date ("01/05/2020" ) },_id : 2 , test1 : 98 , test2 : 100 , test3 : 102 , modified : new Date ("01/05/2020" ) },_id : 3 , test1 : 95 , test2 : 110 , modified : new Date ("01/04/2020" ) }
聚合表达式中的变量
以下 db.collection.updateOne() 操作使用聚合管道通过 _id: 3 更新文档
1 2 3 4 5 6 7 8 9 10 11 12 13 db.students .updateOne (_id : 3 $set : {test3 : 98 ,modified : "$$NOW"
具体来说,管道由一个 $set 阶段组成,该阶段将 test3 字段(并将其值设置为 98 )添加到文档并将 modified 字段设置为当前日期时间。该操作将聚合变量 NOW$$ 为前缀并用引号引起来
测试数据
1 2 3 4 db.students2 .insertMany ( ["_id" : 1 , quiz1 : 8 , test2 : 100 , quiz2 : 9 , modified : new Date ("01/05/2020" ) },"_id" : 2 , quiz2 : 5 , test1 : 80 , test2 : 89 , modified : new Date ("01/05/2020" ) },
以下 db.collection.updateMany() 操作使用聚合管道来标准化文档的字段(即集合中的文档应具有相同的字段)并更新 modified 字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 db.students2 .updateMany ($replaceRoot : {newRoot : {$mergeObjects : [quiz1 : 0 ,quiz2 : 0 ,test1 : 0 ,test2 : 0 "$$ROOT" $set : {modified : "$$NOW" "_id" : 1.0 ,"quiz1" : 8.0 ,"quiz2" : 9.0 ,"test1" : 0.0 ,"test2" : 100.0 ,"modified" : ISODate ("2023-04-27T07:46:36.526Z" )"_id" : 2.0 ,"quiz1" : 0.0 ,"quiz2" : 5.0 ,"test1" : 80.0 ,"test2" : 89.0 ,"modified" : ISODate ("2023-04-27T07:46:36.526Z" )
$replaceRoot$mergeObjectsquiz1、quiz2、test1、test2 字段设置默认值。 聚合变量 ROOT$$ 为前缀并用引号引起来。当前文档字段将覆盖默认值$setNOW$$ 为前缀并用引号引起来)最终实现的效果是 $mergeObjects 将符合条件的多个文档重新进行字段规划,给出字段和默认值。然后 $replaceRoot 对当前文档进行替换,如果当前文档已存在字段则跳过,负责插入新的字段和默认值
测试数据
1 2 3 4 5 db.students3 .insertMany ( ["_id" : 1 , "tests" : [ 95 , 92 , 90 ], "modified" : ISODate ("2019-01-01T00:00:00Z" ) },"_id" : 2 , "tests" : [ 94 , 88 , 90 ], "modified" : ISODate ("2019-01-01T00:00:00Z" ) },"_id" : 3 , "tests" : [ 70 , 75 , 82 ], "modified" : ISODate ("2019-01-01T00:00:00Z" ) }
以下操作使用聚合管道计算平均值,然后用平均值进行评级
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 db.students3 .updateMany ($set : { average : { $trunc : [{ $avg : "$tests" }, 0 ] }, modified : "$$NOW" } },$set : {grade : {$switch : {branches : [case : { $gte : ["$average" , 90 ] }, then : "A" },case : { $gte : ["$average" , 80 ] }, then : "B" },case : { $gte : ["$average" , 70 ] }, then : "C" },case : { $gte : ["$average" , 60 ] }, then : "D" }default : "F" "_id" : 1.0 ,"tests" : [ 95.0 , 92.0 , 90.0 "modified" : ISODate ("2023-04-27T08:44:41.551Z" ),"average" : 92.0 ,"grade" : "A" "_id" : 2.0 ,"tests" : [ 94.0 , 88.0 , 90.0 "modified" : ISODate ("2023-04-27T08:44:41.551Z" ),"average" : 90.0 ,"grade" : "A" "_id" : 3.0 ,"tests" : [ 70.0 , 75.0 , 82.0 "modified" : ISODate ("2023-04-27T08:44:41.551Z" ),"average" : 75.0 ,"grade" : "C"
先使用管道计算出平均值, $truncNOW $set$switchaverage 的基础上添加 grade 字段测试数据
1 2 3 4 5 db.students4 .insertMany (["_id" : 1 , "quizzes" : [ 4 , 6 , 7 ] },"_id" : 2 , "quizzes" : [ 5 ] },"_id" : 3 , "quizzes" : [ 10 , 10 , 10 ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 db.students4 .updateOne ( _id : 2 },$set : { quizzes : {$concatArrays : [ "$quizzes" , 8 , 6 ] "_id" : 1.0 ,"quizzes" : [ 4.0 , 6.0 , 7.0 "_id" : 2.0 ,"quizzes" : [ 5.0 , 8.0 , 6.0 "_id" : 3.0 ,"quizzes" : [ 10.0 , 10.0 , 10.0
测试数据
1 2 3 4 5 db.temperatures .insertMany (["_id" : 1 , "date" : ISODate ("2019-06-23" ), "tempsC" : [ 4 , 12 , 17 ] },"_id" : 2 , "date" : ISODate ("2019-07-07" ), "tempsC" : [ 14 , 24 , 11 ] },"_id" : 3 , "date" : ISODate ("2019-10-30" ), "tempsC" : [ 18 , 6 , 8 ] }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 db.temperatures .updateMany ( { },$addFields : { "tempsF" : { $map : { input : "$tempsC" ,as : "celsius" , in : { $add : [ { $multiply : ["$$celsius" , 9 /5 ] }, 32 ] } "_id" : 1.0 ,"date" : ISODate ("2019-06-23T00:00:00.000Z" ),"tempsC" : [ 4.0 , 12.0 , 17.0 "tempsF" : [ 39.2 , 53.6 , 62.6 "_id" : 2.0 ,"date" : ISODate ("2019-07-07T00:00:00.000Z" ),"tempsC" : [ 14.0 , 24.0 , 11.0 "tempsF" : [ 57.2 , 75.2 , 51.8 "_id" : 3.0 ,"date" : ISODate ("2019-10-30T00:00:00.000Z" ),"tempsC" : [ 18.0 , 6.0 , 8.0 "tempsF" : [ 64.4 , 42.8 , 46.4
具体来说,该管道由一个 $addFieldstempsF 。为了将 tempsC 数组中的每个摄氏温度转换为华氏温度,该阶段使用 $map$add$multiply
删除方法
其他方法
以下方法也可以从集合中删除文档:
要从集合中删除所有文档,请将空 过滤器 文档 {} 传递给 db.collection.deleteMany()
1 db.inventory .deleteMany ({})
1 2 3 4 5 db.inventory .deleteMany (status : "A"
删除 status 为 A 的所有文档
要删除最多一个与指定过滤器匹配的文档(即使多个文档可以与指定过滤器匹配),请使用 db.collection.deleteOne()
1 2 3 4 5 db.inventory .deleteOne (status : "D"
索引
即使从集合中删除所有文档,删除操作也不会删除索引
原子性
MongoDB 中的所有写操作在单个文档级别上都是原子的。有关 MongoDB 和原子性的更多信息,请参阅 原子性和事务
写确认
对于写入问题,您可以指定从MongoDB请求的写入操作的确认级别。 有关详细信息,请参见 写确认
MongoDB为客户端提供了批量写操作的能力。 批量写入操作会影响 单个集合。 MongoDB允许应用程序确定批量写入操作所需的可接受的确认级别
db.collection.bulkWrite()插入,更新和 删除 操作的能力。对于批量插入而言,MongoDB也支持 db.collection.insertMany()
有序 VS 无序操作
批量写操作可以是有序的,也可以无序的
使用操作的有序列表,MongoDB 串行 地执行操作。 如果在某个单独的写操作的处理过程中发生错误,MongoDB将直接返回而不再继续处理列表中任何剩余的写操作 。参考 有序的批量写入 使用无序的操作列表,MongoDB可以 并行 地执行操作,但是不能保证此行为。 如果某个单独的写操作的处理过程中发生错误,MongoDB将继续处理列表中剩余的写操作 。参考 无序的批量写入 在分片集合上执行有序的批量写操作通常比执行无序批量写操作要慢。这是因为对于有序列表而言,每个操作都必须等待上一个操作完成后才能执行
默认情况下,bulkWrite()有序 的写入。 要指定 无序 的写入,请在选项文档中设置 ordered:false
支持的操作
用法
测试数据
1 2 3 4 5 db.pizzas .insertMany ( [_id : 0 , type : "pepperoni" , size : "small" , price : 4 },_id : 1 , type : "cheese" , size : "medium" , price : 7 },_id : 2 , type : "vegan" , size : "large" , price : 8 }
使用 insertOne 添加两个文档 使用 updateOne 更新文档 使用 deleteOne 删除文档 使用 replaceOne 替换文档 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 try {pizzas .bulkWrite ( [insertOne : { document : { _id : 3 , type : "beef" , size : "medium" , price : 6 } } },insertOne : { document : { _id : 4 , type : "sausage" , size : "large" , price : 10 } } },updateOne : {filter : { type : "cheese" },update : { $set : { price : 8 } }deleteOne : { filter : { type : "pepperoni" } } },replaceOne : {filter : { type : "vegan" },replacement : { type : "tofu" , size : "small" , price : 4 }catch ( error ) {print ( error )"acknowledged" : true ,"deletedCount" : 1.0 ,"insertedCount" : 2.0 ,"matchedCount" : 2.0 ,"upsertedCount" : 0.0 ,"insertedIds" : {"0" : 3.0 ,"1" : 4.0 "upsertedIds" : {}
批量插入分片集合的策略
大批量插入操作,包括初始数据插入或例行数据导入,会影响分片集群的性能。对于批量插入,请考虑以下策略:
对分片集合进行预拆分
如果分片集合为空,则该集合只有一个存储在单个分片上的初始数据块,MongoDB必须花一些时间来接收数据,创建拆分并将拆分的块分发到其他分片上。为了避免这种性能开销,您可以对分片集合进行预拆分,请参考 分片集群中的数据块拆分 中的描述
对mongos的无序写入
要提高对分片集群的写入性能,请使用 bulkWrite() 并将可选参数 ordered 设置为 false 。 mongos 可以尝试同时将写入发送到多个分片。对于空集合,首先按照 分片集群中的数据块拆分 中的描述预先拆分集合
避免单调插入带来的瓶颈
如果您的分片键在插入过程中是单调递增的,那么所有插入的数据都会插入到该分片集合的最后一个数据块中,也就是说会落到某单个分片上。因此,集群的插入能力将永远不会超过该单个分片的插入性能(木桶的短板原理)
如果插入量大于单个分片可以处理的数据量,并且无法避免单调递增的分片键,那么可以考虑对应用程序进行如下修改:
反转分片键的二进制位。这样可以保留信息并避免将插入顺序与增加的值序列相关联 交换第一个和最后16比特来实现“随机”插入 mongo 分片默认选择范围分片,单调递增的分片键会让数据集中插入到某个分片中
对于自我管理(非 Atlas)部署,MongoDB 的文本搜索功能支持执行字符串内容文本搜索的查询操作。为了执行文本搜索,MongoDB 使用 文本索引 和 $text
执行文本搜索
此示例演示如何构建文本索引并在指定文本段的情况下使用它来查找咖啡店
测试数据
1 2 3 4 5 6 7 8 9 db.stores .insertMany (_id : 1 , name : "Java Hut" , description : "Coffee and cakes" },_id : 2 , name : "Burger Buns" , description : "Gourmet hamburgers" },_id : 3 , name : "Coffee Shop" , description : "Just coffee" },_id : 4 , name : "Clothes Clothes Clothes" , description : "Discount clothing" },_id : 5 , name : "Java Shopping" , description : "Indonesian goods" }
创建文本索引
1 2 3 4 5 6 db.stores .createIndex (name : "text" ,description : "text"
准确的短语搜索
可以通过用双引号将它们括起来来搜索确切的短语。如果 $search 字符串包含短语和单个术语,则文本搜索将仅匹配包含该短语的文档
例如,以下将查找包含 coffee shop 的所有文档:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 db.stores .find ($text : {$search : "\"coffee shop\"" "_id" : 3.0 ,"name" : "Coffee Shop" ,"description" : "Just coffee"
全文搜索例子
搜索单个单词 匹配任何搜索词 搜索短语 排除包含的术语 搜索不同的语言 GeoJSON 地理位置数据类型
TODO
可重试写入允许MongoDB驱动程序在遇到网络错误或在复制集或分片群集中找不到正常的主节点时自动重试特定的写操作一次
前提条件
需要集群部署支持
可重试写入需要副本集或分片集群,并且不支持独立实例
支持的存储引擎
可重试写入需要支持文档级锁定的存储引擎,例如 WiredTiger 或 内存 存储引擎
3.6+版本程序驱动
客户端需要为 MongoDB 3.6 或更高版本更新 MongoDB 驱动程序
可重试写入和多文档事务
事务 提交和 中止 操作是可重试的写操作。如果提交操作或中止操作遇到错误,MongoDB 驱动程序将重试一次操作,而不管 retryWrites 是否设置为 false 无论 retryWrites 的值如何,事务内的写操作都不可单独重试 启用可重试写入
官方的MongoDB 3.6和4.0兼容驱动程序需要在连接字符串中包含 retryWrites=true
MongoDB 4.2 及更高版本兼容的驱动程序 默认启用 可重试写入。较早的驱动程序需要 retryWrites=true 选项。在使用与 MongoDB 4.2 及更高版本兼容的驱动程序的应用程序中,可以省略 retryWrites=true 选项
要禁用可重试写入,使用与 MongoDB 4.2 及更高版本兼容的驱动程序的应用程序必须在连接字符串中包含 retryWrites=false
Mongo shell
mongosh 中默认启用可重试写入。要禁用可重试写入,请使用 --retryWrites=false 命令行选项:
1 mongosh --retryWrites=false
可重试的写操作
当发出已确认的写关注时,可以重试以下写操作; 例如 Write Concern 不能为 {w:0}
事务内的写操作不可单独重试
可重试写入行为
可重试读取允许MongoDB驱动程序在遇到某些 网络 或 服务器错误 时,可以一次自动重试某些读取操作
前提条件
启用可重试读取
MongoDB Server 4.2 及更高版本兼容的官方 MongoDB 驱动程序 默认启用 可重试读取。要显式禁用可重试读取,请在部署的连接字符串中指定 retryReads=false
可重试读取操作
方法 内容描述 Collection.aggregateCollection.countCollection.countDocumentsCollection.distinctCollection.estimatedDocumentCountCollection.findDatabase.aggregateCRUD API 读取操作 Collection.watchDatabase.watchMongoClient.watch更改流操作 MongoClient.listDatabasesDatabase.listCollectionsCollection.listIndexes枚举操作 由 Collection.find 支持的 GridFS 操作(例如 GridFSBucket.openDownloadStream ) GridFS 文件下载操作
行为
readConcern 选项允许你控制从 复制集 和 分片集群 读取数据的一致性和隔离性
通过有效地使用 写关注 和 读关注,你可以适当地调整 一致性 和 可用性 的保证级别,例如等待以保证更强的一致性,或放松一致性要求以提供更高的可用性
将MongoDB驱动程序更新到MongoDB 3.2或更高版本以支持读关注
从 MongoDB 4.4 开始,副本集和分片集群支持设置全局默认读关注。未指定显式读取关注的操作会继承全局默认读取关注设置。有关详细信息,请参阅 setDefaultRWConcern
读关注级别
读关注详解
类似读隔离级别
使用
对于不在多文档事务中的操作,可以指定 readConcern 级别作为支持读关注的命令和方法的选项
1 readConcern : { level : <level> }
db.collection.find() 指定读取关注级别:
1 db.collection .find ().readConcern (<level>)
写关注描述了从 MongoDB 请求对独立 mongodmongos 实例会将写关注传递给分片
对于多文档事务,您在事务级别设置写关注,而不是在单个操作级别。不要为事务中的单个写操作显式设置写关注
如果您为多文档事务指定了一个 "majority" 写关注点,并且该事务未能复制到计算出的大多数副本集成员,那么该事务可能不会立即在副本集成员上回滚。副本集最终是一致的。始终在所有副本集成员上应用或回滚事务
写关注规范
1 { w : <value>, j : <boolean>, wtimeout : <number> }
w 选项请求确认写操作已传播到指定数量的mongod实例或具有指定标记的mongod实例j 选项请求 MongoDB 确认写入操作已写入磁盘日志,以便在系统出现故障时进行恢复wtimeout 此选项指定写入关注的时间限制(以毫秒为单位). wtimeout 仅适用于大于 1 的 w 值具体用法
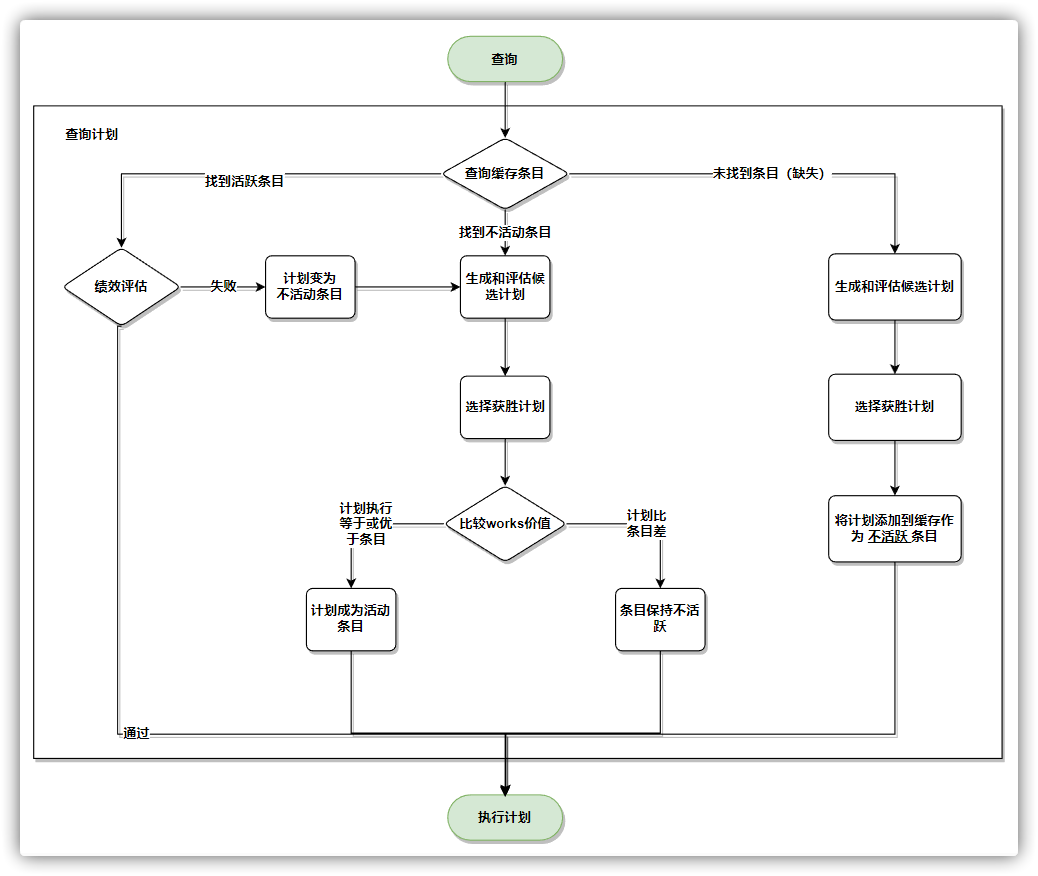
查询计划、性能和分析
原子性、一致性和分布式操作
对于查询,MongoDB查询优化器在给定可用索引的情况下选择并缓存效率最高的查询计划。最有效的查询计划的评估是基于查询执行计划在查询计划评估候选计划时执行的“工作单元”(works)的数量
Work units 是一种计算模型,用于确定 MongoDB 数据库中查询和更新操作的执行时间
Work units 的计算基于 MongoDB 的查询和更新操作,包括 find、insert、update 和 delete 等操作。每次查询或更新操作都会消耗一个或多个 work units
关联的计划缓存条目用于具有相同查询形状的后续查询
计划缓存条目状态
查询计划是指MongoDB查询优化器生成的用于执行查询的计划
查询形状(Query Shape)指的是查询的结构或模式,包括查询的字段条件和操作符等。它描述了查询逻辑结构,例如使用哪些字段进行过、排序或聚合等操作。查询形状可以通过查询语句来定义,如使用find()方法或聚合管道操作符
查询条目(Query Stage)查询计划中的每个步骤或阶段,用于处理查询的不同操作。每个查询阶段都会接收输入数据,并根据查询形状的定义对数据进行处理然后将结果传递下一个阶段。常见的查询段包括索引描、过滤、投影、排序和聚合等
查询形状和查询条目之间存在联系。查询形状定义了查询的逻辑结构,而查询条目则是实际执行查询的步骤
MongoDB 通过查询形状来定义查询操作,并指导查询引擎如何检索文档。查询形状中的每个部分都可以用来表示查询的不同方面,例如查询条件、查询范围和查询模式等。开发人员可以根据查询形状来设计和优化查询语句,以获得最佳的查询性能
从 MongoDB 4.2 开始,缓存条目与状态相关联:
State Description Missing (缺失) 缓存中不存在此形状的条目。Missing :works 值添加到处于 Inactive 状态的缓存中。 Inactive (不活跃) 缓存中的条目是此形状的占位符条目。也就是说,计划者已经看到了形状并计算了其成本(works值)并存储为占位符条目,但查询形状不用于生成查询计划。Inactive: works 值与非活动条目的值进行比较。如果所选计划的 works 值为:小于或等于 Inactive 条目的 Inactive 条目,并具有 Active 状态Inactive 条目变为 Active (例如,由于另一个查询操作),则仅当新活动条目的works值大于所选计划时,才会替换该新活动条目大于 Inactive 条目的 Inactive 条目保留,但其 works 值增加 Active (活跃) 缓存中的条目用于获胜计划。规划器可以使用该条目来生成查询计划。Active: works值不再符合选择标准,它将转换为非活动 状态。
有关触发计划缓存更改的其他场景,请参阅 计划缓存刷新
查询计划和高速缓存
要查看给定查询的查询计划信息,可以使用 db.collection.explain()cursor.explain()
从 MongoDB 4.2 开始,您可以使用 $planCacheStats
计划缓存刷新
如果 mongod 重新启动或关闭,查询计划缓存不会保留。此外:
索引或集合删除等目录操作会清除计划缓存 最近最少使用(LRU)高速缓存替换机制将清除最近最少访问的高速缓存条目 用户还可以:
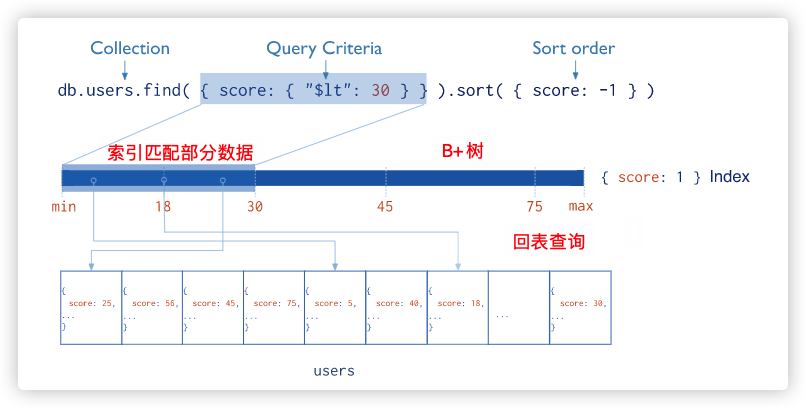
索引通过减少查询操作需要处理的数据量来提高读操作的效率。这简化了与在MongoDB中完成查询相关的工作
创建索引以支持读操作
如果应用程序查询特定字段或字段集上的集合,那么查询字段上的 索引 或字段集上的 复合索引 可以防止查询扫描整个集合来查找和返回查询结果。有关索引的更多信息,请参阅 MongoDB中索引中完整文档
例如
应用程序在 type 字段上查询 inventory 集合。 type 字段的值是用户驱动的
1 2 var typeValue = <someUserInput>;inventory .find ( { type : typeValue } );
要提高此查询的性能,请向 type 字段上的 inventory 集合添加升序或降序索引。在 mongosh 中,可以使用 db.collection.createIndex()
1 db.inventory .createIndex ( { type : 1 } )
该索引可以防止上述对 type 的查询扫描整个集合以返回结果
其他优化
查询选择性
指查询条件排除或过滤掉集合中文档的程度。查询选择性可以决定查询是否可以有效地使用索引,甚至根本不使用索引
更具选择性的查询匹配较小比例的文档。例如,对唯一 _id 字段的等式匹配具有高度选择性,因为它最多可以匹配一个文档
例如,不等运算符 $nin 和 $ne 的选择性不是很强,因为它们通常匹配索引的很大一部分。因此,在许多情况下,带有索引的 $nin 或 $ne 查询的性能可能并不比必须扫描集合中所有文档的 $nin 或 $ne 查询好
索引覆盖查询
查询中的所有字段都是索引的一部分
结果中返回的所有字段都在同一个索引中
嵌套文档
索引覆盖同样适用在嵌套文档中
多键覆盖
如果索引跟踪哪个或哪些字段导致索引成为多键,则多键索引可以覆盖对非数组字段的查询
多键索引 不能覆盖对 数组字段 的查询
性能
为索引包含查询所需的所有字段,所以MongoDB既可以匹配 查询条件 ,又可以仅使用索引返回结果
仅查询索引要比查询索引之外的文档快得多。索引键通常比它们编目的文档小,索引通常在RAM中可用,或按顺序位于磁盘上
局限性
地理空间索引无法覆盖查询
多键索引 不能覆盖对数组字段的查询
在 mongos 上运行时,如果索引包含分片键,则索引只能覆盖分片集合上的查询
查询计划返回结果 可能会因 MongoDB 版本而异
cursor.explain("executionStats")db.collection.explain("executionStats")db.collection.explain()
测试数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 db.inventory .insertMany ("_id" : 1 , "item" : "f1" , type : "food" , quantity : 500 },"_id" : 2 , "item" : "f2" , type : "food" , quantity : 100 },"_id" : 3 , "item" : "p1" , type : "paper" , quantity : 200 },"_id" : 4 , "item" : "p2" , type : "paper" , quantity : 150 },"_id" : 5 , "item" : "f3" , type : "food" , quantity : 300 },"_id" : 6 , "item" : "t1" , type : "toys" , quantity : 500 },"_id" : 7 , "item" : "a1" , type : "apparel" , quantity : 250 },"_id" : 8 , "item" : "a2" , type : "apparel" , quantity : 400 },"_id" : 9 , "item" : "t2" , type : "toys" , quantity : 50 },"_id" : 10 , "item" : "f4" , type : "food" , quantity : 75 }
没有索引的查询
1 2 3 4 5 6 7 8 9 10 11 12 13 db.inventory .find ( { quantity: { $gte: 100 , $lte: 200 } } "_id" : 2 , "item" : "f2" , "type" : "food" , "quantity" : 100 }"_id" : 3 , "item" : "p1" , "type" : "paper" , "quantity" : 200 }"_id" : 4 , "item" : "p2" , "type" : "paper" , "quantity" : 150 }
要查看所选的查询计划,请将 cursor.explain("executionStats")
1 2 3 4 5 6 7 8 db.inventory .find (quantity : {$gte : 100 ,$lte : 200 explain ("executionStats" )
返回以下执行计划:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 {"explainVersion" : "1" ,"queryPlanner" : {"namespace" : "test.inventory" ,"indexFilterSet" : false ,"parsedQuery" : {"$and" : [ "quantity" : {"$lte" : 200.0 "quantity" : {"$gte" : 100.0 "maxIndexedOrSolutionsReached" : false ,"maxIndexedAndSolutionsReached" : false ,"maxScansToExplodeReached" : false ,"winningPlan" : {"stage" : "COLLSCAN" ,"filter" : {"$and" : [ "quantity" : {"$lte" : 200.0 "quantity" : {"$gte" : 100.0 "direction" : "forward" "rejectedPlans" : []"executionStats" : {"executionSuccess" : true ,"nReturned" : 3 ,"executionTimeMillis" : 24 ,"totalKeysExamined" : 0 ,"totalDocsExamined" : 10 ,"executionStages" : {"stage" : "COLLSCAN" ,"filter" : {"$and" : [ "quantity" : {"$lte" : 200.0 "quantity" : {"$gte" : 100.0 "nReturned" : 3 ,"executionTimeMillisEstimate" : 0 ,"works" : 12 ,"advanced" : 3 ,"needTime" : 8 ,"needYield" : 0 ,"saveState" : 1 ,"restoreState" : 1 ,"isEOF" : 1 ,"direction" : "forward" ,"docsExamined" : 10 "command" : {"find" : "inventory" ,"filter" : {"quantity" : {"$gte" : 100.0 ,"$lte" : 200.0 "$db" : "test" "serverInfo" : {"host" : "4ffcfe6b7fdf" ,"port" : 27017 ,"version" : "5.0.5" ,"gitVersion" : "d65fd89df3fc039b5c55933c0f71d647a54510ae" "serverParameters" : {"internalQueryFacetBufferSizeBytes" : 104857600 ,"internalQueryFacetMaxOutputDocSizeBytes" : 104857600 ,"internalLookupStageIntermediateDocumentMaxSizeBytes" : 104857600 ,"internalDocumentSourceGroupMaxMemoryBytes" : 104857600 ,"internalQueryMaxBlockingSortMemoryUsageBytes" : 104857600 ,"internalQueryProhibitBlockingMergeOnMongoS" : 0 ,"internalQueryMaxAddToSetBytes" : 104857600 ,"internalDocumentSourceSetWindowFieldsMaxMemoryBytes" : 104857600 "ok" : 1.0
执行计划返回结果详解
匹配 文档的数量和 检查 文档的数量之间的差异可能表明,为了提高效率,查询可能会受益于索引的使用
使用索引
1 2 3 4 5 db.inventory .createIndex (quantity : 1
查看执行计划:
1 2 3 4 5 6 7 8 db.inventory .find (quantity : {$gte : 100 ,$lte : 200 explain ("executionStats" )
返回的查询计划:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 {"explainVersion" : "1" ,"queryPlanner" : {"namespace" : "test.inventory" ,"indexFilterSet" : false ,"parsedQuery" : {"$and" : [ "quantity" : {"$lte" : 200.0 "quantity" : {"$gte" : 100.0 "maxIndexedOrSolutionsReached" : false ,"maxIndexedAndSolutionsReached" : false ,"maxScansToExplodeReached" : false ,"winningPlan" : {"stage" : "FETCH" ,"inputStage" : {"stage" : "IXSCAN" ,"keyPattern" : {"quantity" : 1.0 "indexName" : "quantity_1" ,"isMultiKey" : false ,"multiKeyPaths" : {"quantity" : []"isUnique" : false ,"isSparse" : false ,"isPartial" : false ,"indexVersion" : 2 ,"direction" : "forward" ,"indexBounds" : {"quantity" : [ "[100.0, 200.0]" "rejectedPlans" : []"executionStats" : {"executionSuccess" : true ,"nReturned" : 3 ,"executionTimeMillis" : 1 ,"totalKeysExamined" : 3 ,"totalDocsExamined" : 3 ,"executionStages" : {"stage" : "FETCH" ,"nReturned" : 3 ,"executionTimeMillisEstimate" : 0 ,"works" : 4 ,"advanced" : 3 ,"needTime" : 0 ,"needYield" : 0 ,"saveState" : 0 ,"restoreState" : 0 ,"isEOF" : 1 ,"docsExamined" : 3 ,"alreadyHasObj" : 0 ,"inputStage" : {"stage" : "IXSCAN" ,"nReturned" : 3 ,"executionTimeMillisEstimate" : 0 ,"works" : 4 ,"advanced" : 3 ,"needTime" : 0 ,"needYield" : 0 ,"saveState" : 0 ,"restoreState" : 0 ,"isEOF" : 1 ,"keyPattern" : {"quantity" : 1.0 "indexName" : "quantity_1" ,"isMultiKey" : false ,"multiKeyPaths" : {"quantity" : []"isUnique" : false ,"isSparse" : false ,"isPartial" : false ,"indexVersion" : 2 ,"direction" : "forward" ,"indexBounds" : {"quantity" : [ "[100.0, 200.0]" "keysExamined" : 3 ,"seeks" : 1 ,"dupsTested" : 0 ,"dupsDropped" : 0 "command" : {"find" : "inventory" ,"filter" : {"quantity" : {"$gte" : 100.0 ,"$lte" : 200.0 "$db" : "test" "serverInfo" : {"host" : "4ffcfe6b7fdf" ,"port" : 27017 ,"version" : "5.0.5" ,"gitVersion" : "d65fd89df3fc039b5c55933c0f71d647a54510ae" "serverParameters" : {"internalQueryFacetBufferSizeBytes" : 104857600 ,"internalQueryFacetMaxOutputDocSizeBytes" : 104857600 ,"internalLookupStageIntermediateDocumentMaxSizeBytes" : 104857600 ,"internalDocumentSourceGroupMaxMemoryBytes" : 104857600 ,"internalQueryMaxBlockingSortMemoryUsageBytes" : 104857600 ,"internalQueryProhibitBlockingMergeOnMongoS" : 0 ,"internalQueryMaxAddToSetBytes" : 104857600 ,"internalDocumentSourceSetWindowFieldsMaxMemoryBytes" : 104857600 "ok" : 1.0
如果没有索引,查询将扫描整个 10 文档集合以返回 3 匹配文档。查询还必须扫描每个文档的全部内容,可能会将它们拉入内存。这会导致昂贵且可能很慢的查询操作
使用索引运行时,查询会扫描 3 索引条目和 3 文档以返回 3 匹配文档,从而实现非常高效的查询
原子性
在MongoDB中,写操作在单个文档级别上是原子的,即使该操作修改了单个文档中嵌入的多个文档
多文档事务
当单个写操作(例如 db.collection.updateMany() )修改多个文档时,每个文档的修改是原子的,但整个操作不是原子的
当执行多文档写操作时,无论是通过单个写操作还是通过多个写操作,其他操作都可能会交错
对于需要对多个文档(在单个或多个集合中)进行读写原子性的情况,MongoDB 支持多文档事务:
在 4.0 版本中,MongoDB 支持副本集上的多文档事务 在 4.2 版本中,MongoDB 引入了分布式事务,增加了对分片集群上的多文档事务的支持,并合并了现有的对副本集上的多文档事务的支持 有关 MongoDB 中事务的详细信息,请参阅 事务 页面
在大多数情况下,多文档事务会比单文档写入产生更大的性能成本,并且多文档事务的可用性不应取代有效的模式设计。对于许多场景,非规范化数据模型(嵌入式文档和数组)将继续成为您的数据和用例的最佳选择。也就是说,对于许多场景,适当地建模数据将最大限度地减少对多文档事务的需求。
并发控制
并发控制允许多个应用程序并发运行,而不会导致数据不一致或冲突
对文档的 findAndModify
例如
包含两个文档的集合:
1 2 3 4 db.myCollection .insertMany ( [_id : 0 , a : 1 , b : 1 },_id : 1 , a : 1 , b : 1 }
以下两个 findAndModify
1 2 3 4 db.myCollection .findAndModify ( {query : { a : 1 },update : { $inc : { b : 1 }, $set : { a : 2 } }
findAndModifya 和 b 都设置为 2
说明并发是互斥的
还可以在字段上创 唯一索引 ,以便它只能具有唯一值。这可以防止插入和更新创建重复数据。您可以在多个字段上创建唯一索引,以确保字段值的组合是唯一的。有关示例,请参阅 findAndModify() 使用唯一索引更新或插入
隔离保证
读未提交
根据读取的关注点,客户端可以在 持久化 写入之前看到写入的结果:
无论写操作的写关注点如何,使用 “local” 或 “available” 读取关注点的其他客户端可以在写操作被确认给发出该写操作的客户端之前看到写操作的结果 使用 “local” 或 “available” 读取关注点的客户端可以读取可能在副本集故障切换期间被回滚的数据 在多文档事务中,当事务提交时,事务中所做的所有数据更改都会保存并在事务外部可见。也就是说,事务不会只提交其中的一些更改同时回滚其他更改
在事务提交之前,事务中所做的数据更改对事务外部是不可见的
然而,当事务写入多个分片时,并不是所有外部读取操作都需要等待已提交事务的结果在所有分片间可见。例如,如果事务已提交,写入 1 在分片 A 上可见,但写入 2 在分片 B 上尚不可见,在使用“local”读取关注点时,可以读取写入 1 的结果而无需看到写入 2
读未提交是 默认的隔离级别,适用于mongod独立实例以及复制集和分片群集
读未提交和单文档原子性
写操作对于单个文档是原子的;也就是说,如果写操作正在更新文档中的多个字段,那么读操作永远不会看到只更新了一部分字段的文档。然而,即使客户端可能没有看到部分更新的文档,读取未提交意味着并发读操作仍然可以在更改变得持久之前看到更新的文档
在独立的 mongod 实例中,对于单个文档的一组读取和写入操作是可串行化的。在副本集中,只有在没有回滚的情况下,对于单个文档的一系列读取和写入操作才是可串行化的
读未提交和多文档写入
当单个写操作(例如 db.collection.updateMany())修改多个文档时,每个文档的修改是原子的,但整个操作不是原子的 执行多文档写入操作时,无论是通过单个写操作还是多个写操作,其他操作都可能交错执行 对于需要对多个文档进行读取和写入操作(在单个或多个集合中)的情况,MongoDB 支持多文档事务在 4.0 版本中,MongoDB 在副本集上支持多文档事务 在 4.2 版本中,MongoDB 引入分布式事务,为分片集群添加了对多文档事务的支持,并整合了对副本集的多文档事务支持 在大多数情况下,相对于单文档写入,多文档事务会带来更大的性能开销,并且多文档事务的可用性不应该取代有效的架构设计。对于许多场景,规范化的数据模型(嵌入式文档和数组)仍然是数据和使用案例的最佳选择。也就是说,对于许多场景,适当地对数据进行建模将最小化对多文档事务的需求
游标快照
在某些情况下,MongoDB 游标可以返回同一文档多次。当游标返回文档时,其他操作可以与查询交错执行。如果这些操作之一更改了查询所使用的索引上的索引字段,那么游标可能会多次返回相同的文档 使用唯一索引的查询在某些情况下可能会返回重复的值。如果一个使用唯一索引的游标与具有相同唯一值的文档的删除和插入交错执行,那么游标可能会从不同的文档中两次返回相同的唯一值 可以使用读关注点的 snapshot 来解决这个问题 实时顺序
将读关注设置为 linearizable,将写关注设置为 majority,那么这种读写模型组合可以使多个线程可以在单个文档上执行读写操作,就好像单个线程实时执行了这些操作一样 ; 也就是说,这些读写的相应计划被认为是线性的
如果一个操作在逻辑上依赖于前一个操作,那么这两个操作之间存在因果关系。例如,一个删除基于特定条件的所有文档的写操作和一个后续的读操作来验证删除操作之间存在因果关系。
使用因果一致性会话,MongoDB 按照它们的因果关系对操作进行排序,并保证客户端所观察到的结果与这些因果关系一致
客户端会话和因果一致性保证
为了提供因果一致性,MongoDB 3.6 在客户端会话中启用了因果一致性。因果一致性会话表示具有 majority 读关注点的读操作序列和具有 majority 写关注点的写操作序列之间具有因果关系,并通过它们的顺序来体现。应用程序必须确保一次只能有一个线程在客户端会话中执行这些操作
重要提示 :客户端会话仅对以下情况保证因果一致性:
当客户端发出带有 majority 读关注点的读操作和带有 majority 写关注点的写操作序列时,客户端会在每个操作中包含会话信息
对于与会话关联的每个带有 majority 读关注点的读操作和带有 majority 写关注点的写操作,MongoDB 返回操作时间和集群时间,即使操作出现错误。客户端会话会跟踪操作时间和集群时间(线性一致)
因果一致性会话中的操作与会话外的操作不隔离。如果并发写操作在会话的写操作和读操作之间交错执行,会话的读操作可能会返回反映在会话的写操作之后发生的写操作的结果
因果一致性使用
考虑一个名为 items 的集合,该集合维护各种物品的当前和历史数据。只有历史数据具有非空的结束日期。如果某个物品的 SKU 值发生更改,需要将具有旧 SKU 值的文档进行更新,并在之后插入一个新文档以包含当前的 SKU 值。客户端可以使用因果一致性会话确保更新发生在插入之前
1 2 3 4 5 6 7 8 9 10 11 12 13 ClientSession session1 = client.startSession(ClientSessionOptions.builder().causallyConsistent(true ).build());Date currentDate = new Date ();"test" )1000 , TimeUnit.MILLISECONDS))"test" );"sku" , "111" ), set("end" , currentDate));Document document = new Document ("sku" , "nuts-111" )"name" , "Pecans" )"start" , currentDate);
聚合操作处理数据记录并返回计算结果(诸如统计平均值,求和等)。聚合操作组值来自多个文档,可以对分组数据执行各种操作以返回单个结果。聚合操作包含三类:
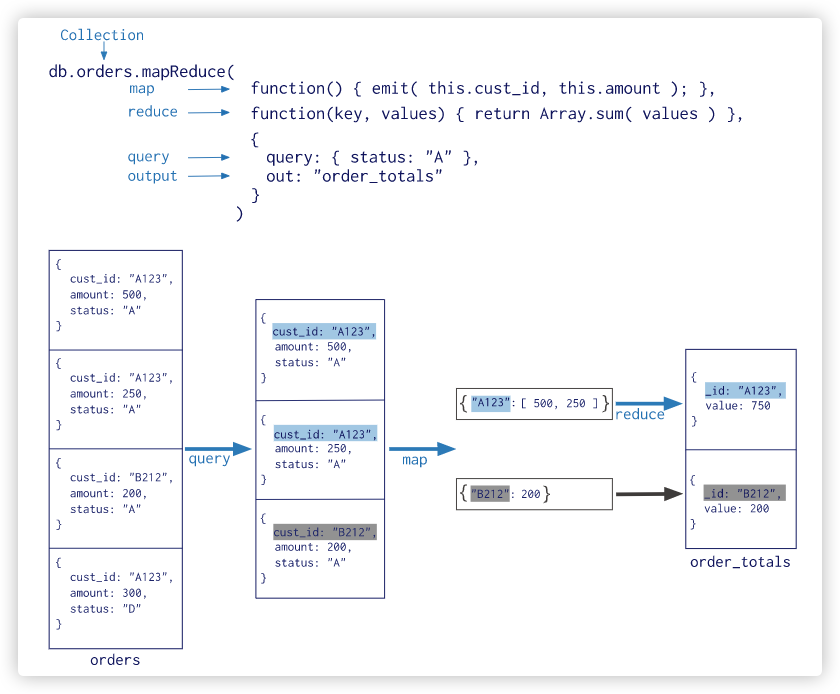
单一作用聚合:提供了对常见聚合过程的简单访问,操作都从单个集合聚合文档 聚合管道是一个数据聚合的框架,模型基于数据处理流水线的概念。文档进入多级管道,将文档转换为聚合结果 从 MongoDB 5.0 开始,不推荐使用 map-reduce 聚合管道操作符
这类单一作用的聚合函数。 所有这些操作都聚合来自单个集合的文档。虽然这些操作提供了对公共聚合过程的简单访问,但它们缺乏聚合管道和map-Reduce的灵活性和功能
测试数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 db.inventory .insertMany ("_id" : 1 , "item" : "f1" , type : "food" , quantity : 500 },"_id" : 2 , "item" : "f2" , type : "food" , quantity : 100 },"_id" : 3 , "item" : "p1" , type : "paper" , quantity : 200 },"_id" : 4 , "item" : "p2" , type : "paper" , quantity : 150 },"_id" : 5 , "item" : "f3" , type : "food" , quantity : 300 },"_id" : 6 , "item" : "t1" , type : "toys" , quantity : 500 },"_id" : 7 , "item" : "a1" , type : "apparel" , quantity : 250 },"_id" : 8 , "item" : "a2" , type : "apparel" , quantity : 400 },"_id" : 9 , "item" : "t2" , type : "toys" , quantity : 50 },"_id" : 10 , "item" : "f4" , type : "food" , quantity : 75 }
estimatedDocumentCount()
忽略查询条件,返回集合或视图中所有文档的计数
1 2 3 4 db.inventory .estimatedDocumentCount ()10
count()
1 2 3 4 5 6 7 8 9 10 db.inventory .count (quantity : {$gte : 300 4
distinct()
type 字段去重 查询条件 quantity >= 100 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 db.inventory .distinct ("type" ,quantity : {$gte : 100 "apparel" ,"food" ,"paper" ,"toys"
SQL和Mongo聚合对比
聚合框架
MongoDB 聚合框架(Aggregation Framework)是一个计算框架,它可以:
作用在一个或几个集合上 对集合中的数据进行的一系列运算 将这些数据转化为期望的形式 从效果而言,聚合框架相当于 SQL 查询中的GROUP BY、 LEFT OUTER JOIN 、 AS等
聚合与管道
聚合管道阶段文档
整个聚合运算过程称为管道(Pipeline),它是由多个阶段(Stage)组成的, 每个管道:
接受一系列文档(原始数据) 每个阶段对这些文档进行一系列运算 结果文档输出给下一个阶段 完整的聚合管道示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 db.orders .insertMany ( [_id : 0 , name : "Pepperoni" , size : "small" , price : 19 ,quantity : 10 , date : ISODate ( "2021-03-13T08:14:30Z" ) },_id : 1 , name : "Pepperoni" , size : "medium" , price : 20 ,quantity : 20 , date : ISODate ( "2021-03-13T09:13:24Z" ) },_id : 2 , name : "Pepperoni" , size : "large" , price : 21 ,quantity : 30 , date : ISODate ( "2021-03-17T09:22:12Z" ) },_id : 3 , name : "Cheese" , size : "small" , price : 12 ,quantity : 15 , date : ISODate ( "2021-03-13T11:21:39.736Z" ) },_id : 4 , name : "Cheese" , size : "medium" , price : 13 ,quantity :50 , date : ISODate ( "2022-01-12T21:23:13.331Z" ) },_id : 5 , name : "Cheese" , size : "large" , price : 14 ,quantity : 10 , date : ISODate ( "2022-01-12T05:08:13Z" ) },_id : 6 , name : "Vegan" , size : "small" , price : 17 ,quantity : 10 , date : ISODate ( "2021-01-13T05:08:13Z" ) },_id : 7 , name : "Vegan" , size : "medium" , price : 18 ,quantity : 10 , date : ISODate ( "2021-01-13T05:10:13Z" ) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 db.orders .aggregate ($match : {size : "medium" }$group : {_id : "$name" ,totalQuantity : { $sum : "$quantity" },totalPrice : {$sum :{ $multiply : ["$price" , "$quantity" ]}}"_id" : "Vegan" ,"totalQuantity" : 10.0 ,"totalPrice" : 180.0 "_id" : "Pepperoni" ,"totalQuantity" : 20.0 ,"totalPrice" : 400.0 "_id" : "Cheese" ,"totalQuantity" : 50.0 ,"totalPrice" : 650.0
$match
过滤 size 为 medium 的比萨订单 将剩余的文档传递到 $group $group
按 pizza name 对剩余文档进行分组 使用 $sumname 的总订单 quantity 。总数存储在聚合管道返回的 totalQuantity 字段中 阶段 描述 $addFields 向文档添加新字段。与project类似,addFields重塑了流中的每个文档;具体而言,通过向输出文档添加新字段,该文档包含输入文档和新添加字段中的现有字段。 $set是的别名$addFields。 $bucket 根据指定的表达式和存储段边界将传入文档分类为称为存储段的组。 $bucketAuto 根据指定的表达式将传入的文档分类为特定数量的组(称为存储桶)。自动确定存储桶边界,以尝试将文档均匀地分配到指定数量的存储桶中。 $collStats 返回有关集合或视图的统计信息。 $count 返回聚合管道此阶段的文档数量计数。 $facet 在同一阶段的同一组输入文档上处理多个聚合管道。支持在一个阶段中创建能够表征多维或多面数据的多面聚合。 $geoNear 基于与地理空间点的接近度返回有序的文档流。将$match,$sort和$limit的功能合并到地理空间数据中。输出文档包括附加距离字段,并且可以包括位置标识符字段。 $graphLookup 对集合执行递归搜索。对于每个输出文档,添加一个新的 array 字段,该字段包含该文档的递归搜索的遍历结果。 $group 按指定的标识符表达式对文档进行分组,并将累加器表达式(如果指定)应用于每个 group。消耗所有输入文档,并为每个不同的 group 输出一个文档。输出文档仅包含标识符字段,如果指定,则包含累积字段。 $indexStats 返回有关集合的每个索引的使用的统计信息。 $limit 将未修改的前 n 个文档传递给管道,其中 n 是指定的限制。对于每个输入文档,输出一个文档(对于前 n 个文档)或零文档(在前 n 个文档之后)。 $listSessions 列出所有活动时间已足够长以传播到system.sessions集合的会话。 $lookup 对同一数据库中的另一个集合执行左外连接,以从“已连接”集合中过滤文档以进行处理。 $match 过滤文档流以仅允许匹配的文档未经修改地传递到下一个管道阶段。 $match使用标准的 MongoDB 查询。对于每个输入文档,输出一个文档(匹配)或零文档(不匹配)。 $merge 将聚合管道的结果文档写入集合。该阶段可以将结果合并(插入新文档,合并文档,替换文档,保留现有文档,使操作失败,使用自定义更新管道处理文档)将结果合并到输出集合中。要使用该$merge阶段,它必须是管道中的最后一个阶段。 4.2版中的新功能。 $out 将聚合管道的结果文档写入集合。要使用$out阶段,它必须是管道中的最后一个阶段。 $planCacheStats 返回集合的计划缓存信息。 $project 重塑流中的每个文档,例如通过添加新字段或删除现有字段。对于每个输入文档,输出一个文档。 另请参阅$unset删除现有字段。 $redact 通过基于文档本身中存储的信息限制每个文档的内容来重塑流中的每个文档。包含$project和$match的功能。可用于实现字段级编辑。对于每个输入文档,输出一个或零个文档。 $replaceRoot 用指定的嵌入文档替换文档。该操作将替换输入文档中的所有现有字段,包括_id字段。指定嵌入在输入文档中的文档,以将嵌入的文档提升到顶部级别。 $replaceWith是$replaceRoot阶段的别名 。 $replaceWith 用指定的嵌入文档替换文档。该操作将替换输入文档中的所有现有字段,包括_id字段。指定嵌入在输入文档中的文档,以将嵌入的文档提升到顶部级别。 $replaceWith是$replaceRoot阶段的别名 。 $sample 从输入中随机选择指定数量的文档。 $set 将新字段添加到文档。与$project相似,$set重塑流中的每个文档;具体而言,通过向输出文档添加新字段,该输出文档既包含输入文档中的现有字段,又包含新添加的字段。 $set是$addFields阶段的别名。 $skip 跳过前 n 个文档,其中 n 是指定的跳过编号,并将未修改的其余文档传递给管道。对于每个输入文档,输出零文档(对于前 n 个文档)或一个文档(如果在前 n 个文档之后)。 $sort 按指定的排序 key 重新排序文档流。只有顺序改变;文档保持不变。对于每个输入文档,输出一个文档。 sortByCount 根据指定表达式的 value 对传入文档进行分组,然后计算每个不同 group 中的文档计数。 $unset 从文档中删除/排除字段。 $unset是$project删除字段的阶段的别名。 $unwind 将数组展开后形成一个独立的文档。每个输出文档都使用元素 value 替换 array。对于每个输入文档,输出 n 个文档,其中 n 是 array 元素的数量,对于空 array 可以为零。
过滤文档以仅允许匹配的文档未经修改地传递到下一个管道阶段
测试数据
1 2 3 4 5 6 7 8 9 10 11 db.articles .insertMany ("_id" : ObjectId ("512bc95fe835e68f199c8686" ), "author" : "dave" , "score" : 80 , "views" : 100 },"_id" : ObjectId ("512bc962e835e68f199c8687" ), "author" : "dave" , "score" : 85 , "views" : 521 },"_id" : ObjectId ("55f5a192d4bede9ac365b257" ), "author" : "ahn" , "score" : 60 , "views" : 1000 },"_id" : ObjectId ("55f5a192d4bede9ac365b258" ), "author" : "li" , "score" : 55 , "views" : 5000 },"_id" : ObjectId ("55f5a1d3d4bede9ac365b259" ), "author" : "annT" , "score" : 60 , "views" : 50 },"_id" : ObjectId ("55f5a1d3d4bede9ac365b25a" ), "author" : "li" , "score" : 94 , "views" : 999 },"_id" : ObjectId ("55f5a1d3d4bede9ac365b25b" ), "author" : "ty" , "score" : 95 , "views" : 1000 }
简单数据匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 db.articles .aggregate ($match : {author : "dave" }}"_id" : ObjectId ("512bc95fe835e68f199c8686" ),"author" : "dave" ,"score" : 80.0 ,"views" : 100.0 "_id" : ObjectId ("512bc962e835e68f199c8687" ),"author" : "dave" ,"score" : 85.0 ,"views" : 521.0
将具有请求字段的文档传递到管道中的下一阶段。指定的字段可以是输入文档中的现有字段或新计算的字段
1 { $project : { <specification(s)> } }
测试数据
1 2 3 4 5 6 7 8 9 10 11 db.books .insertMany ("_id" : 1 ,title : "abc123" ,isbn : "0001122223334" ,author : { last : "zzz" , first : "aaa" },copies : 5
下面的聚合仅展示 title 和 author 字段(_id 是默认展示的)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 db.books .aggregate ( [ {$project: {title:1 , author:1 }} ] "_id" : 1.0 ,"title" : "abc123" ,"author" : {"last" : "zzz" ,"first" : "aaa"
返回聚合管道此阶段的文档数量计数
测试数据
1 2 3 4 5 6 7 8 9 10 db.scores .insertMany ("_id" : 1 , "subject" : "History" , "score" : 88 },"_id" : 2 , "subject" : "History" , "score" : 92 },"_id" : 3 , "subject" : "History" , "score" : 97 },"_id" : 4 , "subject" : "History" , "score" : 71 },"_id" : 5 , "subject" : "History" , "score" : 79 },"_id" : 6 , "subject" : "History" , "score" : 83 }
统计成绩高于80分的人数
1 2 3 4 5 6 7 8 9 10 11 db.scores .aggregate ( [ {$match: {score: {$gt: 80 }}}, {$count: "countNum" } ] "countNum" : 4
按指定的标识符表达式对文档进行分组,并将累加器表达式(如果指定)应用于每个 group
支持的累加运算符
1 2 3 4 5 6 7 8 {$group :_id : <expression>,
测试数据
1 2 3 4 5 6 7 8 9 10 db.sales .insertMany (["_id" : 1 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("2" ), "date" : ISODate ("2014-03-01T08:00:00Z" ) },"_id" : 2 , "item" : "jkl" , "price" : NumberDecimal ("20" ), "quantity" : NumberInt ("1" ), "date" : ISODate ("2014-03-01T09:00:00Z" ) },"_id" : 3 , "item" : "xyz" , "price" : NumberDecimal ("5" ), "quantity" : NumberInt ( "10" ), "date" : ISODate ("2014-03-15T09:00:00Z" ) },"_id" : 4 , "item" : "xyz" , "price" : NumberDecimal ("5" ), "quantity" : NumberInt ("20" ) , "date" : ISODate ("2014-04-04T11:21:39.736Z" ) },"_id" : 5 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("10" ) , "date" : ISODate ("2014-04-04T21:23:13.331Z" ) },"_id" : 6 , "item" : "def" , "price" : NumberDecimal ("7.5" ), "quantity" : NumberInt ("5" ) , "date" : ISODate ("2015-06-04T05:08:13Z" ) },"_id" : 7 , "item" : "def" , "price" : NumberDecimal ("7.5" ), "quantity" : NumberInt ("10" ) , "date" : ISODate ("2015-09-10T08:43:00Z" ) },"_id" : 8 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("5" ) , "date" : ISODate ("2016-02-06T20:20:13Z" ) },
根据 item 分组,统计每组 item 的文档数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 db.sales .aggregate ($group : {_id : "$item" ,count : {$count : {}"_id" : "jkl" ,"count" : 1 "_id" : "def" ,"count" : 2 "_id" : "abc" ,"count" : 3 "_id" : "xyz" ,"count" : 2
按照 item 分组,求每组最大的 quantity
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 db.sales .aggregate ($group : {_id : "$item" ,maxQuantity : {$max : "$quantity" "_id" : "xyz" ,"maxQuantity" : 20 "_id" : "jkl" ,"maxQuantity" : 1 "_id" : "abc" ,"maxQuantity" : 10 "_id" : "def" ,"maxQuantity" : 10
实现having
先按照 item 分组计算销售总价,然后再过滤销售总价少于100的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 db.sales .aggregate ($group : {_id : "$item" ,total : {$sum : {$multiply : ["$price" , "$quantity" ]$match : {total : {$gt : 100 "_id" : "xyz" ,"total" : NumberDecimal ("150" )"_id" : "abc" ,"total" : NumberDecimal ("170" )"_id" : "def" ,"total" : NumberDecimal ("112.5" )
将数组字段进行展开,然后每个数组元素重新生成一份新的文档
1 { $unwind : <field path > }
测试数据
1 db.inventory .insertOne ({ "_id" : 1 , "item" : "ABC1" , sizes : [ "S" , "M" , "L" ] })
将数组 $sizes 进行展开
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 db.inventory .aggregate ($unwind : "$sizes" }"_id" : 1.0 ,"item" : "ABC1" ,"sizes" : "S" "_id" : 1.0 ,"item" : "ABC1" ,"sizes" : "M" "_id" : 1.0 ,"item" : "ABC1" ,"sizes" : "L"
限制传递到管道中下一阶段的文档数量
1 { $limit : <positive 64-bit integer > }
测试数据
1 2 3 4 5 6 7 8 9 10 db.sales .insertMany (["_id" : 1 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("2" ), "date" : ISODate ("2014-03-01T08:00:00Z" ) },"_id" : 2 , "item" : "jkl" , "price" : NumberDecimal ("20" ), "quantity" : NumberInt ("1" ), "date" : ISODate ("2014-03-01T09:00:00Z" ) },"_id" : 3 , "item" : "xyz" , "price" : NumberDecimal ("5" ), "quantity" : NumberInt ( "10" ), "date" : ISODate ("2014-03-15T09:00:00Z" ) },"_id" : 4 , "item" : "xyz" , "price" : NumberDecimal ("5" ), "quantity" : NumberInt ("20" ) , "date" : ISODate ("2014-04-04T11:21:39.736Z" ) },"_id" : 5 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("10" ) , "date" : ISODate ("2014-04-04T21:23:13.331Z" ) },"_id" : 6 , "item" : "def" , "price" : NumberDecimal ("7.5" ), "quantity" : NumberInt ("5" ) , "date" : ISODate ("2015-06-04T05:08:13Z" ) },"_id" : 7 , "item" : "def" , "price" : NumberDecimal ("7.5" ), "quantity" : NumberInt ("10" ) , "date" : ISODate ("2015-09-10T08:43:00Z" ) },"_id" : 8 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("5" ) , "date" : ISODate ("2016-02-06T20:20:13Z" ) },
传递2条数据到聚合下个阶段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 db.sales .aggregate ($limit : 2 }"_id" : 1.0 ,"item" : "abc" ,"price" : NumberDecimal ("10" ),"quantity" : 2 ,"date" : ISODate ("2014-03-01T08:00:00.000Z" )"_id" : 2.0 ,"item" : "jkl" ,"price" : NumberDecimal ("20" ),"quantity" : 1 ,"date" : ISODate ("2014-03-01T09:00:00.000Z" )
取一个正整数,指定要跳过的最大文档数,并将剩余的文档传递到管道中的下一阶段
1 { $skip : <positive 64-bit integer > }
测试数据
1 2 3 4 5 6 7 8 9 10 db.sales .insertMany (["_id" : 1 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("2" ), "date" : ISODate ("2014-03-01T08:00:00Z" ) },"_id" : 2 , "item" : "jkl" , "price" : NumberDecimal ("20" ), "quantity" : NumberInt ("1" ), "date" : ISODate ("2014-03-01T09:00:00Z" ) },"_id" : 3 , "item" : "xyz" , "price" : NumberDecimal ("5" ), "quantity" : NumberInt ( "10" ), "date" : ISODate ("2014-03-15T09:00:00Z" ) },"_id" : 4 , "item" : "xyz" , "price" : NumberDecimal ("5" ), "quantity" : NumberInt ("20" ) , "date" : ISODate ("2014-04-04T11:21:39.736Z" ) },"_id" : 5 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("10" ) , "date" : ISODate ("2014-04-04T21:23:13.331Z" ) },"_id" : 6 , "item" : "def" , "price" : NumberDecimal ("7.5" ), "quantity" : NumberInt ("5" ) , "date" : ISODate ("2015-06-04T05:08:13Z" ) },"_id" : 7 , "item" : "def" , "price" : NumberDecimal ("7.5" ), "quantity" : NumberInt ("10" ) , "date" : ISODate ("2015-09-10T08:43:00Z" ) },"_id" : 8 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("5" ) , "date" : ISODate ("2016-02-06T20:20:13Z" ) },
跳过前两条数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 db.sales .aggregate ($skip : 2 },$project : {_id : 1 }}"_id" : 3.0 "_id" : 4.0 "_id" : 5.0 "_id" : 6.0 "_id" : 7.0 "_id" : 8.0
对所有输入文档进行排序并按排序顺序将它们返回到管道
1 { $sort : { <field1>: <sort order>, <field2>: <sort order> ... } }
测试数据
1 2 3 4 5 6 7 8 9 10 db.sales .insertMany (["_id" : 1 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("2" ), "date" : ISODate ("2014-03-01T08:00:00Z" ) },"_id" : 2 , "item" : "jkl" , "price" : NumberDecimal ("20" ), "quantity" : NumberInt ("1" ), "date" : ISODate ("2014-03-01T09:00:00Z" ) },"_id" : 3 , "item" : "xyz" , "price" : NumberDecimal ("5" ), "quantity" : NumberInt ( "10" ), "date" : ISODate ("2014-03-15T09:00:00Z" ) },"_id" : 4 , "item" : "xyz" , "price" : NumberDecimal ("5" ), "quantity" : NumberInt ("20" ) , "date" : ISODate ("2014-04-04T11:21:39.736Z" ) },"_id" : 5 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("10" ) , "date" : ISODate ("2014-04-04T21:23:13.331Z" ) },"_id" : 6 , "item" : "def" , "price" : NumberDecimal ("7.5" ), "quantity" : NumberInt ("5" ) , "date" : ISODate ("2015-06-04T05:08:13Z" ) },"_id" : 7 , "item" : "def" , "price" : NumberDecimal ("7.5" ), "quantity" : NumberInt ("10" ) , "date" : ISODate ("2015-09-10T08:43:00Z" ) },"_id" : 8 , "item" : "abc" , "price" : NumberDecimal ("10" ), "quantity" : NumberInt ("5" ) , "date" : ISODate ("2016-02-06T20:20:13Z" ) },
按照 price 升序 quantity 降序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 db.sales .aggregate ($sort : {price : 1 ,quantity : -1 $project : {price : 1 ,quantity : 1 "_id" : 4.0 ,"price" : NumberDecimal ("5" ),"quantity" : 20 "_id" : 3.0 ,"price" : NumberDecimal ("5" ),"quantity" : 10 "_id" : 7.0 ,"price" : NumberDecimal ("7.5" ),"quantity" : 10 "_id" : 6.0 ,"price" : NumberDecimal ("7.5" ),"quantity" : 5 "_id" : 5.0 ,"price" : NumberDecimal ("10" ),"quantity" : 10 "_id" : 8.0 ,"price" : NumberDecimal ("10" ),"quantity" : 5 "_id" : 1.0 ,"price" : NumberDecimal ("10" ),"quantity" : 2 "_id" : 2.0 ,"price" : NumberDecimal ("20" ),"quantity" : 1
主要用来实现多表关联查询, 相当关系型数据库中多表左外连接。每个输入待处理的文档,经过$lookup 阶段的处理,输出的新文档中会包含一个新生成的数(可根据需要命名新key )。数组列存放的数据是来自被Join集合的适配文档,如果没有,集合为空
1 2 3 4 5 6 7 8 9 {$lookup :from : <collection to join>,
测试数据
1 2 3 4 5 db.orders .insertMany ( ["_id" : 1 , "item" : "almonds" , "price" : 12 , "quantity" : 2 },"_id" : 2 , "item" : "pecans" , "price" : 20 , "quantity" : 1 },"_id" : 3 }
1 2 3 4 5 6 7 8 db.inventory .insertMany ( ["_id" : 1 , "sku" : "almonds" , "description" : "product 1" , "instock" : 120 },"_id" : 2 , "sku" : "bread" , "description" : "product 2" , "instock" : 80 },"_id" : 3 , "sku" : "cashews" , "description" : "product 3" , "instock" : 60 },"_id" : 4 , "sku" : "pecans" , "description" : "product 4" , "instock" : 70 },"_id" : 5 , "sku" : null , "description" : "Incomplete" },"_id" : 6 }
以下对 orders 集合的聚合操作使用来自 orders 集合的字段 item 和来自 inventory 集合的 sku 字段将来自 orders 的文档与来自 inventory 集合的文档连接起来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 db.orders .aggregate ($lookup : {from : "inventory" ,localField : "item" ,foreignField : "sku" ,as : "inventory_docs" "_id" : 1.0 ,"item" : "almonds" ,"price" : 12.0 ,"quantity" : 2.0 ,"inventory_docs" : [ "_id" : 1.0 ,"sku" : "almonds" ,"description" : "product 1" ,"instock" : 120.0 "_id" : 2.0 ,"item" : "pecans" ,"price" : 20.0 ,"quantity" : 1.0 ,"inventory_docs" : [ "_id" : 4.0 ,"sku" : "pecans" ,"description" : "product 4" ,"instock" : 70.0 "_id" : 3.0 ,"inventory_docs" : [ "_id" : 5.0 ,"sku" : null ,"description" : "Incomplete" "_id" : 6.0
从MongoDB 5.0开始,map-reduce被弃用,推荐使用管道聚合
Map-reduce是一种数据处理范例,用于将大量数据压缩为有用的聚合结果。MapReduce操作将大量的数据处理工作拆分成多个线程并行处理,然后将结果合并在一起。MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用
MapReduce具有两个阶段:
将具有相同Key的文档数据整合在一起的map阶段 组合map操作的结果进行统计输出的reduce阶段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 db.collection .mapReduce (out : <collection>,query : <document >,sort : <document >,limit : <number>,finalize : <function >,scope : <document >,jsMode : <boolean>,verbose : <boolean>,bypassDocumentValidation : <boolean>
map,将数据拆分成键值对,交给reduce函数
reduce,根据键将值做统计运算
out,可选,将结果汇入指定表
quey,可选筛选数据的条件,筛选的数据送入map
sort,排序完后,送入map视图
limit,限制送入map的文档数
finalize,可选,修改reduce的结果后进行输出
scope,可选,指定map、reduce、finalize的全局变量
jsMode,可选,默认false。在mapreduce过程中是否将数据转换成bson格式。
verbose,可选,是否在结果中显示时间,默认false
bypassDocmentValidation,可选,是否略过数据校验
用法
测试数据
1 2 3 4 5 6 7 8 9 10 11 12 db.orders .insertMany ([_id : 1 , cust_id : "Ant O. Knee" , ord_date : new Date ("2020-03-01" ), price : 25 , items : [ { sku : "oranges" , qty : 5 , price : 2.5 }, { sku : "apples" , qty : 5 , price : 2.5 } ], status : "A" },_id : 2 , cust_id : "Ant O. Knee" , ord_date : new Date ("2020-03-08" ), price : 70 , items : [ { sku : "oranges" , qty : 8 , price : 2.5 }, { sku : "chocolates" , qty : 5 , price : 10 } ], status : "A" },_id : 3 , cust_id : "Busby Bee" , ord_date : new Date ("2020-03-08" ), price : 50 , items : [ { sku : "oranges" , qty : 10 , price : 2.5 }, { sku : "pears" , qty : 10 , price : 2.5 } ], status : "A" },_id : 4 , cust_id : "Busby Bee" , ord_date : new Date ("2020-03-18" ), price : 25 , items : [ { sku : "oranges" , qty : 10 , price : 2.5 } ], status : "A" },_id : 5 , cust_id : "Busby Bee" , ord_date : new Date ("2020-03-19" ), price : 50 , items : [ { sku : "chocolates" , qty : 5 , price : 10 } ], status : "A" },_id : 6 , cust_id : "Cam Elot" , ord_date : new Date ("2020-03-19" ), price : 35 , items : [ { sku : "carrots" , qty : 10 , price : 1.0 }, { sku : "apples" , qty : 10 , price : 2.5 } ], status : "A" },_id : 7 , cust_id : "Cam Elot" , ord_date : new Date ("2020-03-20" ), price : 25 , items : [ { sku : "oranges" , qty : 10 , price : 2.5 } ], status : "A" },_id : 8 , cust_id : "Don Quis" , ord_date : new Date ("2020-03-20" ), price : 75 , items : [ { sku : "chocolates" , qty : 5 , price : 10 }, { sku : "apples" , qty : 10 , price : 2.5 } ], status : "A" },_id : 9 , cust_id : "Don Quis" , ord_date : new Date ("2020-03-20" ), price : 55 , items : [ { sku : "carrots" , qty : 5 , price : 1.0 }, { sku : "apples" , qty : 10 , price : 2.5 }, { sku : "oranges" , qty : 10 , price : 2.5 } ], status : "A" },_id : 10 , cust_id : "Don Quis" , ord_date : new Date ("2020-03-23" ), price : 25 , items : [ { sku : "oranges" , qty : 10 , price : 2.5 } ], status : "A" }
求每位客户订单的总额
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 var mapFun = function (emit (this .cust_id , this .price );var reduceFun = function (cust_id, price ) {return Array .sum (price);orders .mapReduce (out : "map_reduce_example" }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 db.getCollection ('map_reduce_example' ).find ({})"_id" : "Don Quis" ,"value" : 155.0 "_id" : "Cam Elot" ,"value" : 60.0 "_id" : "Busby Bee" ,"value" : 125.0 "_id" : "Ant O. Knee" ,"value" : 95.0
只读
MongoDB 视图是一个只读的可查询对象,其内容由其他集合或视图上的聚合管道定义,通过视图进行写操作会报错
MongoDB不会将视图内容保存到磁盘。当客户端查询视图时,将按需计算视图的内容
视图种类
MongoDB提供两种不同的视图类型:标准视图和物化视图。这两种视图类型都从聚合管道返回结果
标准视图是在读取视图时计算的,不会存储到磁盘(和mysql一样,对查询进行封装) 视图存储在磁盘上并从磁盘读取。他们使用 $merge$out 物化视图
物化视图 (Materialized Views)是一种预计算和存储查询结果的数据结构。它们类似于传统数据库中的视图,但与视图不同,物化视图会将查询结果实际存储在磁盘上,而不是每次查询时动态计算。
MongoDB 4.2 版本引入了物化视图的概念。使用物化视图,您可以定义一个查询,并将其结果存储在集合中。这样,当数据发生变化时,您可以通过刷新物化视图来更新存储的查询结果,而不需要重新执行整个查询。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 sourceCollection .insertMany ([_id : 1 ,: "John" , age : 25 },_id : 2 ,: "Jane" , age : 30 },_id : 3 , name : "Bob" , age : 35 }var pipeline = [$match : { age : { $gte : 30 } } },$project : { _id : 0 ,: 1 } }createView ("myMaterializedView" , "sourceCollection" , pipeline);myMaterializedView .refresh ();
索引
标准视图使用基础集合的索引。因此,您无法直接在标准视图上创建、删除或重新生成索引,也无法在视图上获取索引列表 可以直接在物化视图上创建索引,因为它们存储在磁盘上 语法
1 2 3 4 5 6 7 8 db.createView ("<viewName>" , "<source>" , "collation" : { <collation> }
限制
创建单集合视图
测试数据
1 2 3 4 5 6 7 8 9 10 db.students .insertMany ( [sID : 22001 , name : "Alex" , year : 1 , score : 4.0 },sID : 21001 , name : "bernie" , year : 2 , score : 3.7 },sID : 20010 , name : "Chris" , year : 3 , score : 2.5 },sID : 22021 , name : "Drew" , year : 1 , score : 3.2 },sID : 17301 , name : "harley" , year : 6 , score : 3.1 },sID : 21022 , name : "Farmer" , year : 1 , score : 2.2 },sID : 20020 , name : "george" , year : 3 , score : 2.8 },sID : 18020 , name : "Harley" , year : 5 , score : 2.8 },
创建一个只有一年级学生的视图
1 2 3 4 5 6 7 8 db.createView ("firstYear" , "students" , $match : { year : 1 } }, $sort : { score : 1 } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 db.firstYear .find ({})"_id" : ObjectId ("64552b676378f2a57f74e957" ),"sID" : 21022.0 ,"name" : "Farmer" ,"year" : 1.0 ,"score" : 2.2 "_id" : ObjectId ("64552b676378f2a57f74e955" ),"sID" : 22021.0 ,"name" : "Drew" ,"year" : 1.0 ,"score" : 3.2 "_id" : ObjectId ("64552b676378f2a57f74e952" ),"sID" : 22001.0 ,"name" : "Alex" ,"year" : 1.0 ,"score" : 4.0
创建多集合的视图
测试数据
1 2 3 4 5 db.orders .insertMany ( ["_id" : 1 , "item" : "almonds" , "price" : 12 , "quantity" : 2 },"_id" : 2 , "item" : "pecans" , "price" : 20 , "quantity" : 1 },"_id" : 3 }
1 2 3 4 5 6 7 8 db.inventory .insertMany ( ["_id" : 1 , "sku" : "almonds" , "description" : "product 1" , "instock" : 120 },"_id" : 2 , "sku" : "bread" , "description" : "product 2" , "instock" : 80 },"_id" : 3 , "sku" : "cashews" , "description" : "product 3" , "instock" : 60 },"_id" : 4 , "sku" : "pecans" , "description" : "product 4" , "instock" : 70 },"_id" : 5 , "sku" : null , "description" : "Incomplete" },"_id" : 6 }
创建一个视图,使用 orders 的 item 字段关联 inventory 集合的 sku ,并输出 item 和 sku 字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 db.createView ("orderDetail" ,"orders" ,$lookup : { from : "inventory" , localField : "item" , foreignField :"sku" , as : "product" }$project : { item :1 , "product.sku" :1 }getCollection ('orderDetail' ).find ({})"_id" : 1.0 ,"item" : "almonds" ,"product" : [ "sku" : "almonds" "_id" : 2.0 ,"item" : "pecans" ,"product" : [ "sku" : "pecans" "_id" : 3.0 ,"product" : [ "sku" : null
1 2 3 4 5 db.runCommand ( {collMod : "lowStock" , viewOn : "products" , "pipeline" : []
测试数据
1 2 3 4 5 6 7 8 9 10 db.students .insertMany ( [sID : 22001 , name : "Alex" , year : 1 , score : 4.0 },sID : 21001 , name : "bernie" , year : 2 , score : 3.7 },sID : 20010 , name : "Chris" , year : 3 , score : 2.5 },sID : 22021 , name : "Drew" , year : 1 , score : 3.2 },sID : 17301 , name : "harley" , year : 6 , score : 3.1 },sID : 21022 , name : "Farmer" , year : 1 , score : 2.2 },sID : 20020 , name : "george" , year : 3 , score : 2.8 },sID : 18020 , name : "Harley" , year : 5 , score : 2.8 },
创建一张只包含1年级学生的视图
1 2 3 4 5 db.createView ("studentsView" ,"students" ,$match : { year : 1 } } ]
视图修改,改为只包含2年级学生的视图
1 2 3 4 5 6 7 db.runCommand (collMod : "studentsView" ,viewOn : "students" ,pipeline : [ { $match : { year : 2 } } ]
索引支持在MongoDB中高效执行查询。如果没有索引,MongoDB必须执行集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。如果查询存在适当的索引,MongoDB可以使用该索引来限制它必须检查的文档数量
索引是特殊的数据结构(B+树,官网说的B树实际上是文化差异,老外认为B+树是B树的变种) ,它以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段值排序。索引条目的排序支持高效的相等匹配和基于范围的查询操作。此外,MongoDB可以使用索引中的排序返回排序结果
从根本上说,MongoDB中的索引类似于其他数据库系统中的索引。MongoDB在集合级别定义索引,并支持MongoDB集合中文档的任何字段或子字段上的索引
默认 _id 索引
MongoDB在创建集合期间在 _id 字段上创建一个 唯一索引。 _id 索引可防止客户端为 _id 字段插入两个具有相同值的文档。不能将 _id 字段的索引删除
在分片集群中,如果你不使用 _id 字段作为分片键,那么你的应用程序必须确保 _id 字段中值的唯一性以防止错误。这通常是通过使用标准的自动生成的 ObjectId 来完成的
创建索引
要在 Mongo Shell 中创建索引,请使用 db.collection.createIndex()
1 db.collection .createIndex ( <key and index type specification>, <options> )
参考索引属性
1 db.collection .createIndex ( { name : -1 } )
索引名称
索引的默认名称是索引键和索引中每个键排序(即 1 或 -1)的串联,使用下划线作为分隔符。例如,在 { item : 1, quantity: -1 } 上创建的索引的名称为 item_1_quantity_-1
可以自定义索引名称
1 2 3 4 db.products .createIndex (item : 1 , quantity : -1 } ,name : "query for inventory" }
查看索引
1 2 查看索引信息 db.books .getIndexes () books .getIndexKeys ()
查看索引占用空间
1 db.collection .totalIndexSize ([is_detail])
is_detail:可选参数,传入除0或false外的任意数据,都会显示该集合中每个索引的大小及总大小。如果传入0或false则只显示该集合中所有索引的总大小。默认值为false
删除索引
1 2 删除集合指定索引 db.col .dropIndex ("索引名称" )col .dropIndexes ()
MongoDB提供了许多不同的索引类型来支持特定类型的数据和查询
MongoDB为文档集合中任何字段的索引提供了完整的支持。默认情况下,所有集合在 _id 字段上都有一个索引,应用程序和用户可以添加其他索引来支持重要的查询和操作
创建一个单字段索引
1 db.records .createIndex ( { score : 1 } )
在嵌套字段建立索引
测试数据
1 2 3 4 5 6 7 db.records .insertOne ("_id" : ObjectId ("570c04a4ad233577f97dc459" ),"score" : 1034 ,"location" : { state : "NY" , city : "New York" }
以下操作在 location.state 字段上创建索引:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 db.records .createIndex ({"location.state" : 1 })records .getIndexKeys ()"_id" : 1 "location.state" : 1.0
在嵌套文档上创建索引
支持对整个嵌套文档创建索引
location 字段是一个嵌套文档,包含嵌入字段 city 和 state 。以下命令在整个 location 字段上创建索引:
1 db.records .createIndex ( { location : 1 } )
复合索引是多个字段组合而成的索引,其性质和单字段索引类似。但不同的是,复合索引中字段的顺序、字段的升降序对查询性能有直接的影响,因此在设计复合索引时则需要考虑不同的查询场景
MongoDB对任何复合索引施加了32个字段的限制
创建索引
测试数据
1 2 3 4 5 6 7 8 9 10 db.products .insertOne ("_id" : 1 ,"item" : "Banana" ,"category" : ["food" , "produce" , "grocery" ],"location" : "4th Street Store" ,"stock" : 4 ,"type" : "cases"
以下操作在 item 和 stock 字段上分别创建升序和降序索引:
1 2 3 4 5 6 db.products .createIndex (item : 1 ,stock : -1
复合索引和SQL一样,在使用时需要遵循 最左匹配原则,并且复合索引的排序要根据业务查询的实际排序为准
多键索引范围
在 数组 的属性上建立索引。MongoDB为数组中的每个元素创建一个索引键。这些多键索引支持对数组字段进行高效查询
索引基本数组
测试数据
1 2 3 db.survey .insertOne (_id : 1 , item : "ABC" , ratings : [ 2 , 5 , 9 ], range : [8 , 10 , 15 ] }
为数组字段 ratings 创建多键索引
1 2 3 4 5 db.survey .createIndex (ratings : 1
由于 ratings 字段包含一个数组,因此 ratings 上的索引是多键的。多键索引包含以下三个索引键,每个索引键指向同一文档:
注意
对于一个复合索引而言,一个索引文档只能包含一个多键索引(一个基本数组类型的字段索引),否则创建索引会报错
1 2 3 4 5 6 7 8 9 10 11 12 13 db.survey .createIndex ( { ratings: 1 , range: 1 } "ok" : 0.0 ,"errmsg" : "Index build failed: 9a1ff53c-5550-4315-a94f-74998bd81ab4: Collection test.survey ( 6d437930-01ee-4911-82e5-a3653088c692 ) :: caused by :: cannot index parallel arrays [range] [ratings]" ,"code" : 171 ,"codeName" : "CannotIndexParallelArrays"
索引嵌套文档数组
测试数据
1 2 3 4 5 6 7 8 9 10 11 db.inventory .insertOne (_id : 1 ,item : "abc" ,stock : [size : "S" , color : "red" , quantity : 25 },size : "S" , color : "blue" , quantity : 10 },size : "M" , color : "blue" , quantity : 50 }
以下操作在 stock.size 和 stock.quantity 字段上创建多键索引:
1 2 3 4 5 6 db.inventory .createIndex ("stock.size" : 1 ,"stock.quantity" : 1
复合多键索引可以支持具有谓词的查询,这些谓词既包括索引字段,也包括仅包括索引前缀 stock.size 的谓词。如以下例子所示:
1 2 db.inventory .find ( { "stock.size" : "M" } )inventory .find ( { "stock.size" : "S" , "stock.quantity" : { $gt : 20 } } )
一个集合只能有一个文本搜索索引,但该索引可以涵盖多个字段
MongoDB的文本索引功能存在诸多限制,而官方并未提供中文分词的功能,这使得该功能的应用场景十分受限
用法
1 db.reviews .createIndex ( { comments : "text" , description : "text" } )
测试数据
1 2 3 4 5 6 7 8 9 10 db.inventory .insertMany (_id : 1 , dept : "tech" , description : "lime green computer" },_id : 2 , dept : "tech" , description : "wireless red mouse" },_id : 3 , dept : "kitchen" , description : "green placemat" },_id : 4 , dept : "kitchen" , description : "red peeler" },_id : 5 , dept : "food" , description : "green apple" },_id : 6 , dept : "food" , description : "red potato" }
为 description 字段创建文本索引
1 2 3 db.inventory.createIndex("text" }
使用文本索引搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 db.inventory .find ($text : { $search : "green" }"_id" : 5.0 ,"dept" : "food" ,"description" : "green apple" "_id" : 3.0 ,"dept" : "kitchen" ,"description" : "green placemat" "_id" : 1.0 ,"dept" : "tech" ,"description" : "lime green computer"
$text 操作符可以在有text index的集合上执行文本检索。$text 将会使用 空格 和 标点符号 作为分隔符对检索字符串进行分词(查询条件和索引数据都会分词), 并且对检索字符串中所有的分词结果进行一个逻辑上的 OR 操作
MongoDB支持在一个或一组字段上创建索引,以支持查询。由于MongoDB支持动态模式(动态添加字段),应用程序可以查询不能提前知道名称或任意名称的字段
例如, product_catalog 集合中的文档可能包含 product_attributes 字段。 product_attributes 字段可以包含任意嵌套字段,包括嵌入的文档和数组:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 db.product_catalog .insertMany ("product_name" : "Spy Coat" ,"product_attributes" : {"material" : [ "Tweed" , "Wool" , "Leather" ],"size" : {"length" : 72 ,"units" : "inches" "product_name" : "Spy Pen" ,"product_attributes" : {"colors" : [ "Blue" , "Black" ],"secret_feature" : {"name" : "laser" ,"power" : "1000" ,"units" : "watts" ,
以下操作在 product_attributes 字段上创建通配符索引:
1 2 3 db.product_catalog .createIndex ("product_attributes.$**" : 1 }
通配符索引可以支持对 product_attributes 或其嵌入字段进行 任意单字段 查询:
1 2 3 db.products_catalog .find ( { "product_attributes.size.length" : { $gt : 60 } } )products_catalog .find ( { "product_attributes.material" : "Leather" } )products_catalog .find ( { "product_attributes.secret_feature.name" : "laser" } )
使用限制
不能使用通配符索引来分片集合。在要分片的一个或多个字段上创建一个非通配符索引 不能创建复合索引 不能为通配符索引指定以下属性: 您不能使用通配符语法创建以下索引类型: 不同于传统的B+Tree索引,哈希索引使用hash函数来创建索引。在索引字段上进行 精确匹配,但不支持 范围查询 ,不支持 多键hash
使用散列分片键对集合进行分片会导致数据分布更均匀。有关更多详细信息,请参阅 哈希分片
Hashed索引使用hashing函数来计算索引字段值的哈希。hashing函数折叠嵌入式文档并计算整个值的hash,但不支持多键(即数组)索引
创建哈希索引
若要创建哈希索引,请指定 hashed 作为索引键的值,如以下示例所示:
1 db.collection .createIndex ( { _id : "hashed" } )
创建复合哈希索引
从MongoDB 4.4开始,MongoDB支持创建包含 单个哈希字段 的复合索引。若要创建复合哈希索引,请在创建索引时指定 hashed 作为任何单个索引键的值:
1 db.collection .createIndex ( { "fieldA" : 1 , "fieldB" : "hashed" , "fieldC" : -1 } )
TODO
Option Type 描述 background Boolean 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 unique Boolean 建立的索引是否唯一。指定为true创建唯一索引。默认值为false name string 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称 dropDups Boolean 3.0+版本已废弃。在建立唯一索引时是否删除重复记 录,指定 true 创建唯一索引。默认值为 false sparse Boolean 对文档中不存在的字段数据不启用索引;这个参数需 要特别注意,如果设置为true的话,在索引字段中不 会查询出不包含对应字段的文档.。默认值为 false expireAfterSeconds integer 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间 v index version 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本 weights document 索引权重值,数值在 1 到 99,999 之间,表示该索引 相对于其他索引字段的得分权重 default_language string 对于文本索引,该参数决定了停用词及词干和词器的 规则的列表。 默认为英语 language_override string 对于文本索引,该参数指定了包含在文档中的字段 名,语言覆盖默认的language,默认值为 language
唯一索引可确保索引字段不存储重复值;即强制索引字段的唯一性。默认情况下,MongoDB 在创建集合期间在 _id 字段上创建一个唯一索引
创建唯一索引
1 db.members .createIndex ( { "user_id" : 1 }, { unique : true } )
限制
如果集合字段已经有重复值,则MongoDB无法在指定的索引字段上创建唯一索引(同一字段有重复值) 不能对 哈希索引 指定唯一约束 缺失字段
唯一性索引对于文档中缺失的字段,会使用null值代替,因此不允许存在多个文档缺失索引字段的情况
例如,集合在 x 上具有唯一索引:
1 db.collection .createIndex ( { "x" : 1 }, { unique : true } )
如果集合尚未包含缺少字段 x 的文档,则唯一索引允许插入不带字段 x 的文档:
1 db.collection .insertOne ( { y : 1 } )
但是,如果集合已包含缺少字段 x 的文档,则插入没有字段 x 的文档时会出现唯一索引错误:
1 2 db.collection .insertOne ( { z : 1 } )
创建复合唯一索引
1 db.collection .createIndex ( { "a.loc" : 1 , "a.qty" : 1 }, { unique : true } )
在复制集和分片上建立唯一索引
对于副本集和分片集群,使用 rolling procedure (滚动过程) 创建唯一索引需要在过程中停止对集合的所有写操作。如果在此过程中无法停止对集合的所有写入,请不要使用滚动过程。相反,请通过以下方式在集合上构建唯一索引:
在副本集的主数据库上调用 db.collection.createIndex() 或者,在分片集群的 mongos 上调用 db.collection.createIndex() 分片集群和唯一索引
对于范围分片集合,只有以下索引是唯一的:
分片键上的索引 一个复合索引,其中分片键是一个 前缀 (分片键必须作为唯一索引的前缀) 默认 _id 索引;但是如果 _id 字段不是分片键或分片键的前缀,则 _id 索引仅强制实施每个分片的唯一性约束 部分索引只索引集合中满足指定筛选器表达式的文档。通过索引集合中文档的子集,部分索引可以降低存储需求,并降低创建和维护索引的性能成本
使用 db.collection.createIndex() 方法与 partialFilterExpression 选项一起使用创建部分索引,partialFilterExpression 选项接受使用以下方法指定筛选条件的文档:
部分索引生效必须满足 partialFilterExpression
1 2 3 4 5 6 7 db.users .insertMany ("_id" : ObjectId ("56424f1efa0358a27fa1f99a" ), "username" : "david" , "age" : 29 },"_id" : ObjectId ("56424f37fa0358a27fa1f99b" ), "username" : "amanda" , "age" : 35 },"_id" : ObjectId ("56424fe2fa0358a27fa1f99c" ), "username" : "rajiv" , "age" : 57 }
1 2 3 4 db.users .createIndex (username : 1 }, partialFilterExpression : { age : { $gt : 30 } } }
以下查询将使用部分索引
1 2 3 db.users .find (username : "david" , age : 35 }
以下查询不会使用部分索引
1 2 3 db.users .find (username : "rajiv" }
因为查询条件没有满足或缺失满足部分索引的 partialFilterExpression 条件,则不使用部分索引
部分索引导致唯一索引失效
分部索引仅索引集合中满足指定筛选表达式的文档。如果同时指定 partialFilterExpression 和唯一约束,则唯一约束仅适用于满足筛选表达式的文档。如果文档不符合筛选条件,则具有唯一约束的部分索引不会阻止插入不符合唯一约束的文档
引用上面的测试数据,假设 users 创建一个索引
1 2 3 4 db.users .createIndex (username : 1 },unique : true , partialFilterExpression : { age : { $gte : 30 } } }
那么这个部分唯一索引对于 age 大于等于30的数据可以保证 username 唯一,但是 age 小于30则不保证 username 唯一
索引的稀疏属性确保索引只包含具有索引字段的文档的条目,索引将跳过没有索引字段的文档
特性: 只对存在字段的文档进行索引(包括字段值为null的文档)
集合上的稀疏索引无法返回完整结果
1 2 3 4 5 6 7 db.score .insertMany ("_id" : ObjectId ("523b6e32fb408eea0eec2647" ), "userid" : "newbie" },"_id" : ObjectId ("523b6e61fb408eea0eec2648" ), "userid" : "abby" , "score" : 82 },"_id" : ObjectId ("523b6e6ffb408eea0eec2649" ), "userid" : "nina" , "score" : 90 }
创建一个稀疏索引
1 db.score .createIndex ( { score : 1 } , { sparse : true } )
下面查询不会返回 userid 为 newbie 的文档,因为强制使用了稀疏索引,该文档没有 score字段,不会被加入索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 db.score .find ().sort ( { score : -1 } ).hint ( {score : 1 } )"_id" : ObjectId ("523b6e6ffb408eea0eec2649" ),"userid" : "nina" ,"score" : 90.0 "_id" : ObjectId ("523b6e61fb408eea0eec2648" ),"userid" : "abby" ,"score" : 82.0
需要返回完整的查询结果就不能暗示使用稀疏索引
1 db.score .find ().sort ( { score : -1 } )
具有唯一约束的稀疏索引
可以使用以下命令创建具有唯一约束的稀疏索引
1 db.score .createIndex ( { score : 1 } , { sparse : true , unique : true } )
以下数据可以插入到集合中
1 2 3 4 5 db.score .insertMany ( ["userid" : "newbie" , "score" : 43 },"userid" : "abby" , "score" : 34 },"userid" : "nina" }
以下数据不能插入到集合中,因为 score 值为 82 和 90 的文档已经存在:
1 2 3 4 db.score .insertMany ( ["userid" : "newbie" , "score" : 82 },"userid" : "abby" , "score" : 90 }
通过设置TTL使集合中的数据过期
TTL索引是一种特殊的 单字段索引,MongoDB可以使用它在一定的时间或特定的时钟时间后自动从集合中删除文档。数据过期对于某些类型的信息很有用,比如机器生成的事件数据、日志和会话信息,这些信息只需要在数据库中保存有限的时间
测试数据
创建一个 user 集合,根据 createTime 创建一个TTL索引,数据在10秒后过期
1 db.user .createIndex ( { "createTime" : 1 }, { expireAfterSeconds : 10 } )
插入一条用户数据,数据将在10秒后自动删除
1 2 3 4 5 6 7 8 db.user .insertOne ("_id" : ObjectId ("56424f1efa0358a27fa1f99a" ),"username" : "david" ,"createTime" : new Date ()
通过对规划器隐藏索引,用户可以评估删除索引而不实际删除索引的潜在影响。如果影响是负面的,用户可以取消隐藏索引,而不必重新创建已删除的索引
1 2 3 4 5 6 7 8 9 10 11 12 创建隐藏索引 restaurants .createIndex ({ fileName : 1 },{ hidden : true });restaurants .hideIndex ( { fileName : 1 } );restaurants .hideIndex ( "索引名称" ) restaurants .unhideIndex ( { fileName : 1 } ); restaurants .unhideIndex ( "索引名称" );
为每一个查询建立合适的索引
这个是针对于数据量较大比如说超过几十上百万(文档数目)数量级的集合。如果没有索引MongoDB需要把所有的Document从盘上读到内存,这会对MongoDB服务器造成较大的压力并影响到其他请求的执行。
创建合适的复合索引,不要依赖于交叉索引
如果你的查询会使用到多个字段,MongoDB有两个索引技术可以使用:交叉索引和复合索引。交叉索引就是针对每个字段单独建立一个单字段索引,然后在查询执行时候使用相应的单字段索引进行索引交叉而得到查询结果。交叉索引目前触发率较低,所以如果你有一个多字段查询的时候,建议使用复合索引能够保证索引正常的使用。
复合索引字段顺序:匹配条件在前,范围条件在后
Equality First, Range After
前面的例子,在创建复合索引时如果条件有匹配和范围之分,那么匹配条件(sport: “marathon”) 应该在复合索引的前面。范围条件(age: <30)字段应该放在复合索引的后面,使用复合索引也要遵循最左匹配原则。
尽可能使用覆盖索引
使用索引覆盖的好处是查询的数据在索引上都能获取到,直接查询索引后返回数据,提高查询效率。
建索引要在后台运行
在对一个集合创建索引时,该集合所在的数据库将不接受其他读写操作。对大数据量的集合建索引,建议使用后台运行选项 {background: true}
Pom配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <dependencies>true </optional>
yml配置
1 2 3 4 5 6 7 8 9 10 11 server: port: 9090 spring: data: mongodb: host: 127.0 .0 .1 port: 27017 username: test password: 123456 database: test
Mongo配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @Configuration @RequiredArgsConstructor public class MongoConfig {private final MongoDatabaseFactory mongoDbFactory;private final MongoMappingContext mongoMappingContext;@Bean public MappingMongoConverter mappingMongoConverter () {DbRefResolver dbRefResolver = new DefaultDbRefResolver (mongoDbFactory);MappingMongoConverter converter = new MappingMongoConverter (dbRefResolver, mongoMappingContext);new DefaultMongoTypeMapper (null ));return converter;@Bean public MongoTransactionManager mongoTransactionManager (MongoDatabaseFactory mongoDatabaseFactory) {TransactionOptions transactionOptions = TransactionOptions.builder().readConcern(ReadConcern.SNAPSHOT).writeConcern(WriteConcern.MAJORITY).build();return new MongoTransactionManager (mongoDatabaseFactory, transactionOptions);
实体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Data @ToString @Accessors(chain = true) @Document(collection = "product") public class Product {@MongoId private ObjectId id;private String productName;private BigDecimal price;private Integer num;
VO
1 2 3 4 5 6 7 @Data public class ProductAggVo {@MongoId private ObjectId id;private Integer total;
单元测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 @Slf4j @SpringBootTest public class CURDTest {@Autowired private MongoTemplate mongoTemplate;@Test public void insertTest () {new ArrayList <>();new Product ()"iphone 14" )new BigDecimal ("1234" ))5 ));new Product ()"iphone 15" )new BigDecimal ("2134" ))6 ));new Product ()"iphone xiaomi" )new BigDecimal ("3333" ))7 ));this .mongoTemplate.insert(productList, Product.class);@Test public void selectTest () {Query query = new Query (Criteria.where("productName" ).is("iphone 14" ));Product product = this .mongoTemplate.findOne(query, Product.class);@Test public void updateTest () {Query query = new Query (Criteria.where("productName" ).is("iphone 14" ));Update update = new Update ().inc("num" , 1 );UpdateResult updateResult = this .mongoTemplate.updateFirst(query, update, Product.class);@Test public void removeTest () {Query query = new Query (Criteria.where("productName" ).is("iphone 14" ));DeleteResult deleteResult = this .mongoTemplate.remove(query, Product.class);@Test public void aggTest () {MatchOperation match = Aggregation.match(Criteria.where("num" ).gte(6 ));GroupOperation group = Aggregation.group("_id" ).sum("$num" ).as("total" );Aggregation aggregation = Aggregation.newAggregation(this .mongoTemplate.aggregate(aggregation, Product.class, ProductAggVo.class);
存储引擎是数据库的组成部分,负责管理数据在内存和磁盘上的存储方式。MongoDB支持多个存储引擎,因为不同的引擎对特定的工作负载性能更好。
WiredTiger 是MongoDB 3.2开始的默认存储引擎。它非常适用于大多数工作负载,并且推荐在新部署中使用。WiredTiger提供了文档级的并发模型、检查点和压缩等功能。
内存存储引擎在MongoDB 商业版中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中,以实现更可预测的数据延迟。
从MongoDB 3.2开始,WiredTiger存储引擎是默认的存储引擎。
文档级并发
WiredTiger 使用文档级并发控制进行写入操作。因此,多个客户端可以同时修改集合的不同文档。
对于大多数读写操作,WiredTiger使用 乐观并发 控制模式。 WiredTiger仅在全局、数据库和集合级别使用意向锁。
当存储引擎检测到两个操作之间存在冲突时,将引发写冲突,从而导致MongoDB自动重试该操作。
一些全局操作(通常是涉及多个数据库的短暂操作)仍然需要全局“实例范围级别的”锁。 其他一些操作(例如删除集合)仍然需要独占数据库锁。
内存快照和检查点
WiredTiger 存储引擎使用 MVCC(多版本并发控制)技术。在进行操作时,WiredTiger 为操作提供数据的一个时间点快照。快照提供了内存中数据的一致视图。
写入磁盘时,WiredTiger将所有数据文件中的快照中的所有数据以一致的方式写入磁盘。 现在持久的数据充当数据文件中的 检查点。 该检查点可确保数据文件直到最后一个检查点(包括最后一个检查点)都保持一致; 即检查点可以充当恢复点。
从3.6版本开始,MongoDB将WiredTiger配置为以 60秒 的间隔创建 检查点(即将内存快照数据写入磁盘)。 在早期版本中,MongoDB将检查点设置为在WiredTiger中以60秒的间隔或在写入 2GB 日志数据时对用户数据进行检查,以先到者为准。
在写入新检查点期间,以前的检查点仍然有效。因此,即使MongoDB在写入新检查点时终止或遇到错误,在重新启动时,MongoDB也可以从上一个有效的检查点恢复。
当 WiredTiger 的元数据表以原子方式更新以引用新检查点时,当新的检查点可用户时。一旦可以访问新的检查点,WiredTiger 就会从旧检查点中释放内存page。
使用WiredTiger,即使没有日志,MongoDB也可以从最后一个检查点恢复;但是,若要恢复在最后一个检查点之后所做的更改,请使用日记功能运行。
检查点
检查点是指定时将内存中的数据写入到磁盘中并创建一个检查点文件用于数据恢复的操作
Journal(日志)
写入关注的 j 选项 可以控制 mongodb 必须要成功写入 Journal 才返回
WiredTiger 将预写日志(即 journal)与检查点结合使用,以确保数据的持久性。
WiredTiger 日志(journal)保留检查点之间的所有数据修改。如果MongoDB在检查点之间宕机,它将使用日志重放自上次检查点以来修改的所有数据。
WiredTiger 日志使用 snappy 压缩库进行压缩。若要指定不同的压缩算法或不压缩,请使用storage.wiredTiger.engineConfig.journalCompressor 设置(超过128M才会开启压缩)。
可以通过将 storage.journal.enabled 设置为 false 来禁用独立实例的日记功能,这可以减少维护日志的开销。对于独立实例,不使用日志意味着当MongoDB意外宕机时,最后一个检查点后面的数据会丢失。
压缩
使用WiredTiger,MongoDB支持对所有集合和索引进行压缩。 压缩可最大程度地减少存储空间的使用量,但会增加CPU的开销。
默认情况下,WiredTiger 对所有集合使用块压缩和 snappy 压缩库,对所有索引使用前缀压缩。
对于集合,可选的压缩库有
对于索引,若要禁用前缀压缩,请使用 storage.wiredTiger.indexConfig.prefixCompression 设置。
压缩设置还可以在集合和索引创建期间基于每个集合和每个索引进行配置。
内存使用
使用WiredTiger,MongoDB同时利用WiredTiger内部缓存和文件系统缓存。
从MongoDB 3.4开始,默认的WiredTiger内部缓存大小是以下两者中的较大者:
例如,在总共具有 4GB RAM 的系统上,WiredTiger 缓存将使用 1.5GB 的 RAM ( 0.5 * (4 GB - 1 GB) = 1.5 GB )
相反,总内存为1.25 GB的系统将为WiredTiger缓存分配256 MB,因为这是总RAM的一半以上减去一GB(0.5* (1.25 GB-1 GB)= 128 MB
商业版本提供
GridFS是MongoDB提供的一种存储和检索大文件(如图片、视频等)的机制。它允许将一个大文件分割成多个小文件进行存储,并且可以方便地进行文件的读写操作。GridFS会自动处理文件的切分和重组(每个chunk 255KB),同时还可以提供基于文件名、类型、大小等条件进行搜索的功能。
GridFS 不仅可用于存储超过 16 MB 的文件,还可用于存储要访问的任何文件,而无需将整个文件加载到内存中。
使用场景
在MongoDB中,使用GridFS存储大于16 MB的文件。
在某些情况下,在MongoDB数据库中存储大文件可能比在系统级文件系统中更有效:
如果文件系统限制目录中的文件数,则可以使用 GridFS 根据需要存储任意数量的文件。 如果要访问大文件部分的信息,而不必将整个文件加载到内存中,则可以使用 GridFS 调用文件的各个部分,而无需将整个文件读入内存(比如视频)。 当你希望保持文件和元数据在多个系统和设施之间自动同步和部署时,可以使用GridFS。使用地理分布的复制集 时,MongoDB可以自动将文件及其元数据分发到多个mongod 实例和设施 如何使用
GridFS 将文件存储在两个集合中:
chunks 存储二进制块files 存储文件的元数据GridFS通过使用存储桶名称为每个集合添加前缀,将集合放置在一个公共存储桶中。默认情况下,GridFS使用两个集合以及一个名为fs的存储桶:
chunks 集合
chunks 集合中的每个文档都表示 GridFS 中表示的文件的不同块。
1 2 3 4 5 6 {"_id" : <ObjectId >,"files_id" : <ObjectId >,"n" : <num>,"data" : <binary>
字段 说明 chunks._id块的唯一ObjectId chunks.files_id“父”文档的 _id ,在 files 集合中指定 chunks.n区块的序列号。GridFS 对所有块进行编号,从 0 开始 chunks.dataBSON 二进制类型
files 集合
files 集合中的每个文档都表示 GridFS 中的一个文件
1 2 3 4 5 6 7 8 9 10 11 {"_id" : <ObjectId >,"length" : <num>,"chunkSize" : <num>,"uploadDate" : <timestamp>,"md5" : <hash>,"filename" : <string>,"contentType" : <string>,"aliases" : <string array>,
字段 描述 files._id 该文档的唯一标识符。 _id 是您为原始文档选择的数据类型。 MongoDB 文档的默认类型是 BSON ObjectId。 files.length 文件大小,以字节为单位。 files.chunkSize 每个块的大小,以字节为单位。 GridFS 将文档分成大小为 chunkSize 的块,除了最后一个块外,它只有所需的大小。 默认大小为 255kB。 files.uploadDate 文件首次被 GridFS 存储的日期。此值的类型为 Date。 files.md5 已弃用。 FIPS 140-2 禁止使用 MD5 算法。 MongoDB 驱动程序已弃用 MD5 支持,并将在未来版本中删除 MD5 生成。需要文件摘要的应用程序应在 GridFS 外部实现它并存储在 files.metadata 中。返回完整文件的 MD5 哈希由 filemd5 命令返回。此值的类型为 String。 files.filename 可选。适用于 GridFS 文件的人类可读名称。 files.contentType 已弃用。可选。适用于 GridFS 文件的有效 MIME 类型。仅供应用程序使用。请使用 files.metadata 存储与 GridFS 文件的 MIME 类型相关的信息。 files.aliases 已弃用。可选。别名字符串数组。仅供应用程序使用。请使用 files.metadata 存储与 GridFS 文件的 MIME 类型相关的信息。 files.metadata 可选。元数据字段可以是任何数据类型,并且可以保存您希望存储的任何其他信息。如果您希望向 files 集合中的文档添加其他任意字段,请将它们添加到 metadata 字段中的对象中。
添加文件
我们使用 GridFS 的 put 命令来存储 mp3 文件。 调用 MongoDB 安装目录下bin的 mongofiles 工具
1 mongofiles -d gridfs put song.mp3
-d gridfs 指定存储文件的数据库名称,如果不存在该数据库,MongoDB会自动创建。如果不存在该数据库,MongoDB会自动创建。Song.mp3 是音频文件名
切换数据库后查询文件
查询数据块
MongoDB中的副本集(Replica Set)是一组维护相同数据集的mongod服务。 副本集可提供 数据冗余 和 高可用性,是所有生产部署的基础。
也可以说,副本集类似于有自动故障恢复功能的主从集群。通俗的讲就是用多台机器进行同一数据的异步复制,从而使多台机器拥有同一数据的多个副本,并且当主库宕机时在不需要用户干预的情况下自动切换其他备份服务器做主库。而且还可以利用副本服务器做只读服务器,实现读写分离,提高负载。
冗余和数据可用性
复制提供冗余并提高数据可用性。 通过在不同数据库服务器上提供多个数据副本,复制提供了针对单个数据库服务器宕机的容错级别
在某些情况下,复制可以提高读取性能,因为客户端可以将读取操作发送到不同的服务上, 在不同数据中心维护数据副本可以增加分布式应用程序的数据位置和可用性。 您还可以为专用目的维护其他副本,例如灾难恢复,报告或备份。
MongoDB中的复制
副本集是一组维护相同数据集的 mongod 实例。副本集包含多个数据承载节点和一个可选的仲裁节点。在数据承载节点中,一个且只有一个成员被视为主节点,而其他节点被视为辅助节点。
主节点接收所有写入操作。一个副本集只能有一个能够确认具有 { w: "majority" } 写入关注的写入的主节点,尽管在某些情况下,另一个Mongod实例可能会暂时认为自己也是主节点(网络分区),主节点在其操作日志中记录其数据集的所有更改,记录 oplog .
辅助节点复制主节点的 oplog 并将操作应用于其数据集,完成辅助节点和主节点的数据同步。 如果主节点宕机,则在符合条件的副本节点中重新选举主节点。
主从复制和副本集区别
主从集群和副本集最大的区别就是副本集没有固定的 主节点 。整个集群会选出一个“主节点”,当其挂掉后,又在剩下的从节点中选中其他节点为“主节点”,副本集总有一个活跃点(主、primary)和一个或多个备份节点(从、secondary)。
副本集有两种类型三种角色
两种类型:
主节点:数据操作的主要连接点,可读写 辅助节点:数据冗余备份,可读或选举 三种角色
主节点负责所有写请求操作,然后主节点使用 oplog 记录写操作。 辅助节点复制 oplog 完成数据同步
主节点宕机。会触发新一轮主节点选举,会从辅助节点中重新选举出一个新的主节点
辅助节点维护主节点的数据副本。辅助节点使用主节点的 oplog 将数据从主节点复制本辅助节点,当主节点宕机辅助节点有机会晋升为主节点。
辅助节点不能进行写操作,通过额外配置后辅助节点可以进行读操作。
不同步任何数据的副本,只具有投票选举作用。当然也可以将仲裁节点维护为副本集的一部分,即副本节点同时也可以是仲裁节点。也是一种从节点类型
可以将额外的mongod实例添加到副本集作为仲裁节点。 仲裁节点不维护数据集。 仲裁节点的目的是通过响应其他副本集成员的心跳和选举请求来维护副本集中的仲裁。 因为它们不存储数据集,所以仲裁器可以是提供副本集仲裁功能的好方法,其占用资源更低。
如果你的副本+主节点的个数是偶数,建议加一个仲裁节点,形成奇数,容易满足大多数的投票。
如果你的副本+主节点的个数是奇数,可以不加仲裁节点。
Oplog同步
oplog(操作日志)是一个特殊的 有限集合 ,它保留修改数据库中存储的数据的所有操作的滚动记录。
与其他有上限的集合不同,oplog 可以超过其配置的大小限制,避免误删提交点。
MongoDB的所有写操作请求都是在 主节点 上进行的,然后将这些操作记录到主节点的 oplog 上,最后 辅助节点 会以异步复制的方式同步这些日志(4.4后是推送模式)。所有副本集成员都包含一个 oplog 的副本,其位于local.oplog.rs
local.oplog.rs 是 MongoDB 中的一个特殊集合,用于支持复制和sharding。它存储了所有对MongoDB数据库进行更改的操作,包括插入、更新和删除等操作,这些操作都是通过primary节点执行的。每个secondary节点都会从primary节点获取并应用这些操作(回放),从而保证数据在各个节点上的一致性。
为了便于复制,所有副本集成员将心跳(ping)发送给所有其他成员。任何从节点都可以从任何其他节点导入oplog条目。
oplog中的每个操作都是 幂等 的。也就是说,oplog 操作无论应用于目标数据集一次还是多次,都会产生相同的结果。
为了确保不会重复复制操作,每个辅助节点在复制过程中会追踪自己已经复制和执行过的 oplog 条目的状态。每个副本集成员都有一个叫做 “复制进程 ID(replication processId)” 的标识符,用来标记已经复制过的 oplog 条目。当一个副本集成员读取主节点的 oplog 时,它会记住自己在最近的复制过程中读取的最后一个条目的复制进程 ID。下一次复制过程开始时,它会使用该复制进程 ID 作为起点,只复制新的操作
操作日志大小
默认操作日志大小
Unix和Windows系统
存储引擎 默认Oplog大小 下限 上限 In-Memory 物理内存的5% 50MB 50GB WiredTiger 可用磁盘空间的5% 990MB 50GB
macOS系统
存储引擎 默认Oplog大小 In-Memory 192MB物理内存 WiredTiger 192MB磁盘空间
在大多数情况下,默认的oplog大小就足够了。例如,如果一个oplog是空闲磁盘空间的5%,并且可容纳24小时的操作记录,那么从节点从oplog停止复制条目的时间可以长达24小时,并且不会因oplog条目变得太陈旧而无法继续复制
在 mongod 创建操作日志之前,可以使用 oplogSizeMBreplSetResizeOplog
要查看操作日志状态(包括操作的大小和时间范围),请使用rs.printReplicationInfo()Check the Size of the Oplog.
MongoDB在副本集中,会自动进行主节点的选举,主节点选举的触发条件:
主节点宕机 主节点网络抖动(默认心跳超时时间为10秒) 人工干预(rs.stepDown(600)) 一旦触发选举,就要根据一定规则来选主节点。
选举规则是根据票数来决定谁当选:
票数最高,且获得了半数以上票数的从节点当选主节点(N/2 + 1);当复制集内存活的成员数量不满足总节点半数以上的数量时,无法进行主节点选举,此时服务处于只读状态 若票数相同,且票数都满足总节点半数以上,数据新的节点当选;数据的新旧是通过操作日志 oplog 来对比的 优先级
在获得票数的时候,优先级(priority)参数影响重大,优先级默认为 1
可以通过设置优先级(priority)来设置额外票数。优先级即权重,取值为0-1000,相当于可额外增加0-1000的票数,优先级的值越大,就越可能获得多数成员的投票(votes)数。指定较高的值可使成员更有资格成为主节点
调整副本集成员的优先级
只有在主节点宕机之前进行了写操作并且写操作没有同步到副本节点时才需要回滚。当宕机的主节点以副本节点重新加入副本集时,它将回滚未完成同步的写操作,以确保和其他节点的数据保持一致.
MongoDB的读偏好选项是指在进行读取操作时,优先选择从哪个节点或副本集成员读取数据
读偏好选项 描述 primary 将读操作发送到主节点(Primary)。这是默认的读偏模式,适用于大多数情况。 PrimaryPreferred 首选将读操作发送到主节点(Primary),但如果主节点不可用,则可以从副本集中的任何成员读取数据。 Secondary 将读操作发送到副本集中的次要节点(Secondary)。这可以用分担主节点的读负载或现读扩展。 secondaryPreferred 首选将操作发送到副本中的次要节点(Secondary),但如果没有次要节点可用,则可以从主节点读取数据。 nearest 将读操作发送到距离客端最近的节点,无论其角色是主节点还次要节点。这个模式适用于需要最小读延迟的场景。
目标:一主一副本一仲裁
主节点
1 2 3 4 日志和数据目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 新建配置# mongod.conf # for documentation of all options, see:# http://docs.mongodb.org/manual/reference/configuration-options/ # Where and how to store data. # storage: # dbPath: /data/db # engine: # wiredTiger: # where to write logging data.# network interfaces # net: # port: 27017 # bindIp: 127.0.0.1 # how the process runs # processManagement: # timeZoneInfo: /usr/share/zoneinfo # 安全项先保持注释状态,配好集群后放开。mongo.key后面步骤里会有生成。 # security: # keyFile: /etc/mongo/mongo.key # authorization: enabled # operationProfiling: # 配副本集名 # sharding: # # auditLog: # snmp:
1 2 3 4 5 6 7 8 9 启动服务
副本节点
1 2 3 4 日志和数据目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 新建配置# mongod.conf # for documentation of all options, see:# http://docs.mongodb.org/manual/reference/configuration-options/ # Where and how to store data. # storage: # dbPath: /data/db # engine: # wiredTiger: # where to write logging data.# network interfaces # net: # port: 27017 # bindIp: 127.0.0.1 # how the process runs # processManagement: # timeZoneInfo: /usr/share/zoneinfo # 安全项先保持注释状态,配好集群后放开。mongo.key后面步骤里会有生成。 # security: # keyFile: /etc/mongo/mongo.key # authorization: enabled # operationProfiling: # 配副本集名 # sharding: # # auditLog: # snmp:
1 2 3 4 5 6 7 8 9 启动服务
仲裁节点
1 2 3 4 日志和数据目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 新建配置# mongod.conf # for documentation of all options, see:# http://docs.mongodb.org/manual/reference/configuration-options/ # Where and how to store data. # storage: # dbPath: /data/db # engine: # wiredTiger: # where to write logging data.# network interfaces # net: # port: 27017 # bindIp: 127.0.0.1 # how the process runs # processManagement: # timeZoneInfo: /usr/share/zoneinfo # 安全项先保持注释状态,配好集群后放开。mongo.key后面步骤里会有生成。 # security: # keyFile: /etc/mongo/mongo.key # authorization: enabled # operationProfiling: # 配副本集名 # sharding: # # auditLog: # snmp:
1 2 3 4 5 6 7 8 9 启动服务
添加节点和仲裁节点
添加,删除副本集节点参考 rs 命令
1 2 3 4 5 6 7 rs.initiate ({_id : "rs" ,members : [_id : 0 , host : "192.168.0.181:27020" },_id : 1 , host : "192.168.0.181:27021" },_id : 2 , host : "192.168.0.181:27022" , arbiterOnly : true }
查看集群状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 rs:PRIMARY> rs.status()
集群安全生成 key文件
在主节点上执行写操作
1 2 3 4 5 6 7 use test;rs :PRIMARY > db.user .insertOne ( { userName:"wgf" , sex:1 } )"acknowledged" : true ,"insertedId" : ObjectId ("645bc114a1d8b7b70ea2dbd0" )
在副本节点查询插入的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 rs :SECONDARY > db.user .find ({})Error : error : {"topologyVersion" : {"processId" : ObjectId ("645bbe1c68a22fb5732aef90" ),"counter" : NumberLong (4 )"ok" : 0 ,"errmsg" : "not master and slaveOk=false" , "code" : 13435 ,"codeName" : "NotPrimaryNoSecondaryOk" ,"$clusterTime" : {"clusterTime" : Timestamp (1683734919 , 1 ),"signature" : {"hash" : BinData (0 ,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ),"keyId" : NumberLong (0 )"operationTime" : Timestamp (1683734919 , 1 )
发现,不能读取集合的数据。当前从节点只是一个备份,不是奴隶节点,无法读取数据,写当然更不行。因为默认情况下,从节点是没有读写权限的,可以增加读的权限,但需要进行设置。
设置为奴隶节点
设置为奴隶节点,允许在从成员上运行读的操作
1 2 3 4 5 在副本节点执行slaveOk ()slaveOk (true )
再次在 奴隶节点 执行查询请求,数据已经被同步到副本节点
1 2 rs :SECONDARY > db.user .find ({} )"_id" : ObjectId ("645bc114a1d8b7b70ea2dbd0" ), "userName" : "wgf" , "sex" : 1 }
副本节点宕机
关闭 mongod_27021 节点
1 docker stop mongod_27021
主节点和仲裁节点对 mongod_27021 的心跳失败。因为主节点还在,因此,没有触发投票选举。
如果此时,在主节点写入数据,写入不受影响
1 2 3 4 5 db.user .insertOne ( { userName:"test" , age:30 } )"acknowledged" : true ,"insertedId" : ObjectId ("645c5203a79b5534f6f3e61a" )
重新启动 mongod_27021 节点
1 2 3 rs.slaveOk (true ) #设置为奴隶节点user .find ( { userName:"test" } )"_id" : ObjectId ("645c5203a79b5534f6f3e61a" ), "userName" : "test" , "age" : 30 }
再启动从节点,会发现,主节点写入的数据,会自动同步给从节点。
主节点宕机
关闭 mongod_27020 节点
1 docker stop mongod_27020
发现,从节点和仲裁节点对 mongod_27020的心跳失败,当失败超过10秒,此时因为没有主节点了,会自动发起投票。
mongod_27022 向 mongod_27021 投了一票,mongod_27021 本身自带一票,因此共两票,满足过半原则,mongod_27020 成为新主节点
1 2 3 4 5 6 7 8 9 # 连接新的主节点 # 插入数据
重新启动 mongod_27020 节点,发现其变成从节点,会向新的主节点重新同步数据
1 2 3 4 5 6 use test
服务降级
关闭仲裁节点和从节点
1 2 docker stop mongod_27020
登录 mongod_27021 节点,查看副本集状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 rs :SECONDARY > rs.status ("set" : "rs" ,"date" : ISODate ("2023-05-11T03:13:32.135Z" ),"myState" : 2 ,"term" : NumberLong (3 ),"syncSourceHost" : "" ,"syncSourceId" : -1 ,"heartbeatIntervalMillis" : NumberLong (2000 ),"majorityVoteCount" : 2 ,"writeMajorityCount" : 2 ,"votingMembersCount" : 3 ,"writableVotingMembersCount" : 2 ,"optimes" : {"lastCommittedOpTime" : {"ts" : Timestamp (1683774683 , 1 ),"t" : NumberLong (3 )"lastCommittedWallTime" : ISODate ("2023-05-11T03:11:23.552Z" ),"readConcernMajorityOpTime" : {"ts" : Timestamp (1683774683 , 1 ),"t" : NumberLong (3 )"appliedOpTime" : {"ts" : Timestamp (1683774703 , 1 ),"t" : NumberLong (3 )"durableOpTime" : {"ts" : Timestamp (1683774703 , 1 ),"t" : NumberLong (3 )"lastAppliedWallTime" : ISODate ("2023-05-11T03:11:43.552Z" ),"lastDurableWallTime" : ISODate ("2023-05-11T03:11:43.552Z" )"lastStableRecoveryTimestamp" : Timestamp (1683774683 , 1 ),"members" : ["_id" : 0 ,"name" : "192.168.0.181:27020" ,"health" : 0 ,"state" : 8 ,"stateStr" : "(not reachable/healthy)" ,"uptime" : 0 ,"optime" : {"ts" : Timestamp (0 , 0 ),"t" : NumberLong (-1 )"optimeDurable" : {"ts" : Timestamp (0 , 0 ),"t" : NumberLong (-1 )"optimeDate" : ISODate ("1970-01-01T00:00:00Z" ),"optimeDurableDate" : ISODate ("1970-01-01T00:00:00Z" ),"lastAppliedWallTime" : ISODate ("2023-05-11T03:11:23.552Z" ),"lastDurableWallTime" : ISODate ("2023-05-11T03:11:23.552Z" ),"lastHeartbeat" : ISODate ("2023-05-11T03:13:32.067Z" ),"lastHeartbeatRecv" : ISODate ("2023-05-11T03:11:25.994Z" ),"pingMs" : NumberLong (0 ),"lastHeartbeatMessage" : "Error connecting to 192.168.0.181:27020 :: caused by :: Connection refused" ,"syncSourceHost" : "" ,"syncSourceId" : -1 ,"infoMessage" : "" ,"configVersion" : 1 ,"configTerm" : 3 "_id" : 1 ,"name" : "192.168.0.181:27021" ,"health" : 1 ,"state" : 2 ,"stateStr" : "SECONDARY" ,"uptime" : 2823 ,"optime" : {"ts" : Timestamp (1683774703 , 1 ),"t" : NumberLong (3 )"optimeDate" : ISODate ("2023-05-11T03:11:43Z" ),"lastAppliedWallTime" : ISODate ("2023-05-11T03:11:43.552Z" ),"lastDurableWallTime" : ISODate ("2023-05-11T03:11:43.552Z" ),"syncSourceHost" : "" ,"syncSourceId" : -1 ,"infoMessage" : "" ,"configVersion" : 1 ,"configTerm" : 3 ,"self" : true ,"lastHeartbeatMessage" : "" "_id" : 2 ,"name" : "192.168.0.181:27022" ,"health" : 0 ,"state" : 8 ,"stateStr" : "(not reachable/healthy)" ,"uptime" : 0 ,"lastHeartbeat" : ISODate ("2023-05-11T03:13:32.048Z" ),"lastHeartbeatRecv" : ISODate ("2023-05-11T03:11:37.565Z" ),"pingMs" : NumberLong (0 ),"lastHeartbeatMessage" : "Error connecting to 192.168.0.181:27022 :: caused by :: Connection refused" ,"syncSourceHost" : "" ,"syncSourceId" : -1 ,"infoMessage" : "" ,"configVersion" : 1 ,"configTerm" : 3 "ok" : 1 ,"$clusterTime" : {"clusterTime" : Timestamp (1683774703 , 1 ),"signature" : {"hash" : BinData (0 ,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ),"keyId" : NumberLong (0 )"operationTime" : Timestamp (1683774703 , 1 )
由于副本集存活的节点数少于总节点数的一半,服务进入降级模式,主节点自动降级为副本节点,此时的服务只能够读取不能够写入。当重新加入的节点数过半后,重新选举主节点,副本集写入功能恢复
连接副本集写法
1 mongodb://<replica -set -hostname>/<database -name >?replicaSet=<replica -set -name >
mongod 命令连接副本集
1 mongo "mongodb://192.168.0.181:27021,192.168.0.181:27021,192.168.0.181:27022/test?replicaSet=rs"
分片 是一种将数据分配到多个机器上的方法。MongoDB通过分片技术来支持具有海量数据集和高吞吐量操作的部署方案。
数据库系统的数据集或应用的吞吐量比较大的情况下,会给单台服务器的处理能力带来极大的挑战。例如,高查询率会耗尽服务器的CPU资源。工作的数据集大于系统的内存压力、磁盘驱动器的I/O容量。
分片是水平扩展的一种方案,通过将系统数据集划分至多台机器,并根据需要添加服务器来提升容量。虽然单个机器的总体速度或容量可能不高,但每台机器只需处理整个数据集的某个子集,所以可能会提供比单个高速大容量服务器更高的效率,而且机器的数量只需要根据数据集大小来进行扩展,与单个机器的高端硬件相比,这个方案可以降低总体成本。不过,这种方式会提高基础设施部署维护的复杂性。
分片 :每个分片都包含分片数据的一个子集。从MongoDB 3.6开始,分片必须部署为副本集。路由器 : mongos 充当查询路由器,在客户端应用程序和分片集群之间提供接口。从MongoDB 4.4开始, mongos 可以支持 对冲读取 以最大程度地减少延迟。配置服务器 :配置服务器存储群集的元数据和配置设置。从MongoDB 3.4开始,配置服务器必须部署为副本集(CSRS)分片集群角色
角色 描述 configsvr 该角色表示当前节点是分片集群的配置服务器。配置服务器负责管理集群的元数据信息,如分片键、分片状态等等。 shardsvr 该角色表示当前节点是一个数据分片节点。数据分片节点存储了实际的数据,并负责对数据进行读写操作。 mongos 该角色表示当前节点是 mongos 路由器节点。mongos 负责将客户端请求路由到正确的分片节点上,并合并结果返回给客户端。
参考搭建
创建第一个分片副本集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 docker run --name mongo_rs1_1 --network bridge -d mongo --replSet rs1 --shardsvr --port 27017 docker run --name mongo_rs1_2 --network bridge -d mongo --replSet rs1 --shardsvr --port 27017 docker run --name mongo_rs1_3 --network bridge -d mongo --replSet rs1 --shardsvr --port 27017 docker inspect 容器ID | grep IPAddress 172 .17 .0 .2 172 .17 .0 .3 172 .17 .0 .4 docker exec -it mongo_rs1_1 bash mongo rs .initiate (_id :"rs1" ,members :[_id:0, host :" 172.17.0.2:27017" },_id:1, host :" 172.17.0.3:27017" },_id:2, host :" 172.17.0.4:27017" }
创建第二个分片副本集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 docker run --name mongo_rs2_1 --network bridge -d mongo --replSet rs2 --shardsvr --port 27017 docker run --name mongo_rs2_2 --network bridge -d mongo --replSet rs2 --shardsvr --port 27017 docker run --name mongo_rs2_3 --network bridge -d mongo --replSet rs2 --shardsvr --port 27017 docker inspect 容器ID | grep IPAddress 172 .17 .0 .5 172 .17 .0 .6 172 .17 .0 .7 docker exec -it mongo_rs2_1 bash mongo rs .initiate (_id :"rs2" ,members :[_id:0, host :" 172.17.0.5:27017" },_id:1, host :" 172.17.0.6:27017" },_id:2, host :" 172.17.0.7:27017" }
创建配置服务副本集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 docker run --name mongo_config_1 --network bridge -d mongo --replSet rsconfig --configsvr --port 27017 docker run --name mongo_config_2 --network bridge -d mongo --replSet rsconfig --configsvr --port 27017 docker run --name mongo_config_3 --network bridge -d mongo --replSet rsconfig --configsvr --port 27017 docker inspect 容器ID | grep IPAddress 172 .17 .0 .8 172 .17 .0 .9 172 .17 .0 .10 docker exec -it mongo_config_1 bash mongo rs .initiate (_id :"rsconfig" ,members :[_id:0, host :" 172.17.0.8:27017" },_id:1, host :" 172.17.0.9:27017" },_id:2, host :" 172.17.0.10:27017" }
创建路由服务
1 2 3 4 5 docker run -p 28000 :27018 --name mongo_router_1 --network bridge -d mongo --bind_ip 0.0.0.0 docker exec -it mongo_router_1 bashmongos --configdb rsconfig/172.17.0.8:27017 ,172.17.0.9:27017 ,172.17.0.10:27017 --port 27018 --bind_ip 0.0.0.0
打开新的shell
1 2 3 4 docker exec -it mongo_router_1 bash
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 use test.user .insert ( {userName:1 } )WriteCommandError ({"ok" : 0 ,"errmsg" : "Database test could not be created :: caused by :: No shards found" ,"code" : 70 ,"codeName" : "ShardNotFound" ,"$clusterTime" : {"clusterTime" : Timestamp (1683909745 , 1 ),"signature" : {"hash" : BinData (0 ,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ),"keyId" : NumberLong (0 )"operationTime" : Timestamp (1683909745 , 1 )
插入失败的原因:通过路由节点操作,现在只是连接了配置节点,还没有连接分片数据节点,因此无法写入业务数据。
将第一套分片副本集添加进来
使用语法
1 sh.addShard ("副本集名称/IP:Port" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 mongo --port 27018 addShard ("rs1/172.17.0.2:27017,172.17.0.3:27017,172.17.0.4:27017" "shardAdded" : "rs1" ,"ok" : 1 ,"$clusterTime" : {"clusterTime" : Timestamp (1684141648 , 4 ),"signature" : {"hash" : BinData (0 ,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ),"keyId" : NumberLong (0 )"operationTime" : Timestamp (1684141648 , 4 )
查看分片状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 mongos> sh.status ()Sharding Status --- version : {"_id" : 1 ,"minCompatibleVersion" : 5 ,"currentVersion" : 6 ,"clusterId" : ObjectId ("645e6ad0efcc6b2b53143174" )shards :"_id" : "rs1" , "host" : "rs1/172.17.0.2:27017,172.17.0.3:27017,172.17.0.4:27017" , "state" : 1 , "topologyTime" : Timestamp (1684141648 , 1 ) }mongoses :"5.0.5" : 1 autosplit :Currently enabled : yesbalancer :Currently enabled : yesCurrently running : noFailed balancer rounds in last 5 attempts : 0 Migration results for the last 24 hours : No recent migrationsdatabases :"_id" : "config" , "primary" : "config" , "partitioned" : true }system .sessions key : { "_id" : 1 }unique : false balancing : true chunks :1024 if you want to force print
添加第二套分片副本集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 sh.addShard ("rs2/172.17.0.5:27017,172.17.0.6:27017,172.17.0.7:27017" "shardAdded" : "rs2" ,"ok" : 1 ,"$clusterTime" : {"clusterTime" : Timestamp (1684142090 , 4 ),"signature" : {"hash" : BinData (0 ,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ),"keyId" : NumberLong (0 )"operationTime" : Timestamp (1684142090 , 4 )
查看分片状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 mongos> sh.status ()Sharding Status --- version : {"_id" : 1 ,"minCompatibleVersion" : 5 ,"currentVersion" : 6 ,"clusterId" : ObjectId ("645e6ad0efcc6b2b53143174" )shards :"_id" : "rs1" , "host" : "rs1/172.17.0.2:27017,172.17.0.3:27017,172.17.0.4:27017" , "state" : 1 , "topologyTime" : Timestamp (1684141648 , 1 ) }"_id" : "rs2" , "host" : "rs2/172.17.0.5:27017,172.17.0.6:27017,172.17.0.7:27017" , "state" : 1 , "topologyTime" : Timestamp (1684142090 , 2 ) }mongoses :"5.0.5" : 1 autosplit :Currently enabled : yesbalancer :Currently enabled : yesCurrently running : noFailed balancer rounds in last 5 attempts : 0 Migration results for the last 24 hours : 30 : Success databases :"_id" : "config" , "primary" : "config" , "partitioned" : true }system .sessions key : { "_id" : 1 }unique : false balancing : true chunks :994 30 if you want to force print
如果添加分片失败,需要先手动移除分片,检查添加分片的信息的正确性后,再次添加分片。移除分片参考:
1 db.runCommand ( { removeShard : "rs1" } )
如果只剩下最后一个shard,是无法删除的,移除时会自动转移分片数据,需要一个时间过程。完成后,再次执行删除分片命令才能真正删除。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mongos> sh.enableSharding ("test" "ok" : 1 ,"$clusterTime" : {"clusterTime" : Timestamp (1684143030 , 5 ),"signature" : {"hash" : BinData (0 ,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ),"keyId" : NumberLong (0 )"operationTime" : Timestamp (1684143030 , 4 )
将名为 “mydb” 的数据库中的 “mycollection” 集合按照 “_id” 字段进行分片
1 sh.shardCollection("mydb.mycollection", {_id: 1})
分片键可以是单个索引字段,也可以是复合索引涵盖的多个字段,复合索引确定集合文档在集群分片中的分布。
MongoDB将分片键值(或使用 Hash散列分片键值)的范围划分为分片键值的非重叠范围。每个范围都与一个块( chunk )相关联。
chunk
特定分片内连续的分片键值范围。区块范围包括下边界,不包括上限。MongoDB在块增长超过配置的块大小(默认情况下为128MB)时会拆分块
当一个分片包含相对于其他分片的集合的区块过多时,MongoDB会迁移块。参考 分片集群负载均衡
分片键的选择 :
分片键的基数
分片键的基数代表分片键最大能有多少个块(chunk)
分片键频率
考虑分片键值在文档出现的频率,尽量选择重复出现频率不会差异很大的字段
非单调变更
在范围分片时,单调递增的主键要注意minKey和maxKey的分片,如果单调递增,大部分数据可能会在maxKey的数据块上
哈希分片使用单字段哈希索引或复合哈希索引(4.4 版新功能)作为分片键,用于跨分片集群对数据进行分区。如无范围查询需求,使用 _id 进行Hash分片是一个不错的选择。
下面的例子是使用nickname作为片键,根据其值的哈希值进行数据分片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mongos> sh.shardCollection ("articledb.comment" ,{"nickname" :"hashed" }"collectionsharded" : "articledb.comment" ,"collectionUUID" : UUID ("ddea6ed8-ee61-4693-bd16-196acc3a45e8" ),"ok" : 1 ,"operationTime" : Timestamp (1564612840 , 28 ),"$clusterTime" : {"clusterTime" : Timestamp (1564612840 , 28 ),"signature" : {"hash" : BinData (0 ,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ),"keyId" : NumberLong (0 )
基于范围的分片会将数据划分为由片键值确定的连续范围。 在此模型中,具有 相邻 分片键值的文档可能位于相同的块或分片中。 这有 效提高范围查询效率,但是如果分片键没选择好,则容易导致数据倾斜。
每个chunk的数据都存储在同一个Shard上,每个Shard可以存储很多个chunk,chunk存储在哪个shard的信息会存储在Config server中,mongos也会根据各个shard上的chunk的数量来自动做负载均衡。
下例是使用年龄进行范围分片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mongos> sh.shardCollection ("articledb.author" ,{"age" :1 }"collectionsharded" : "articledb.author" ,"collectionUUID" : UUID ("9a47bdaa-213a-4039-9c18-e70bfc369df7" ),"ok" : 1 ,"operationTime" : Timestamp (1567512803 , 13 ),"$clusterTime" : {"clusterTime" : Timestamp (1567512803 , 13 ),"signature" : {"hash" : BinData (0 ,"eE9QT5yE5sL1Tyr7+3U8GRy5+5Q=" ),"keyId" : NumberLong ("6732061237309341726" )
一旦对一个集合分片,分片键和分片值就不可改变。
语法:
1 sh.shardCollection (namespace, key, unique, options)
Parameter Type Description namespacestring 要分片的集合的命名空间,格式为 "<database>.<collection>" keydocument 指定要用作分片键的一个或多个字段的文档;shardCollection 命令之前存在。如果集合为空,MongoDB uniqueboolean 可选,指定 true 以确保基础索引强制实施唯一约束。默认为 false options可选,包含可选字段的文档,包括 numInitialChunks 和 collation
对 test 数据库的 user 表进行hash分片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mongos> sh.shardCollection ("test.user" , {"_id" : "hashed" }"collectionsharded" : "test.user" ,"ok" : 1 ,"$clusterTime" : {"clusterTime" : Timestamp (1684150040 , 29 ),"signature" : {"hash" : BinData (0 ,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ),"keyId" : NumberLong (0 )"operationTime" : Timestamp (1684150040 , 28 )
插入数据测试
1 2 3 4 5 6 7 8 9 10 11 12 use test mongos > for (var i =1; i<=100 ; i++) {insertOne (_id : i+"" ,userName : "wgf_" +i"acknowledged" : true , "insertedId" : "100" }
登陆第一个副本集 mongo_rs1_1
1 2 3 4 5 6 docker exec -it mongo_rs1_1 bashrs1 :PRIMARY > db.user .find ().count ()58
登陆第二个副本集 mongo_rs2_1
1 2 3 4 5 6 docker exec -it mongo_rs2_1 bashuse test db .user.find().count ()
可以看到,100条数据近似均匀的分布到了2个shard上。是根据片键的哈希值分配的。
MongoDB 平衡器是一个后台进程,用于监控每个分片集合的每个分片上的数据量。当给定分片上分片集合的数据量达到特定的 迁移阈值 时,平衡器会尝试在分片之间自动迁移数据,并在遵守区域的情况下达到每个分片的均匀数据量。默认情况下,始终启用平衡器进程。
分片集群的平衡过程对用户和应用程序层是无感知的,但是在执行该过程时可能会对性能产生一些影响。
MongoDB可以执行并行数据迁移,但一个分片一次最多可以参与一个迁移。对于具有 n 个分片的分片集群,MongoDB 最多可以同时执行 n/2(向下舍入)迁移
迁移阈值
为了最大程度地减少均衡对集群的影响,均衡器仅在分片集合的数据分布达到特定阈值后才开始自我平衡。
如果分片之间的数据差异(对于该集合)小于集合配置的范围大小的 三倍,则认为集合是平衡的。对于默认范围大小 128MB ,对于给定集合,两个分片的数据大小差异必须至少为 384MB 才能进行迁移。
分片集群与SpringBoot时,连接的是Router节点
1 2 3 4 spring: data: mongodb: uri: mongodb://172.17.0.11:27018/test
事务支持和被限制的操作
在MongoDB中,对单个文档的操作是原子的。由于可以使用嵌入式文档和数组来组织单个文档结构中数据之间的关系,而不是跨多个文档和集合进行规范化(范式),因此这种单文档原子性消除了许多实际用例对多文档事务的需求。
对于需要对多个文档(在单个或多个集合中)进行读取和写入的原子性的情况,MongoDB支持多文档事务。使用分布式事务可以跨多个操作、集合、数据库、文档和分片使用。
分布式事务和多文档事务
从MongoDB 4.2开始,这两个术语是同义词。分布式事务是指分片集群和副本集上的多文档事务。多文档事务(无论是在分片集群还是副本集上)也称为从MongoDB 4.2开始的分布式事务。
分布式事务是非常影响数据库性能的,官方推荐尽量使用反范式的设计规避分布式事务问题,不建议在Mongo大量使用多文档事务。
对于需要读取和写入多个文档(在单个或多个集合中)的原子性的情况,MongoDB支持多文档事务:
在4.0版本中,MongoDB支持副本集上的多文档事务。 在 4.2 版本中,MongoDB 引入了分布式事务,它增加了对分片集群上的多文档事务的支持,并结合了对副本集上多文档事务的现有支持。 多文档事务是原子的(即提供 全有或全无 的语义):
当一个事务提交后,所有数据的修改都会被保存并且变得可见。也就是说,在一个事务中,它所做的所有更改要么全部提交,要么全部回滚,保证了数据的一致性。 在一个事务提交之前,该事务所做的数据更改在事务外部是不可见的。 然而,当一个事务向多个Shard写入时,并不是所有的外部读操作都需要等待事务提交结果后在所有分片上都可见才能进行。 例如,如果一个事务已经提交,并且在Shard A上的写入1可见,但在Shard B上的写入2还不能被看到,对于使用 "local" 当一个事务中止时,所有在该事务中作出的数据更改都将被回滚。 分布式事务可以跨多个操作、集合、数据库、文档以及从 MongoDB 4.2 开始的 分片 中使用。
关于事务:
事务是与某个会话相关联的;即你为一个会话启动一个事务。 在任何给定时间,一个会话最多可以有一个打开的事务。 使用驱动程序时,事务中的每个操作都必须与会话相关联。 如果一个会话结束了并且它有一个打开的事务,则事务会中止。 在使用驱动时,可以在事务开始时设置事务级别的 read preference :
如果事务级别的读偏好没有设置,事务级的读偏好默认为会话级的读偏好 如果未设置事务级别和会话级别读取偏好,则事务将使用客户端级别的读取偏好。默认情况下,客户端级别的读取偏好项为 primary 包含读取操作的多文档事务必须使用 primary 读取偏好 。给定事务中的所有操作都必须路由到同一成员。事务中的操作使用事务级读取关注点。也就是说,在 集合 和 数据库 级别设置的任何读取关注点都将在事务中被忽略。
可以在事务启动时设置事务级读取关注点
读取关注 说明 "local(默认)"读取关注点 "local" 返回节点中可用的最新数据,但可以回滚(读未提交)。"local" 读取关注点无法保证数据来自同一个跨分片的快照视图,如果需要快照隔离,请使用 "snapshot" 读取关注点"local" 。 集合的隐式创建可以使用可用于事务的任何读取关注点。 "majority"读取关注点 "majority" 返回已由大多数副本集成员确认的数据(即数据无法回滚,读已提交),如果事务以写关注点"majority"提交"local" 读取关注点无法保证数据来自分片上的同一快照视图(视图未完成同步),如果需要快照隔离,请使用 "snapshot" 读取关注点 "snapshot"如果事务以写入关注点"majority"提交,则读取关注点 "snapshot" 会从一个大多数已提交数据的快照中返回数据(可重复读)。"snapshot" 视图在分片之间同步。
隐式默认写关注
MongoDB事务中的写入操作必须使用默认的写入关注,并在提交时使用事务级别的写入关注来提交写入操作。
注意
不要为事务中的各个写入操作显式设置写入关注点。为事务中的各个写入操作设置写入关注点会导致异常。
可以在事务启动时设置事务级写入关注点:
写关注点 说明 w: 1使用 w: 1 写入关注点提交时,事务级 "majority" 读取关注点无法保证事务中的读取操作能读取大多数已提交的数据。w: 1 写入关注点提交时,事务级 "snapshot" 读取关注不保证事务中的读取操作使用多数提的交快照数据。 w: "majority(默认)"在提交已应用于多数( M)有投票权的成员后,写关注 w: "majority"w: "majority" 写入关注点提交时,事务级 "majority" 读关注会保证操作已经读取了大多数提交的数据。 对于分片群集上的事务,大多数提交的数据的视图不会在分片之间同步。w: "majority" 写入关注点提交时,事务级 "snapshot" 读取关注点可确保操作来自大多数提交数据的同步快照。
默认情况下,事务的运行时间必须小于 一分钟。您可以使用 transactionLifetimeLimitSecondsmongod 实例修改此限制。对于分片集群,必须修改所有分片副本集成员的参数。超过此限制的事务被视为已过期,并将通过定期清理过程中止。
MongoDB根据需要创建尽可能多的oplog条目来封装事务中的所有写入操作,而不是为事务中的所有写入操作创建一个条目。这将删除单个 oplog 条目对其所有写入操作施加的事务的 16MB 总大小限制。尽管删除了总大小限制,但每个oplog条目仍必须在16MB的BSON文档大小限制范围内。
默认情况下,事务最多等待 5 毫秒来获取事务中操作所需的锁。如果事务无法在 5 毫秒内获取其所需的锁,则事务将中止。
事务在中止或提交时释放所有锁。
在开始事务之前立即创建或删除集合时,如果需要在事务内访问该集合,则在进行创建或删除操作时使用写关注 "majority"
可以使用 maxTransactionLockRequestTimeoutMillismaxTransactionLockRequestTimeoutMillis
事务内的读取操作可能会返回历史版本数据。也就是说,事务内的读操作不能保证看到其他已提交的事务或非事务性写入的内容。例如,假设有以下操作顺序:
事务正在进行中 事务外部的写入删除文档 事务内部的读取操作能够读取现在删除的文档,因为该操作使用的是写入之前的快照。 为避免事务内部单个文档的读取过时,可以使用 db.collection.findOneAndUpdate() 方法 。例如:
1 2 3 4 5 6 7 8 9 session.startTransaction ( { readConcern : { level : "snapshot" }, writeConcern : { w : "majority" } } );getDatabase ("hr" ).employees ;findOneAndUpdate (_id : 1 , employee : 1 , status : "Active" },$set : { employee : 1 } },returnNewDocument : true }
如果员工文档在事务之外发生更改,则事务将中止。 如果员工文档未更改,则事务将返回该文档并锁定该文档。 区块迁移 在某些阶段获取独占集合锁。
如果正在进行的事务持有集合上的锁,并且涉及该集合的块迁移刚开始,则这些迁移阶段必须等待事务释放集合上的锁,从而会影响块迁移的性能。
如果块迁移与事务交错进行(例如,如果事务在块迁移正在进行时开始,并且迁移在事务锁定集合之前完成),则事务在提交期间出错并中止。
在事务提交期间,外部的读操作可能会尝试读取将被事务修改的相同文档。如果事务写入多个分片,则在跨分片提交尝试期间。
使用读取关注点 "snapshot" 或 "linearizable" 的外部读取,或者是因果一致性会话的一部分(即包括 afterClusterTime)等待事务的所有写入都可见。 使用其他读取关注点的外部读取不会等待事务的所有写入都可见,而是读取可用文档的事务的历史版本。 Spring Data MongoDB 事务整合
SpringBoot整合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-mongodb</artifactId > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <optional > true</optional > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > </dependencies >
Mongo配置类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @Configuration @RequiredArgsConstructor public class MongoConfig {private final MongoDatabaseFactory mongoDbFactory;private final MongoMappingContext mongoMappingContext;@Bean public MappingMongoConverter mappingMongoConverter () {DbRefResolver dbRefResolver = new DefaultDbRefResolver (mongoDbFactory);MappingMongoConverter converter = new MappingMongoConverter (dbRefResolver, mongoMappingContext);new DefaultMongoTypeMapper (null ));return converter;@Bean public MongoTransactionManager mongoTransactionManager (MongoDatabaseFactory mongoDatabaseFactory) {TransactionOptions transactionOptions = TransactionOptions.builder().readConcern(ReadConcern.LOCAL).writeConcern(new WriteConcern (4 )).build();return new MongoTransactionManager (mongoDatabaseFactory, transactionOptions);
单元测试
使用上一章节做好分片的 user 集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @SpringBootTest class TransactionTest {Autowired UserService userService;Test void insertTest (User user1 = new User ();setId (UUID .randomUUID ().toString ())setUserName (UUID .randomUUID ().toString ());User user2 = new User ();setId (UUID .randomUUID ().toString ())setUserName (UUID .randomUUID ().toString ());User user3 = new User ();setId (UUID .randomUUID ().toString ())setUserName (UUID .randomUUID ().toString ());this .userService .insert (user1, user2, user3);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Service RequiredArgsConstructor class UserService {MongoTemplate mongoTemplate;Transactional (value = "mongoTransactionManager" )void insert (User user1, User user2, User user3 ) {insert (user1);insert (user2);insert (user3);
报错是因为写关注没有足够的数据节点承载,原因是副本集只有三个数据节点,事务配置正常
分布式事务回滚测试
1 2 3 4 5 6 @Bean public MongoTransactionManager mongoTransactionManager (MongoDatabaseFactory mongoDatabaseFactory) {TransactionOptions transactionOptions = TransactionOptions.builder().readConcern(ReadConcern.LOCAL).writeConcern(WriteConcern.MAJORITY).build();return new MongoTransactionManager (mongoDatabaseFactory, transactionOptions);
修改事务级别的写关注为 MAJORITY
单元测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Test public void insertErrorTest () {User user1 = new User ();User user2 = new User ();User user3 = new User ();this .userService.insertError(user1, user2, user3);
UserService 添加事务回滚方法
1 2 3 4 5 6 7 8 @Transactional(value = "mongoTransactionManager", rollbackFor = Exception.class) public void insertError (User user1, User user2, User user3) {throw new RuntimeException ();
异常,事务终止提交
生产可用配置
1 2 3 4 5 6 @Bean public MongoTransactionManager mongoTransactionManager (MongoDatabaseFactory mongoDatabaseFactory) {TransactionOptions transactionOptions = TransactionOptions.builder().readConcern(ReadConcern.SNAPSHOT).writeConcern(WriteConcern.MAJORITY).build();return new MongoTransactionManager (mongoDatabaseFactory, transactionOptions);
1 2 3 4 5 6 @Transactional(value = "mongoTransactionManager") public void insert (User user1, User user2, User user3) {
单元测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Test public void insertErrorTest () {User user1 = new User ();User user2 = new User ();User user3 = new User ();this .userService.insertError(user1, user2, user3);