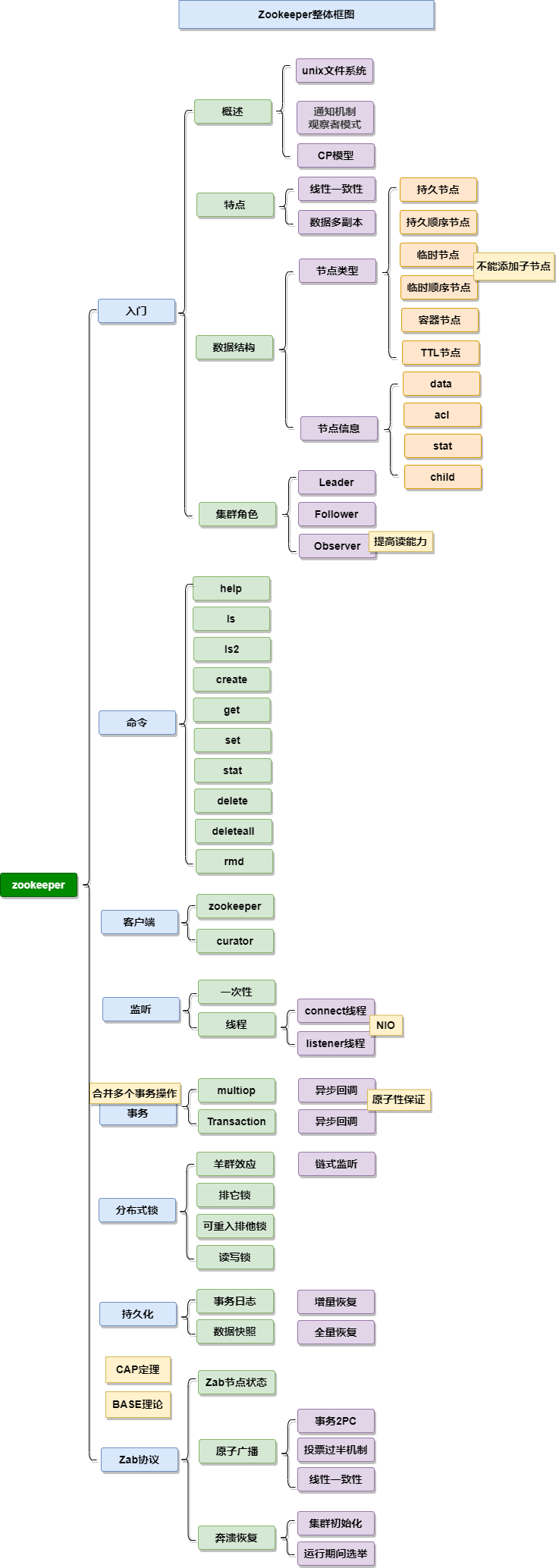
思维导图
在进行技术选型时,当考虑使用ZooKeeper作为分布式协调服务的解决方案时,首先需要明确ZooKeeper是否能够满足特定的应用场景需求。ZooKeeper作为一种分布式系统中的协调工具,虽然功能强大且通用,但它并不一定适合所有场景。在分布式协调服务的细分领域中,存在多种替代方案。这些方案针对不同的需求和约束条件,可能提供更优的性能、更高的可扩展性或更简单的使用方式。因此,在最终决定采用ZooKeeper之前,应该对其功能特性进行全面评估,并与其他可用的替代方案进行比较,以确保选择最适合当前业务需求的解决方案。
服务发现
早期,Dubbo选择ZooKeeper作为其服务发现组件,这在一定程度上受到当时的技术环境影响。当时,微服务架构并未像现在这样广泛流行,服务发现的解决方案相对有限。重要的是要注意,ZooKeeper主要遵循CP(一致性和分区容错性)模型。然而,对于服务发现组件而言,是否真的需要强调一致性?个人认为,对于服务发现组件来说,最重要的应该是高可用性。在微服务架构中,服务发现组件的任何故障都不应导致整个系统的服务瘫痪,这种情况是不可接受的。理想情况下,服务发现组件应始终保持可用,即使数据不一致导致服务不可用也应通过负载均衡策略或服务降级等方案来确保系统的正常运行。
随着技术的发展,现在已经出现了一些更适合微服务架构的服务发现组件,它们主要遵循AP(可用性和分区容错性)模型,以确保在网络分区和其他故障情况下的高可用性。例如,Eureka(Spring Cloud 1.x)和Nacos,它们提供了更灵活和健壮的服务发现机制,更适合于微服务架构的服务发现需求。
配置中心
在对配置中心进行技术选型时,ZooKeeper的CP(一致性和分区容错性)模型确实非常适合用元数据配置服务。ZooKeeper的节点监听功能可以方便地实现配置的动态更新,这对于基本的元数据配置服务来说是一个不错的选择,早期的Kafka等相关服务也采用其作为解决方案。它的一致性保证了配置信息的准确性和可靠性。
然而,如果将ZooKeeper作为一个功能更全面的配置中心,也存在一些局限性。首先,它缺乏一个灵活且易于使用的配置UI界面,这对于管理和维护大量配置项可能会带来一定的挑战。其次,ZooKeeper本身并不提供数据解析逻辑,这意味着用户需要自行实现配置数据的解析和处理逻辑,这增加了使用的复杂性。
鉴于这些局限性,不如使用针对性更强的服务,如Apollo或Nacos。这些工具不仅提供了更友好的配置界面和数据管理功能,还内置了数据解析和处理逻辑,减少了开发者的工作量。此外,它们还可能提供更多高级功能,如配置版本管理、环境隔离、权限控制等,这些都是在复杂的应用环境中不可或缺的特性。
分布式锁
ZooKeeper构建的分布式锁不是一个适用于所有场景的通用解决方案。这主要是由于ZooKeeper底层的ZAB(ZooKeeper Atomic Broadcast)协议的工作机制。在ZAB协议中,事务的提交需要集群中大多数节点的同意,这意味着随着集群节点数量的增加,达成共识所需的时间会增加,从而导致事务操作的延迟性增高。因此,如果考虑使用ZooKeeper实现分布式锁,特别是在分布式事务场景中,就需要考量业务是否能够容忍这种写操作的性能瓶颈。
如果业务场景中对分布式锁的要求是高可用性,并且需要在服务异常时锁具有自动恢复的能力,那么ZooKeeper是一个非常合适的选择。可以使用临时节点,服务异常时自动释放锁。
然而,如果分布式锁应用于高并发的场景,ZooKeeper就不是一个理想的选择。在高并发场景下,ZooKeeper的性能瓶颈会严重影响业务,导致锁操作的响应时间变长,从而影响整体系统的性能。在这种情况下,可以考虑其他专门为高并发设计的分布式锁解决方案,例如基于Redis的RedLock算法等,这些方案能够提供更快的响应时间和更好的扩展性,更适合于高并发环境。
Leader选举
分布式服务中的Leader选举可以通过ZooKeeper来实现,优点是减少了开发工作量,因为ZooKeeper提供了一套现成的、可靠的机制来处理选举的复杂性。在整个方案中,各个服务节点尝试在ZooKeeper中创建同一个zNode(节点)。由于ZooKeeper保证同一个节点名下只能成功创建一个临时zNode,因此第一个成功创建该zNode的服务节点将成为Leader。
这个临时zNode的特性是关键:它确保了当Leader节点宕机或失去与ZooKeeper集群的连接时,该zNode会被自动删除。其他的服务节点(Follower)在ZooKeeper上对这个zNode进行监听。当它们检测到这个zNode被删除的事件时,意味着原Leader已不再可用,随即开始新一轮的Leader选举。
这种选举方案适合在Leader选举时,没有额外业务逻辑处理的选举场景。
文章涉及源码
Apache ZooKeeper是一个开源的分布式协调服务 ,主要用于构建分布式应用程序。它为分布式应用程序提供一套简单、可靠的协调和管理功能,帮助应用程序处理分布式环境中的各种服务,如 配置管理、同步 和 服务发现 等。
工作机制
ZooKeeper, 从设计模式的角度来看,可以被认为是一个实现了 观察者模式 的分布式协调服务框架。它主要负责存储和管理分布式系统中重要的配置信息和命名数据。当这些数据状态发生变化时,ZooKeeper会通知已经向其注册的观察者,从而使这些观察者能够做出相应的反应。
Zookeeper = 文件系统 + 通知机制
CAP定理
可靠性:即使部分节点发生故障,整个系统仍将继续运行。
顺序一致性:Zookeeper 数据操作按照请求的先后顺序排队进行。集群可能存在短暂的数据不一致窗口,但ZooKeeper保证最终一致性。
原子性:数据更新操作是原子的,要么完全成功,要么完全失败,不会有中间或部分完成的状态。
可扩展性:集群架构支持节点水平扩展。
监视和通知:可以在 znode 上设置监视。此机制允许客户端接收有关特定 znode 更改的通知,而无需轮询更新。
广义上满足CP定理
ZK是一个满足CP理论的分布式应用程序协调服务,A(可用性)不满足是因为ZK集群Leader宕机恢复选举过程中,整个集群处于不可用状态,Zab协议
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个ZNode都有一个与之关联的路径,这个路径为其在ZooKeeper中提供了唯一的标识。
持久性
持久节点(Persistent):无论客户端与服务端的会话是否失效,该节点都会持续存在,除非被显式删除。临时 (Ephemeral):当客户端与服务端的会话失效时,该节点会自动被删除。顺序性
普通节点:节点的名称与创建时客户端指定的名称完全相同。顺序节点:在节点的名称后会自动附加一个唯一的递增序列号。节点类型 说明 持久节点 在Zookeeper中,持久节点会持续存在,直到被显式删除。 持久顺序节点 与持久节点特性相同,但每次创建时,节点名称后会自动添加由其父节点维护的递增整型数字。 临时节点 临时节点与客户端会话相关联。客户端会话失效时,其创建的所有临时节点都会被删除。 临时顺序节点 与临时节点特性相同,但在节点名称后会自动添加由其父节点维护的递增整型数字。
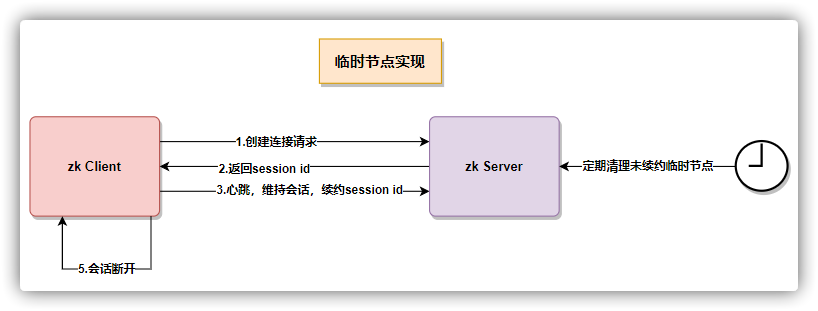
临时节点
注意:临时节点不能添加子节点
节点元数据 ephemeralOwner 就是临时节点客户端的 session id
使用场景
Container节点
Container 节点是ZooKeeper 3.5.0及其以后版本中引入的一种特殊类型的znode。
自动清理当 Container 节点下的所有子节点都被删除后,Container 节点会在将来某个时间点被ZooKeeper自动删除。 这个特性使得 Container 节点很适合用于那些只需要短暂地作为容器存在的场景。 无法直接删除如果你尝试直接删除一个还包含子节点的 Container 节点,这个操作会失败。只有当其下没有子节点时,Container 节点才会被自动删除。 TTL节点
3.5.3版本新增,需要配置系统变量zookeeper.extendedTypesEnabled=true,3.6.3版本后默认启用
十秒后自动删除
自动删除递归删除不可更改的TTLTTL的时间单位zookeeper 中的所有存储的数据是由 znode 组成的,节点也称为 znode,并以 key/value 形式存储数据
说明 描述 data 存储在znode中的数据。 acl 定义了用户的权限以及他们能够对znode执行的操作。c: 允许创建子节点w: 允许更新节点数据r: 允许读取节点数据和获取子节点列表d: 允许删除子节点a: 允许设置节点的acl权限 stat 包含znode的元数据,如创建和修改的时间戳、版本信息、大小等。 child 列出当前znode的直接子节点。
节点元数据
字段 说明 czxid 创建节点时的事务ID。事务ID(zxid)表示ZooKeeper状态的每次修改。每个zxid都是唯一的,且按修改的顺序连续生成。如果zxid1小于zxid2,则zxid1在zxid2之前发生。 mzxid 节点最后修改时的事务ID。 pZxid 当前节点的子节点列表最后一次修改的事务ID。只有当子节点列表变动(例如,添加或删除子节点)时,此ID才会变更。修改子节点的数据内容不会影响此ID。 ctime 创建节点时的时间戳(毫秒为单位,从1970年1月1日开始)。 mtime 节点最后修改的时间戳(毫秒为单位,从1970年1月1日开始)。 cversion 子节点版本号。每当子节点列表变动时,此版本号递增。 dataversion 数据版本号。每当节点数据变动时,此版本号递增。 aclVersion ACL(访问控制列表)版本号。每当节点的ACL变动时,此版本号递增。 ephemeralOwner 如果是临时节点,此字段表示znode拥有者的session id。如果是持久节点,则此字段为0。 dataLength 节点数据的长度(以字节为单位)。 numChildren 当前节点的直接子节点数量。
事务请求
在ZooKeeper的集群(称为ensemble)中,为了保持数据一致性,修改操作都被视为事务请求。 客户端发起的事务请求首先到达Leader。 Leader创建提议并发起投票,请求Follower节点的意见。 Follower根据其状态回应投票结果。 若过半数Follower同意,Leader确认并执行事务。 由于需过半同意,集群大小确实对写性能有所影响:节点越多,达到多数的延迟越高。 事务请求转发
Follower收到客户端写请求后,会转发给Leader,因为仅Leader可提议更改。 Leader提议更改并等待Follower的回应。 一旦得到过半Follower的确认,Leader提交更改,并同步确保所有Follower与其状态一致。 写请求需要所有活跃的节点参与进来保证数据的一致性,因此它们被视为事务请求。
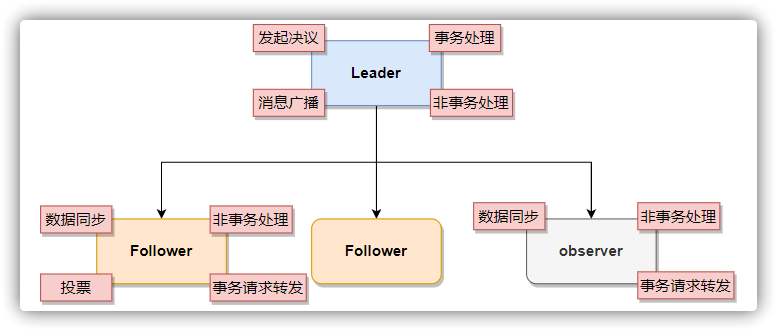
角色 说明 leader 负责发起投票和做出决策,更新系统状态,以及处理事务请求。 follower (跟随者) 参与投票,接收并处理客户端的非事务请求并返回结果,同时将事务请求转发给leader进行处理。 observer (观察者) 虽然不参与投票,但同步leader的状态来扩展系统并提高读取性能。它还可以接收客户端请求,处理非事务请求并返回结果,同时将事务请求转发给leader。
observer 观察者
在 Leader 选举过程中,我们通常不讨论 Observer,这是因为 Observer 不具备投票权。尽管如此,Observer 与 Follower 在功能上极为相似,主要区别是其不参与投票和过半机制。Observer 可以接受客户端连接,并能够从 Leader 同步数据。 Observer 的设计目的之一是为了支持扩容。它可以帮助实现数据的动态迁移和扩容。最重要的是,Observer在不影响集群写性能的前提下增强了读取性能zookeeper 下载
创建节点文件夹(伪集群)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mkdir /data/zookeeper/zk1
将下载好的zk分别解压到创建的三个zk目录中
在zookeeper conf目录下分别添加zoo.cfg
zookeeper 完整配置详解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 心跳时间2秒 # Follower跟随者服务器与Leader领导者服务器之间初始化连接时能容忍的最多心跳数10*tickTime # 集群中Leader与Follower之间的最大响应时间单位5*tickTime # 存储快照文件 snapshot 的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能 # 事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能 # zookeeper端口 # 单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制 # server.1代表一台服务器的编号,第一个端口为集群通讯端口,第二个端口代表Leader选举的端口 # 指定观察者 # server.3=127.0.0.1:2883:3883:observer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 心跳时间2秒 # Follower跟随者服务器与Leader领导者服务器之间初始化连接时能容忍的最多心跳数10*tickTime # 集群中Leader与Follower之间的最大响应时间单位5*tickTime # 存储快照文件 snapshot 的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能 # 事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能 # zookeeper端口 # 单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制 # server.1代表一台服务器的编号,第一个端口为集群通讯端口,第二个端口代表Leader选举的端口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 心跳时间2秒 # Follower跟随者服务器与Leader领导者服务器之间初始化连接时能容忍的最多心跳数10*tickTime # 集群中Leader与Follower之间的最大响应时间单位5*tickTime # 存储快照文件 snapshot 的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能 # 事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能 # zookeeper端口 # 单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制 # server.1代表一台服务器的编号,第一个端口为集群通讯端口,第二个端口代表Leader选举的端口
分别启动zk
1 2 3 4 5 cd bin目录# 查看状态
命令基本语法 功能描述 help显示ZooKeeper支持的所有命令及其用法。 ls <path> [watch]列出指定path下的子节点。可选参数watch设置监听指定节点的子节点变化。-R:递归列出所有子节点。 ls2 <path> [watch]类似于ls,但同时显示节点的状态信息,如数据版本和ACLs。 create <path> [data] [acl]在指定的路径创建一个新节点。-s:创建一个带序列号的节点。-e:创建一个临时节点,会话结束或超时后消失。-c:创建一个容器节点,会自动删除没有子节点的容器。-t <time>:创建一个具有TTL(存活时间)的节点,未修改且无子节点时将被自动删除。 get <path> [watch]获取指定路径节点的数据内容。watch参数用于设置对节点数据变化的监听。 set <path> <data> [version]更新指定路径节点的数据。-w:更新时设置对节点数据变化的监听。-s:更新数据同时设置附加信息。-v <version>:指定节点的版本进行乐观锁控制。 stat <path>显示指定节点的元数据信息,如版本号和子节点数。 delete <path> [version]删除指定路径的节点。-v <version>:用于乐观锁控制,只有版本匹配时才能删除。 deleteall <path>递归删除指定路径及其所有子节点。 rmr <path>递归删除节点,与deleteall功能相同,但rmr已被弃用。
查看指定路径下的子节点
查看子节点和元数据
查看节点元数据
创建永久节点
创建永久顺序节点
1 create -s /yongjiu/shunxu 永久顺序节点
创建成功后名称会发生变化 shunxu0000000000 后面会加上序列号
创建临时节点
创建临时顺序节点
1 create -e -s /linshi 临时顺序节点
临时顺序节点的父节点不能是临时节点
设置节点的值
获取节点的值
删除节点
递归删除节点,包括其子节点
ACL权限操作
如果其他会话不注册当前会话的账号密码,则没有权限操作/test-node节点
客户端操作
ZooKeeper原生Java API的不足之处:
在连接zk超时的时候,不支持自动重连,需要手动操作 Watch注册一次就会失效,需要反复注册 不支持递归创建节点 Apache curator
解决Watch注册一次就会失效的问题 支持直接创建多级结点 提供的 API 更加简单易用 提供更多解决方案并且实现简单,例如:分布式锁 提供常用的ZooKeeper工具类 编程风格更舒服 zkClient 节点操作
curator 节点操作
Curator使用手册
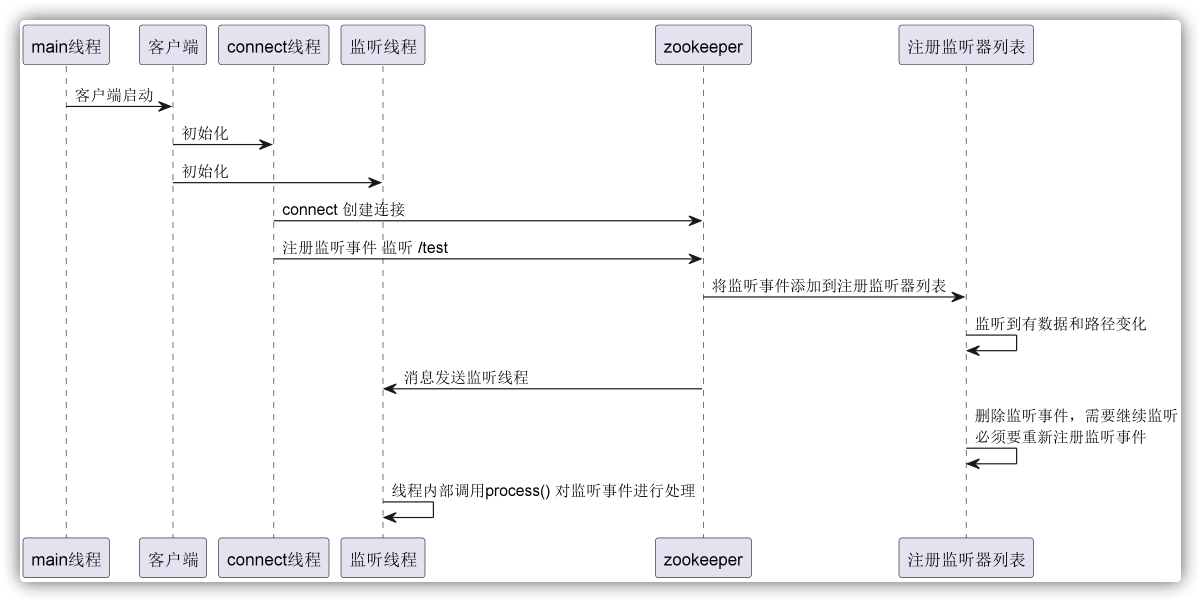
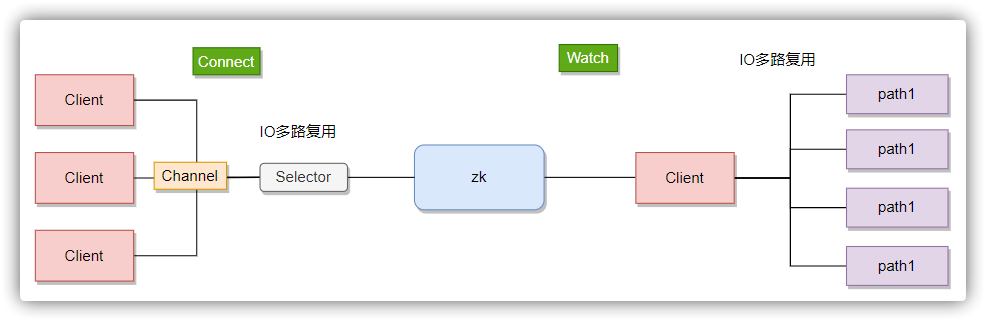
在ZooKeeper中,节点监听(watch)是一种机制,允许客户端在指定的znode上注册一个watch,以便在该节点上发生特定类型的事件时得到通知。ZooKeeper的watch机制是轻量级的,它被设计为一次性触发器,即一旦被触发就会被移除 ,如果需要持续监听,则需要在每次接收到通知后重新设置watch。
节点监听流程
客户端初始化:线程启动:发送线程(Send Thread): 负责与ZooKeeper集群建立和维持网络连接,发送请求和接收响应。事件线程(Event Thread): 负责处理来自服务器的事件通知,并触发注册的Watcher回调。监听器注册:服务器处理:事件触发:事件通知:监听器一次性特性:注意事项:
为了保证线程安全,事件处理逻辑应避免直接在process()方法中执行长时间运行的操作或网络调用。如果必须进行这些操作,应在process()方法中将任务委托给其他线程执行。 客户端的主线程通常用于发起ZooKeeper操作和Watcher注册,并不直接参与网络通信或事件处理。这些职责由发送线程和事件线程分别承担。 监听事件
事件 说明 触发条件 None 连接状态事件 客户端的连接状态改变时,包括以下KeeperState事件:Expired:会话过期Disconnected:断开连接SyncConnected:同步连接已建立AuthFailed:认证失败 NodeCreated 节点创建事件 对特定节点设置exists监听后,该节点被成功创建时触发 NodeDeleted 节点删除事件 被监听的节点被删除时触发 NodeDataChanged 节点数据变化事件 被监听的节点的数据发生变化时触发 NodeChildrenChanged 子节点列表变化事件 被监听节点的直接子节点列表发生变化时触发,如子节点的添加或删除
客户端实现 Watch
Curator事件监听
Curator 实现Watch
zkClient 实现Watch
Curator提供了五种监听方式
Curator框架为ZooKeeper客户端操作提供了强化的监听器功能,包括以下几种类型:
Watcher监听CuratorListener监听inBackground方法提交的异步任务。这类监听关注的是任务执行的结果及错误通知,而非节点内容的改变。NodeCache监听PathChildrenCache监听TreeCache监听NodeCache和PathChildrenCache的特性,监听指定的起始节点及其所有子节点的变化。这意味着无论是节点本身还是其任意层次的子节点发生变化,TreeCache都能捕捉到事件,并自动重新注册监听,方便用户追踪整个树形结构的状态。1 2 3 4 客户端1
只对一级子节点有效
当监听节点的子节点发生变化就会触发(新增和删除)
1 2 客户端2
1 2 3 4 客户端1
1 2 客户端2
1 2 3 4 客户端1
存在则返回节点信息,不存在则返回null
zkClient 使用事务
curator 使用事务
在分布式系统中,我们经常需要确保一组操作要么全部成功执行,要么全部不执行,以此来保持系统的一致性。这是事务的基本特性,也称为原子性。在多线程或者分布式环境中,操作原子性尤为重要,因为它可以避免由于操作部分完成而引起的数据不一致问题。
从版本3.4.0起,ZooKeeper引入了 multi 操作,它允许客户端原子性地执行一批操作。这意味着这批操作要么都成功,要么都不会对ZooKeeper的状态产生任何影响。在Java客户端中,这一特性被封装在 Transaction 类中,提供了一种便捷的方法来组合多个操作并一次性提交。如果事务中的任何操作失败,整个事务会回滚,保证数据的一致性。
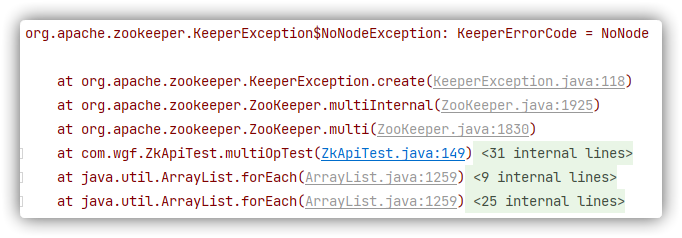
删除 /a /b /c 节点
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test @SneakyThrows public void multiOpTest () {"/a" , -1 ),"/b" , -1 ),"/c" , -1 )for (OpResult result : results) {
假如只存在 /a /b,执行时会抛出 NoNodeException 因为不存在 /c,执行完之后发生 /a /b 还在
异步处理
跟 ZooKeeper 的其他节点操作一样,multiop也提供了异步的版本,通过返回码判断执行结果,不用去捕获处理异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @Test public void asyncMultiOpTest () throws InterruptedException {MultiCallback callback = (rc, path, ctx, opResults) -> {switch (KeeperException.Code.get(rc)) {case OK:"节点%s删除成功" , path));case CONNECTIONLOSS:"连接丢失" );break ;case NONODE:"NoNode Error!" );break ;default :"Error when trying to delete node: " + KeeperException.create(KeeperException.Code.get(rc), path));"/a" , -1 ),"/b" , -1 ),"/c" , -1 ),null 2 );
ZooKeeper 的 Transaction 功能建立在 multi 操作之上,提供了一种灵活的方式来组织一组操作。在这个机制中,你可以在事务提交前随时添加新的操作到一个原子操作序列中。此外,你可以在不同的方法中构建事务,不受限于单一代码块。当准备好提交时,Transaction 支持同步(commit)和异步(commitAsync)两种提交方式,确保事务的一致性执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Test @SneakyThrows public void transactionTest () {Transaction t = zooKeeper.transaction();"/t1" , "t1" .getBytes(StandardCharsets.UTF_8), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);"/t2" , "t2" .getBytes(StandardCharsets.UTF_8), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);"/t3" , "t3" .getBytes(StandardCharsets.UTF_8), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);for (OpResult result : results) {if (result instanceof OpResult.CreateResult) {"create success" );
异步处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Test @SneakyThrows public void asyncTransactionTest () {MultiCallback callback = (rc, path, ctx, opResults) -> {switch (KeeperException.Code.get(rc)) {case OK:"事务执行成功" );case CONNECTIONLOSS:"连接丢失" );break ;case NONODE:"NoNode Error!" );break ;default :"Error when trying to delete node: " + KeeperException.create(KeeperException.Code.get(rc), path));Transaction t = zooKeeper.transaction();"/t1" , -1 )"/t2" , -1 )"/t3" , -1 );null );1 );
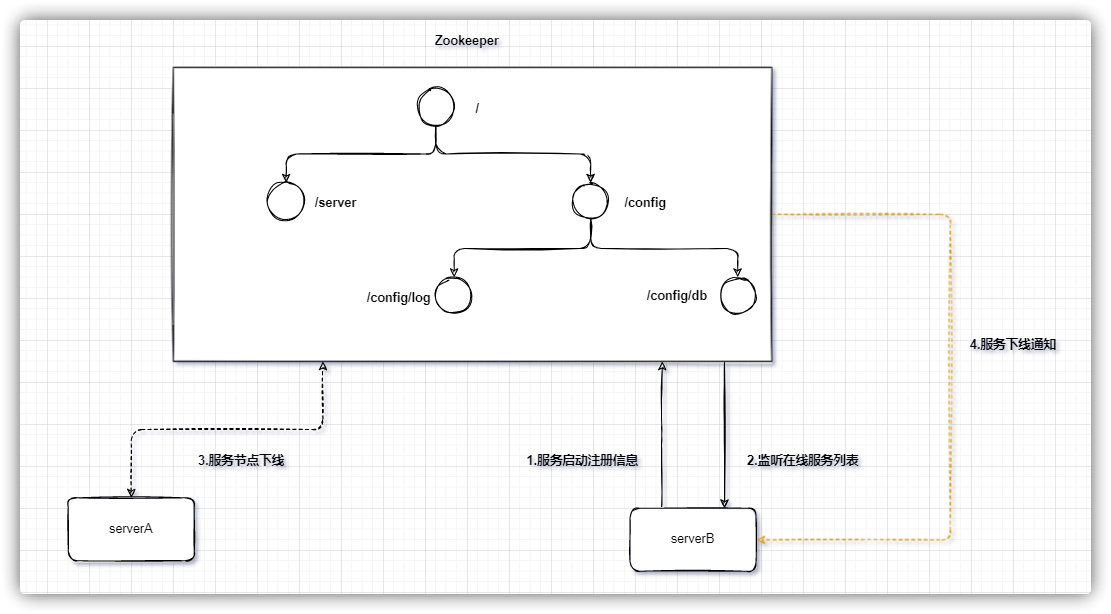
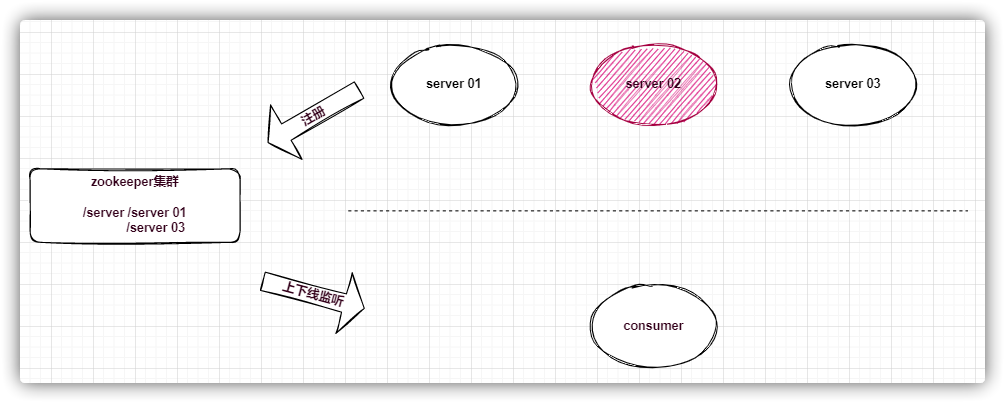
在分布式系统中,一个服务的节点可以有多台(比如Dubbo),可以动态上下线,任意一台客户端都能实时感知到服务节点的上下线
服务端实现
首先建立一个服务的永久节点 当节点上线则在服务节点下创建一个临时节点,节点的值存储服务器连接信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 @Slf4j public class ProviderTest {private static final String ROOT = "/server" ;private String connectString = "127.0.0.1:2181" ;private int sessionTimeout = 2000 ;private ZooKeeper zkClient;@SneakyThrows @BeforeEach public void init () throws IOException {new ZooKeeper (connectString, 2000 , new Watcher () {@Override public void process (WatchedEvent event) {Stat exists = zkClient.exists(ROOT, false );if (exists == null ) {try {null , ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);catch (Exception e) {this .register("provider" , "127.0.0.1" , 8080 );@SneakyThrows private void register (String serverName, String ip, int port) {String path = String.format("%s/%s" , ROOT, serverName);String value = String.format("%s:%s" , ip, port);String create = zkClient.create(path, value.getBytes(StandardCharsets.UTF_8),"server {} is online" , serverName);@Test public void test () throws InterruptedException {"启动服务..." );1000 );
服务端实现
获取服务节点下的所有临时节点,并保存到本地服务列表 监听服务节点子节点变化,当服务节点的子节点发生变化时刷新本地服务列表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 @Slf4j public class ConsumerTest {private static final String ROOT = "/server" ;private String connectString = "127.0.0.1:2181" ;private int sessionTimeout = 2000 ;private ZooKeeper zkClient;private List<String> serverList = null ;private AtomicLong sequence = new AtomicLong (0 );@BeforeEach public void init () throws IOException {new ZooKeeper (connectString, 2000 , new Watcher () {@Override public void process (WatchedEvent event) {"path: {}" , event.getPath());@SneakyThrows private void getServerList () {true );new CopyOnWriteArrayList <>(children);"serverList: {}" , serverList);private String getServer () {if (CollectionUtils.isEmpty(serverList)) {throw new RuntimeException ("没有可用的服务" );int len = serverList.size();return serverList.get((int ) (sequence.getAndIncrement() % len));@Test public void test () throws InterruptedException {for (;;) {try {10 );"执行业务" );String server = getServer();"跨服务调用:调用服务:{}" , server);"服务调用结束..." );catch (Exception e) {
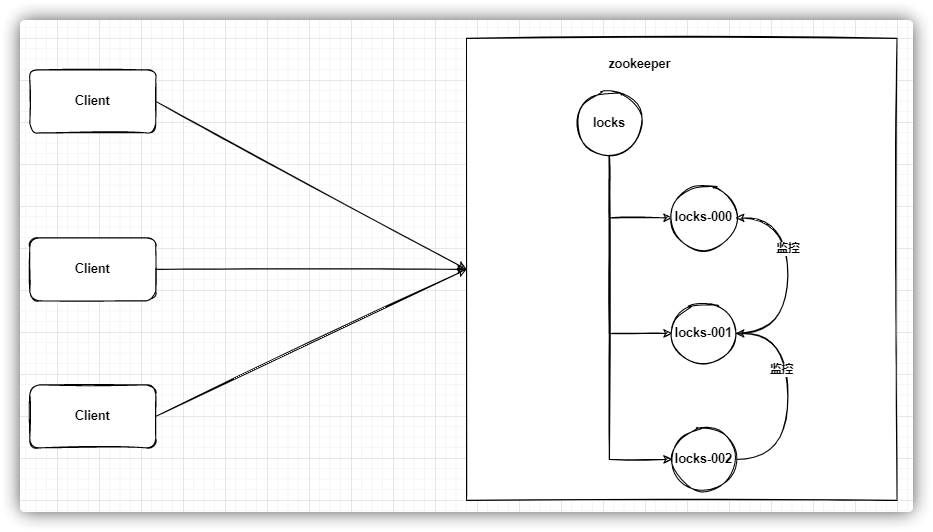
ZooKeeper 利用其临时顺序节点实现分布式锁,这种机制的优势在于其高可靠性:一旦持锁的服务意外宕机,ZooKeeper会自动删除那些与会话关联的临时节点,因此锁会被迅速释放。相比之下,基于Redis的分布式锁通常依赖于键的过期时间(TTL)来释放锁,如果服务在锁未释放时宕机,则需要等待TTL到期,这可能导致锁被持有超过必要的时间。
然而,ZooKeeper并不总是适用于高并发场景下的分布式锁。因为ZooKeeper的写操作需要经过集群中唯一的领导者(Leader)进行处理和复制到其他跟随者(Follower)节点,这限制了其在高写负载条件下的性能。如果写请求过于频繁,可能会成为系统性能的瓶颈。
分布式锁实现
创建根节点/locks,作为所有分布式锁的父节点。请求锁/locks节点下创建一个临时顺序节点,例如/locks/lock_。节点排序/locks下所有子节点,并按照节点编号排序。检查排名如果是最小的节点,那么客户端获得锁。 如果不是,客户端找到比自己小的最近的一个节点,并在这个节点上设置监听。 锁等待锁的释放监听触发1 2 3 4 5 6 7 8 public interface DistributedLock {void lock () ;void unLock () ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 @Slf4j public class ZookeeperLock implements DistributedLock {private static final String ROOT = "/lock" ;private ThreadLocal<String> nodeInfo = new ThreadLocal <>();private String connectString = "127.0.0.1:2181" ;private int sessionTimeout = 2000 ;private String lockPath;private ZooKeeper zkClient;private ZookeeperLock (String lockName) {this .lockPath = String.format("%s/%s" , ROOT, lockName);try {CountDownLatch connectedSignal = new CountDownLatch (1 );new ZooKeeper (connectString, sessionTimeout, (Watcher) watchedEvent -> {if (watchedEvent.getState() == Watcher.Event.KeeperState.SyncConnected) {Stat stat = zkClient.exists(ROOT, false );if (stat == null ) {null , ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);catch (Exception e) {@Override public void lock () {try {String nodeName = zkClient.create(lockPath, null , ZooDefs.Ids.OPEN_ACL_UNSAFE,false );new TreeSet <>();"%s/%s" , ROOT, node)));String smallNode = subNodeSet.first();String preNode = subNodeSet.lower(nodeName);if (nodeName.equals(smallNode)) {return ;CountDownLatch waitLockLatch = new CountDownLatch (1 );Stat stat = zkClient.exists(preNode, watchedEvent -> {if (watchedEvent.getType() == Watcher.Event.EventType.NodeDeleted) {if (stat != null ) {catch (Exception e) {@Override public void unLock () {String nodeName = nodeInfo.get();try {if (nodeName != null ) {1 );catch (Exception e) {static int NUM = 0 ;public static void main (String[] args) throws InterruptedException {Executor executor = Executors.newFixedThreadPool(100 );ZookeeperLock zookeeperLock = new ZookeeperLock ("count" );CountDownLatch latch = new CountDownLatch (1000 );for (int i = 0 ; i < 1000 ; i++) {try {finally {"NUM = {}" , NUM);
Curator使用手册
Curator是Netflix公司开源的一套zookeeper客户端框架,Curator是对Zookeeper支持最好的客户端框架。Curator封装了大部分Zookeeper的功能,比如Leader选举、分布式锁等,减少了技术人员在使用Zookeeper时的底层细节开发工作
使用原生API存在的问题
会话连接是异步的,需要自己去处理。比如使用 CountDownLatch Watch 需要重复注册,不然就不能生效 开发的复杂性比较高 不支持多节点删除和创建。需要自己去递归 Curator主要实现了下面四种锁
InterProcessMutex:分布式可重入排它锁 InterProcessSemaphoreMutex:分布式排它锁 InterProcessReadWriteLock:分布式读写锁 InterProcessMultiLock:将多个锁作为单个实体管理的容器 分布式可重入排他锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Slf4j @SpringBootTest public class InterProcessMutexTest {@Autowired private CuratorFramework curatorFramework;@Test @SneakyThrows public void test () {CountDownLatch countDownLatch = new CountDownLatch (100 );ExecutorService executorService = Executors.newFixedThreadPool(100 );String lockNode = "/lock" ;InterProcessMutex lock = new InterProcessMutex (curatorFramework, lockNode);for (int i = 0 ; i < 100 ; i++) {try {"线程:{} 获得分布式锁" , Thread.currentThread().getName());100 );catch (Exception e) {finally {try {catch (Exception e) {
分布式排他锁
用法和 InterProcessMutex 一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Slf4j @SpringBootTest public class InterProcessSemaphoreMutexTest {@Autowired private CuratorFramework curatorFramework;@Test @SneakyThrows public void test () {CountDownLatch countDownLatch = new CountDownLatch (100 );ExecutorService executorService = Executors.newFixedThreadPool(100 );String lockNode = "/lock" ;InterProcessSemaphoreMutex lock = new InterProcessSemaphoreMutex (curatorFramework, lockNode);for (int i = 0 ; i < 100 ; i++) {try {"线程:{} 获得分布式锁" , Thread.currentThread().getName());catch (Exception e) {finally {try {catch (Exception e) {
分布式读写锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 @Slf4j @SpringBootTest public class InterProcessReadWriteLockTest {@Autowired private CuratorFramework curatorFramework;@Test @SneakyThrows public void test () {CountDownLatch countDownLatch = new CountDownLatch (22 );ExecutorService executorService = Executors.newFixedThreadPool(30 );String lockNode = "/lock" ;InterProcessReadWriteLock lock = new InterProcessReadWriteLock (curatorFramework, lockNode);InterProcessMutex readLock = lock.readLock();InterProcessMutex writeLock = lock.writeLock();for (int i = 0 ; i < 10 ; i++) {"获取读锁" , countDownLatch));for (int i = 0 ; i < 2 ; i++) {"获取写锁" , countDownLatch));for (int i = 0 ; i < 10 ; i++) {"获取读锁" , countDownLatch));public void tryLock (InterProcessMutex lock, String msg, CountDownLatch countDownLatch) {try {"线程:{} 获取{}" , Thread.currentThread().getName(), msg);3 );catch (Exception e) {finally {try {catch (Exception e) {
分布式锁容器
curator实现了一个类似容器的锁InterProcessMultiLock,它可以把多个锁包含起来像一个锁一样进行操作,简单来说就是对多个锁进行一组操作。当acquire的时候就获得多个锁资源,否则失败。当release时候释放所有锁资源,不过如果其中一把锁释放失败将会被忽略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @Slf4j @SpringBootTest public class InterProcessMultiLockTest {@Autowired private CuratorFramework curatorFramework;@Test @SneakyThrows public void test () {CountDownLatch countDownLatch = new CountDownLatch (10 );ExecutorService executorService = Executors.newFixedThreadPool(5 );String lockNode1 = "/lock1" ;String lockNode2 = "/lock2" ;InterProcessMutex lock1 = new InterProcessMutex (curatorFramework, lockNode1);InterProcessSemaphoreMutex lock2 = new InterProcessSemaphoreMutex (curatorFramework, lockNode2);InterProcessMultiLock multiLock = new InterProcessMultiLock (Arrays.asList(lock1, lock2));for (int i = 0 ; i < 10 ; i++) {try {"线程:{} 获取锁" , Thread.currentThread().getName());1 );catch (Exception e) {finally {try {catch (Exception e) {
ZooKeeper将所有的数据存储在一个内存中的数据结构称为 Data Tree 中。这允许快速的读取操作,因为所有的数据都在内存中。但为了持久化和恢复,ZooKeeper使用了以下机制来保存数据到磁盘。
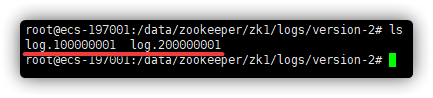
事务日志
每当ZooKeeper的数据发生变化时(例如,创建、删除或更新znodes),这些变化都会作为一个事务写入到事务日志中。事务日志是ZooKeeper保持数据一致性的关键,允许它在崩溃后重新构建数据状态。
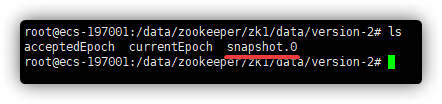
数据快照
为了减少磁盘I/O,ZooKeeper周期性地将整个Data Tree的状态保存到磁盘上的快照文件中。快照包含了在特定时间点上所有znodes的数据和状态信息。
zk通过两种形式的持久化,在恢复时先全量恢复快照文件中的数据到内存中,再用日志文件中的数据做增量恢复,这样的恢复速度更快。
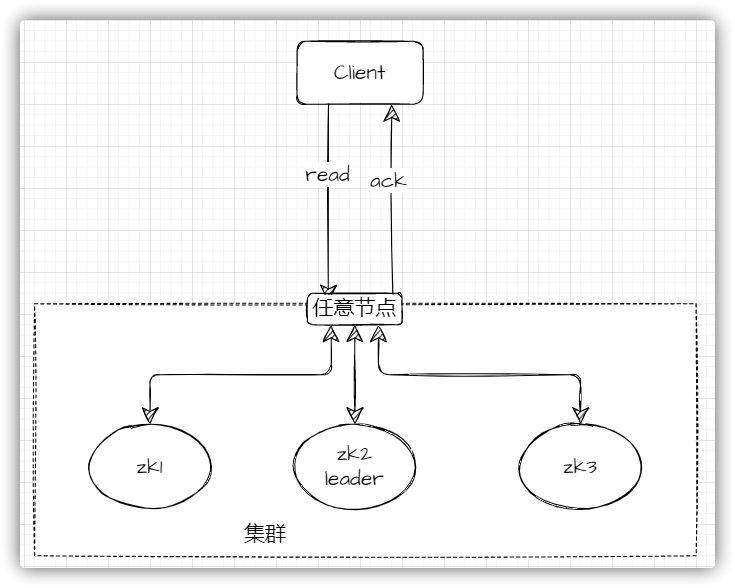
集群中任意节点都是可读的
遵循 BASE 理论
请求发送Leader、Follower 或 Observer )发送读取请求。本地读取最终一致性ZooKeeper 是一个为分布式应用提供协调服务的关键系统,通常部署多节点集群以确保高可用性。集群中的节点可以扮演领导者(Leader)、跟随者(Follower)或观察者(Observer)的角色。领导者处理所有的写请求,确保数据的一致性,而跟随者和观察者则参与读请求和状态的复制。
ZooKeeper 通过实现 ZAB(ZooKeeper Atomic Broadcast)协议来维护集群数据的一致性。ZAB 协议是特别为ZooKeeper设计的,以确保即使在领导者更换或系统崩溃后也能够保持数据的一致性。ZAB协议负责:
最大化容错能力
奇数节点集群能够在不增加冗余节点的同时,最大化容错能力。例如,有3个节点的集群可以容忍1个节点失败。一个有4个节点的集群也只能容忍1个节点失败。
避免脑裂
脑裂是指集群在网络分区发生时分成两个独立的部分,每部分都可能独自做出决策。奇数节点集群在分区发生时,不可能有两个等大的部分,这样就总有一个部分能够维持多数派,从而保持集群的正常运作。
决策效率
在进行领导者选举或其他需要多数派同意的操作时,奇数节点集群能更快地达成决策,因为不会出现票数相等的情况,从而避免了决策的延迟。
遵循 BASE理论
ZooKeeper选择优先保证一致性(C)和分区容错性(P),在网络分区发生时,它会牺牲一部分可用性以保持一致性。这里的一致性是指线性一致性或顺序一致性,意味着系统保证一旦更新操作完成,所有后续的读操作都将返回该更新的值,形成一个全局一致的操作顺序。