友情连接 http://coderead.cn/
完整的JDBC查询过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Slf4j public class JdbcTest {public static void main (String[] args) throws ClassNotFoundException, SQLException {"com.mysql.cj.jdbc.Driver" );Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai" , "root" , "root" );PreparedStatement preparedStatement = connection.prepareStatement("select * from tb_user where id = ?" );1 , 1 );ResultSet resultSet = preparedStatement.executeQuery();while (resultSet.next()) {int id = resultSet.getInt("id" );String name = resultSet.getString("name" );int age = resultSet.getInt("age" );"id: {}" , id);"name: {}" , name);"age: {}" , age);
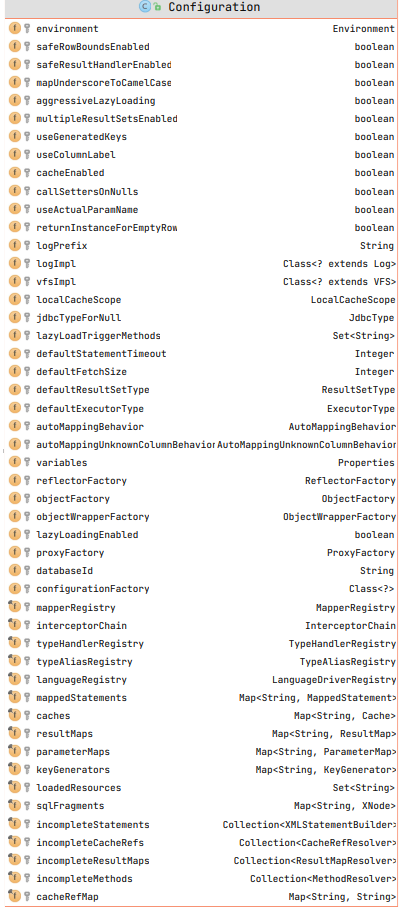
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 public class Configuration {protected Environment environment;protected boolean safeRowBoundsEnabled;protected boolean safeResultHandlerEnabled = true ;protected boolean mapUnderscoreToCamelCase;protected boolean aggressiveLazyLoading;protected boolean multipleResultSetsEnabled = true ;protected boolean useGeneratedKeys;protected boolean useColumnLabel = true ;protected boolean cacheEnabled = true ;protected boolean callSettersOnNulls;protected boolean useActualParamName = true ;protected boolean returnInstanceForEmptyRow;protected String logPrefix;protected Class<? extends Log > logImpl;protected Class<? extends VFS > vfsImpl;protected LocalCacheScope localCacheScope = LocalCacheScope.SESSION;protected JdbcType jdbcTypeForNull = JdbcType.OTHER;protected Set<String> lazyLoadTriggerMethods = new HashSet <>(Arrays.asList("equals" , "clone" , "hashCode" , "toString" ));protected Integer defaultStatementTimeout;protected Integer defaultFetchSize;protected ResultSetType defaultResultSetType;protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;protected AutoMappingBehavior autoMappingBehavior = AutoMappingBehavior.PARTIAL;protected AutoMappingUnknownColumnBehavior autoMappingUnknownColumnBehavior = AutoMappingUnknownColumnBehavior.NONE;protected Properties variables = new Properties ();protected ReflectorFactory reflectorFactory = new DefaultReflectorFactory ();protected ObjectFactory objectFactory = new DefaultObjectFactory ();protected ObjectWrapperFactory objectWrapperFactory = new DefaultObjectWrapperFactory ();protected boolean lazyLoadingEnabled = false ;protected ProxyFactory proxyFactory = new JavassistProxyFactory (); protected String databaseId;protected Class<?> configurationFactory;protected final MapperRegistry mapperRegistry = new MapperRegistry (this );protected final InterceptorChain interceptorChain = new InterceptorChain ();protected final TypeHandlerRegistry typeHandlerRegistry = new TypeHandlerRegistry ();protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry ();protected final LanguageDriverRegistry languageRegistry = new LanguageDriverRegistry ();protected final Map<String, MappedStatement> mappedStatements = new StrictMap <MappedStatement>("Mapped Statements collection" )". please check " + savedValue.getResource() + " and " + targetValue.getResource());protected final Map<String, Cache> caches = new StrictMap <>("Caches collection" );protected final Map<String, ResultMap> resultMaps = new StrictMap <>("Result Maps collection" );protected final Map<String, ParameterMap> parameterMaps = new StrictMap <>("Parameter Maps collection" );protected final Map<String, KeyGenerator> keyGenerators = new StrictMap <>("Key Generators collection" );protected final Set<String> loadedResources = new HashSet <>();protected final Map<String, XNode> sqlFragments = new StrictMap <>("XML fragments parsed from previous mappers" );protected final Collection<XMLStatementBuilder> incompleteStatements = new LinkedList <>();protected final Collection<CacheRefResolver> incompleteCacheRefs = new LinkedList <>();protected final Collection<ResultMapResolver> incompleteResultMaps = new LinkedList <>();protected final Collection<MethodResolver> incompleteMethods = new LinkedList <>();protected final Map<String, String> cacheRefMap = new HashMap <>();public Configuration (Environment environment) {this ();this .environment = environment;
Mybatis 上下文配置,项目启动会根据配置的mapperLocations加载解析XML文件,最终将解析好的XML配置信息装载到自身属性中,在SqlSessionFactoryBean的afterPropertiesSet方法中被创建
interceptorChain 拦截器链 typeHandlerRegistry 类型处理器 typeAliasRegistry 别名处理器 resultMaps 返回结果映射 keyGenerators主键生成映射 mappedStatements 数据库语句映射(mapper 文件sql) sqlFragments SQL语句片段,即所有的节点 caches 缓存(一级缓存) …
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public interface SqlSessionFactory {openSession () ;openSession (boolean autoCommit) ;openSession (Connection connection) ;openSession (TransactionIsolationLevel level) ;openSession (ExecutorType execType) ;openSession (ExecutorType execType, boolean autoCommit) ;openSession (ExecutorType execType, TransactionIsolationLevel level) ;openSession (ExecutorType execType, Connection connection) ;getConfiguration () ;
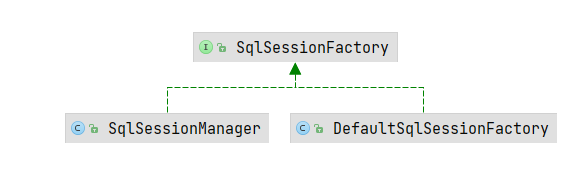
SqlSession会话工厂,用于获取SqlSession。通过SqlSessionFactoryBean的getObject方法创建,创建SqlSessionFactory的前提是解析Mapper配置文件创建Configuration对象后创建,因为DefaultSqlSessionFactory构造函数需要Configuration参数
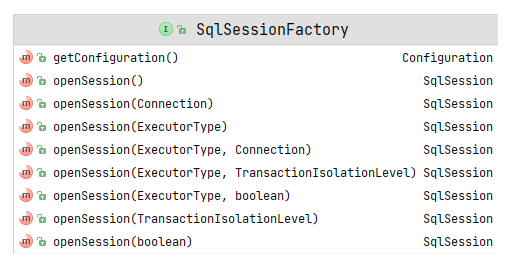
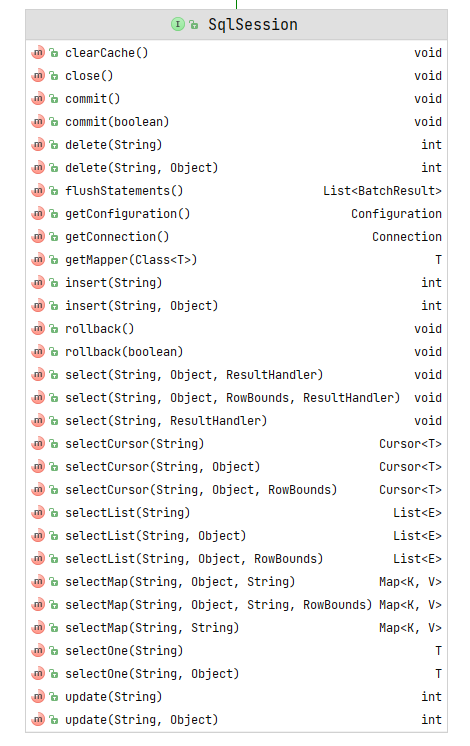
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 public interface SqlSession extends Closeable {selectOne (String statement) ;selectOne (String statement, Object parameter) ;selectList (String statement) ;selectList (String statement, Object parameter) ;selectList (String statement, Object parameter, RowBounds rowBounds) ;selectMap (String statement, String mapKey) ;selectMap (String statement, Object parameter, String mapKey) ;selectMap (String statement, Object parameter, String mapKey, RowBounds rowBounds) ;void select (String statement, Object parameter, ResultHandler handler) ;void select (String statement, ResultHandler handler) ;void select (String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) ;int insert (String statement) ;int insert (String statement, Object parameter) ;int update (String statement) ;int update (String statement, Object parameter) ;int delete (String statement) ;int delete (String statement, Object parameter) ;void commit () ;void commit (boolean force) ;void rollback () ;void rollback (boolean force) ;flushStatements () ;@Override void close () ;void clearCache () ;getConfiguration () ;getMapper (Class<T> type) ;getConnection () ;
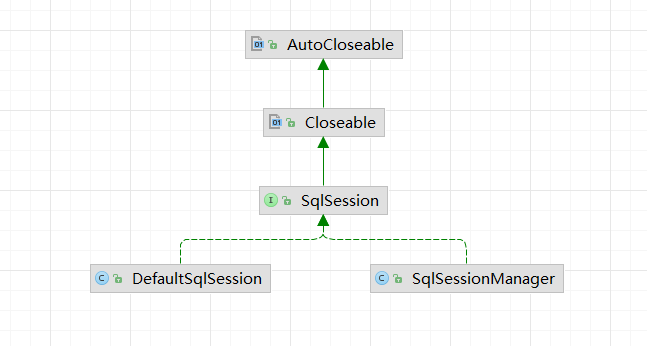
数据库会话,使用外观模式提供操作数据库的方法,具体实现底层调用Executor,设计这一层的目的是对,外屏蔽Executor底层调用的复杂性,DefaultSqlSession中包含Executor对象
功能
数据库操作 RURD 事务管理 提交回滚事务 获取连接 1 2 3 4 5 6 7 @Test public void sqlSessionTest () {SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.SIMPLE);"com.wgf.modules.sys.dao.SysUserDao.queryByUserName" , "admin" );"com.wgf.modules.sys.dao.SysUserDao.queryByUserName" , "admin" );
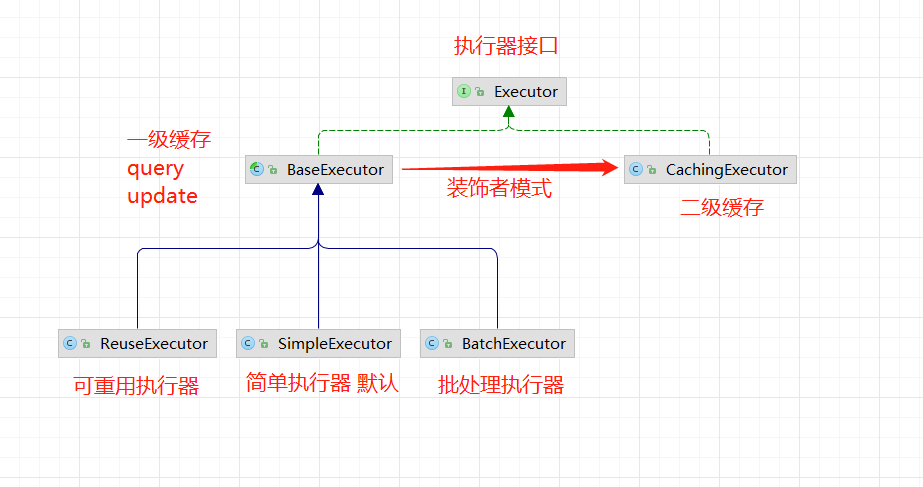
Executor是MyBatis执行者接口,执行器的功能包括:
基本功能:改、查,没有增删的原因是,所有的增删操作在JDBC都可以归结到改 缓存维护:这里的缓存主要是为一级缓存服务,功能包括创建缓存Key、清理缓存、判断缓存是否存在 事务管理:提交、回滚、关闭 批处理刷新 单元测试公共代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Autowired @Before public void init () throws SQLException {"jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai" "root" "root" );new JdbcTransaction (connection);
将Executor的共性抽取出一个公共的父类
基础执行器主要是用于维护缓存和事务。事务是通过会话中调用commit、rollback进行管理。重点在于缓存这块它是如何处理的? (这里的缓存是指一级缓存 ),它实现了Executor中的query与update方法。会话中SQL请求,正是调用的这两个方法。query方法中处理一级缓存逻辑,即根据SQL及参数判断缓存中是否存在数据,有就走缓存。否则就会调用子类的doQuery() 方法去查询数据库,然后在设置缓存。在doUpdate() 中主要是用于清空缓存
共性
一级缓存 事务管理 获取、提交、回滚、关闭 数据库基本操作 query,update (除了查询为的操作可归并为update) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Test public void baseExecutor () throws SQLException {SimpleExecutor simpleExecutor = new SimpleExecutor (configuration, jdbcTransaction);MappedStatement mappedStatement = configuration.getMappedStatement("com.wgf.modules.sys.dao.SysUserDao.queryByUserName" );"admin" , RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);"admin" , RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);
SimpleExecutor是默认执行器 ,它的行为是每处理一次会话当中的SQl请求都会通过对应的StatementHandler 构建一个新个Statement,这就会导致即使是相同SQL语句也无法重用Statement,所以就有了(ReuseExecutor)可重用执行器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Test public void simpleExecutor () throws SQLException {SimpleExecutor simpleExecutor = new SimpleExecutor (configuration, jdbcTransaction);MappedStatement mappedStatement = configuration.getMappedStatement("com.wgf.modules.sys.dao.SysUserDao.queryByUserName" );"admin" , RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, mappedStatement.getBoundSql("admin" ));"admin" , RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, mappedStatement.getBoundSql("admin" ));
重用的是 PreparedStatemen对象,减少预编译sql次数
ReuseExecutor 区别在于他会将在会话期间内的Statement进行缓存 ,并使用SQL语句作为Key。所以当执行下一请求的时候,不在重复构建Statement,而是从缓存中取出并设置参数,然后执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Test public void reuseExecutor () throws SQLException {ReuseExecutor reuseExecutor = new ReuseExecutor (configuration, jdbcTransaction);MappedStatement mappedStatement = configuration.getMappedStatement("com.wgf.modules.sys.dao.SysUserDao.queryByUserName" );"admin" , RowBounds.DEFAULT, ReuseExecutor.NO_RESULT_HANDLER, mappedStatement.getBoundSql("admin" ));"admin" , RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, mappedStatement.getBoundSql("admin" ));
sql语句相同,顺序连贯(为保证sql执行的准确性),才能合并
BatchExecutor 顾名思议,它就是用来作批处理的。但会将所 有SQL请求集中起来,最后调用Executor.flushStatements() 方法时一次性将所有请求发送至数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void batchExecutor () throws SQLException {BatchExecutor reuseExecutor = new BatchExecutor (configuration, jdbcTransaction);MappedStatement mappedStatement = configuration.getMappedStatement("com.wgf.modules.sys.dao.SysUserDao.updateNameById" );new HashMap <>();"arg0" , 1 );"arg1" , "admin" );
查看Executor 的子类还有一个CachingExecutor,这是用于处理二级缓存的。为什么不把它和一级缓存一起处理呢?因为二级缓存和一级缓存相对独立的逻辑,而且二级缓存可以通过参数控制关闭,而一级缓存是不可以的。综上原因把二级缓存单独抽出来处理。抽取的方式采用了装饰者设计模式,即在CachingExecutor 对原有的执行器进行包装,处理完二级缓存逻辑之后,把SQL执行相关的逻辑交给实至的Executor处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Test public void cachingExecutor () throws SQLException {SimpleExecutor simpleExecutor = new SimpleExecutor (configuration, jdbcTransaction);CachingExecutor cachingExecutor = new CachingExecutor (simpleExecutor);MappedStatement mappedStatement = configuration.getMappedStatement("com.wgf.modules.sys.dao.SysUserDao.queryByUserName" );"admin" , RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);true );"admin" , RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
配置文件 mybatis-config.xml 1 2 3 4 <settings > <setting name ="cacheEnabled" value ="true" /> </settings >
在 Mapper.xml 文件中添加cache标签
在要使用二级缓存的Mapper.xml文件中添加cache标签
1 2 3 4 5 6 <cache eviction ="FIFO" flushInterval ="60000" size ="512" readOnly ="true" />
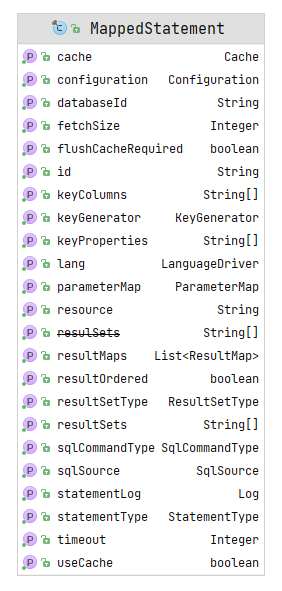
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public final class MappedStatement {private String resource;private Configuration configuration;private String id;private Integer fetchSize;private Integer timeout;private StatementType statementType;private ResultSetType resultSetType;private SqlSource sqlSource;private Cache cache;private ParameterMap parameterMap;private List<ResultMap> resultMaps;private boolean flushCacheRequired;private boolean useCache;private boolean resultOrdered;private SqlCommandType sqlCommandType;private KeyGenerator keyGenerator;private String[] keyProperties;private String[] keyColumns;private boolean hasNestedResultMaps;private String databaseId;private Log statementLog;private LanguageDriver lang;private String[] resultSets;public static class Builder {private MappedStatement mappedStatement = new MappedStatement ();
MappedStatement维护了一条<select|update|delete|insert>节点的封装,也就是说一个Mapper类的方法会产生一个MappedStatement对象,它存储在Configuration的mappedStatementsmap存储,key为 Mapper全类名.方法名
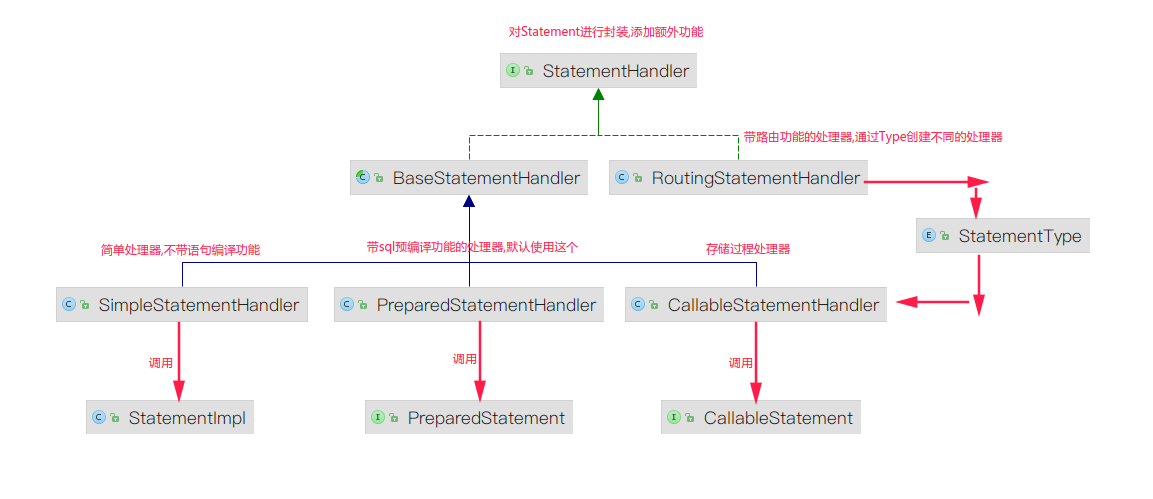
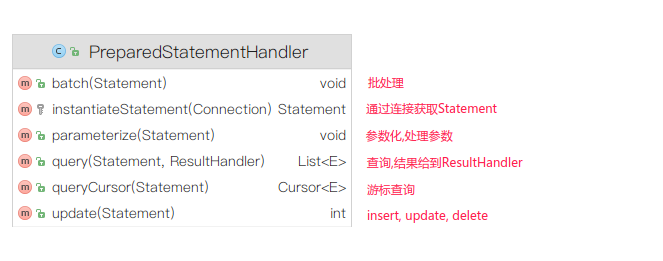
对JDBC的Statement进行封装,负责操作 Statement 对象与数据库进行交流,在工作时还会使用 ParameterHandler 和 ResultSetHandler 对参数进行映射,对结果进行实体类的绑定
Mapper XML 配置文件中可以手动指定StatementHandler
1 2 <select id ="page" resultMap ="voMap" statementType ="PREPARED" >
对JDBC的StatementImpl进行封装,添加返回结果映射到java实体,不支持SQL预编译
支持通过占位符实现SQL预编译的处理器,可以防止SQL注入,默认使用这个处理器
支持执行存储过程的StatementHandler
mybatis的缓存体系是框架内部实现的,和数据库没有任何关系,myBatis中存在两个缓存,一级缓存和二级缓存
如果开启了二级缓存,执行顺序二级缓存 > 一级缓存 > 数据库获取
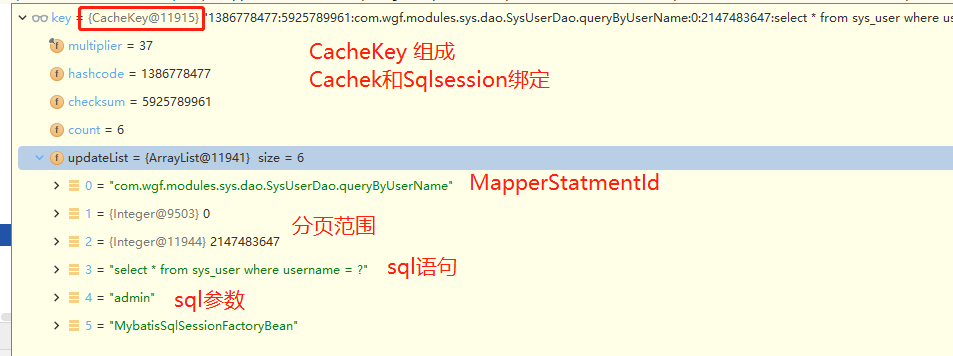
由 BaseExecutore 内部的 PerpetualCache 对象存储,PerpetualCache 内部使用map存储 缓存key -> 数据的映射关系
SQL语句与参数相同 同一个会话 (sqlSession) 相同的MapperStatement ID RowBounds行范围相同 (分页对象)
在使用Mybatis生成的Mapper代理类执行相关的sql操作时,如果多个sql操作不在同一个事务内部,则无法使用一级缓存(缓存失效),原因是不在一个事务内,每次调用Mapper代理类操作数据库都会获取新的会话
缓存失效代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Test public void invalidCache () {1 );1 );
缓存生效
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test @Transactional(readOnly = true) public void tran () {1 );1 );
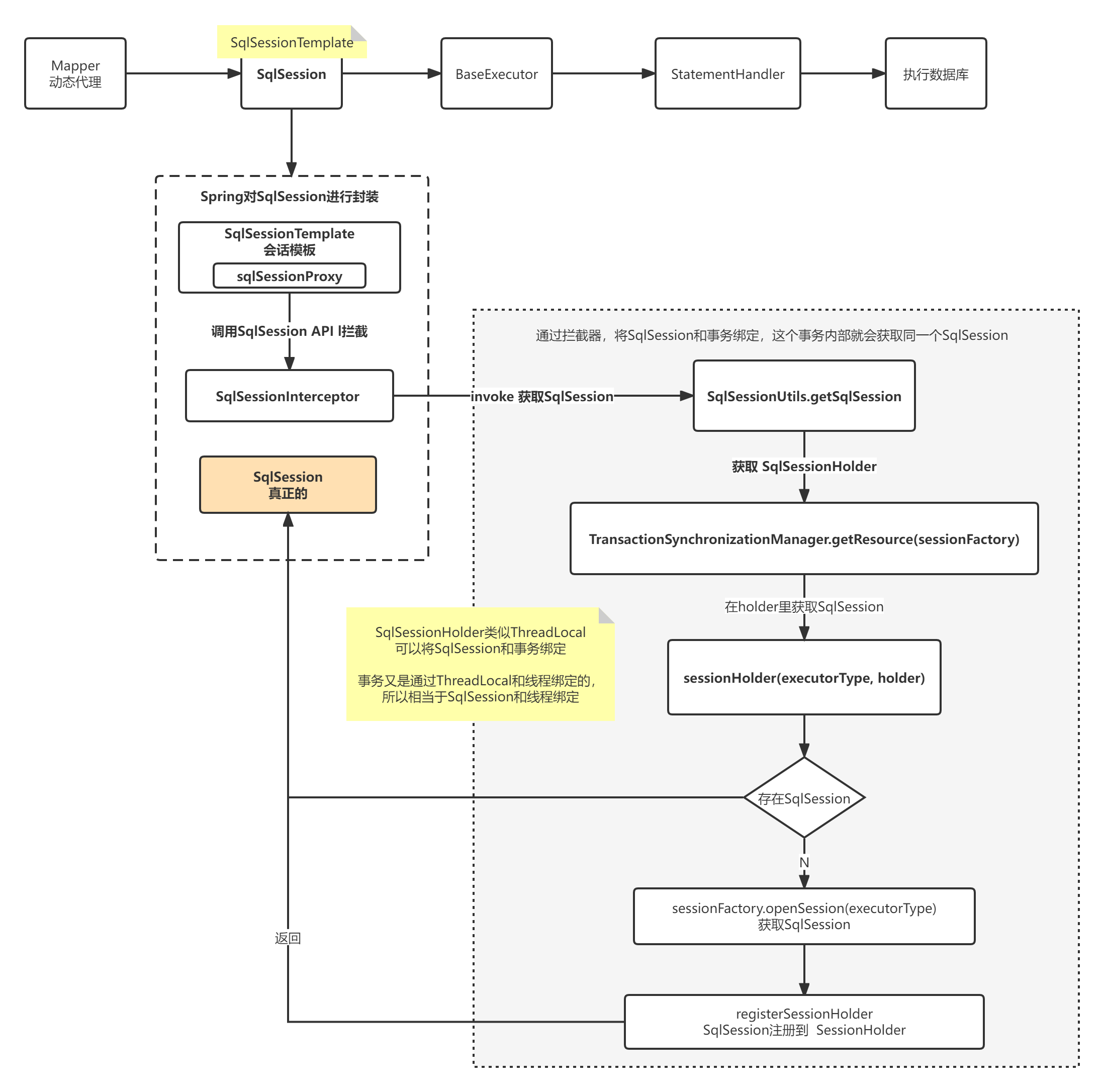
为了对事务的支持,Mybatis的Spring模块对SqlSession进行了封装,通过SqlSessionTemplae ,使得如果不在一个事务内调用Mapper ,每次都会重新构建一个SqlSession ,具体参见SqlSessionInterceptor ,解决的方法是让多个操作在一个事务内部就可以共享同一个SqlSession,这样就能使用一级缓存
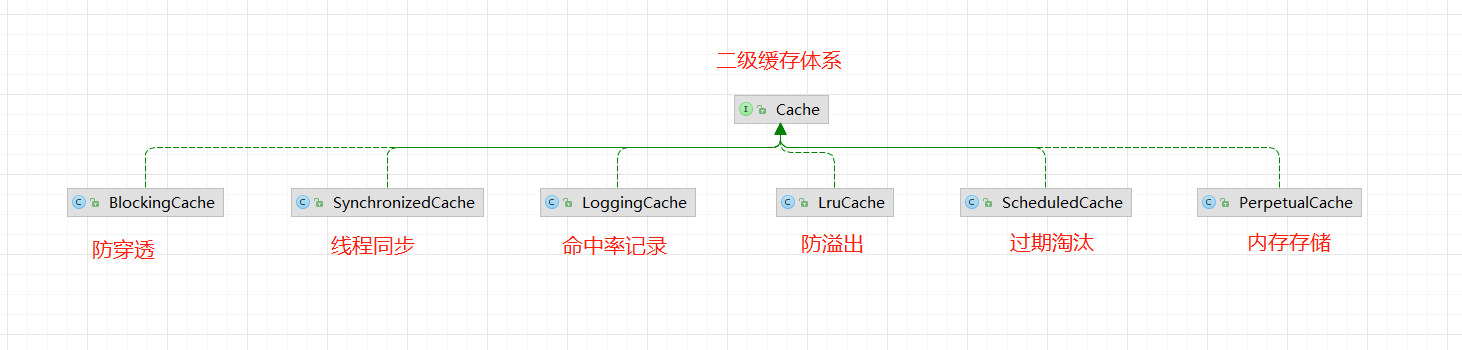
经典的装饰器加责任链模式
这样设计有以下优点:
职责单一:各个节点只负责自己的逻辑,不需要关心其它节点。 扩展性强:可根据需要扩展节点、删除节点,还可以调换顺序保证灵活性。 松耦合:各节点之间不没强制依赖其它节点。而是通过顶层的Cache接口进行间接依赖。 启用
xml
1 <cache eviction ="FIFO" flushInterval ="60000" size ="512" readOnly ="true" />
注解
1 2 3 4 5 6 类上使用@CacheNamespace Mapper开启二级缓存@CacheNamespaceRef 引入其他Mapper的二级缓存@Options 设置缓存大小,过期时间等
XML配置的二级缓存和java注解配置的缓存不能同时存在
二级缓存的作用范围: NameSpace
使用代码
先开启二级缓存
1 2 3 4 5 6 7 @Mapper @CacheNamespace public interface SysUserDao extends BaseMapper <SysUserEntity> {@Select("select * from sys_user where username = #{arg0}}") public SysUserEntity selectUsername (String username) ;
二级缓存体系中存在一个事务缓存管理器 TransactionalCacheManager和事务缓存 TransactionalCach,缓存暂存区的意义在于当前事务执行了update但是还没提交事务(事务可能回滚),此时由缓存区先存着,等事务真正提交再把缓存区数据刷进二级缓存能够防止二级缓存的脏读
二级缓存生效场景
Mybatis和Spring融合
Mybatis是一个半自动ORM(对象关系映射)框架,它内部封装了JDBC,面向Sql开发,不需要花费精力去处理加载驱动、创建连接、创建statement等繁杂的过程 MyBatis 可以使用 XML 或注解来配置和映射实体和表的映射关系,避免JDBC手动设置参数和获取结果的复杂性 提供XML和注解的方式将Sql和业务代码剥离,提供访问数据的DAO层 总结 :半自动ORM,面向Sql开发,对JDBC二次封装,屏蔽JDBC复杂性减少代码量,提供动态Sql标签
面向Sql编程,提供XML和注解方式将Sql和代码玻璃,Sql便于统一管理和复用 与JDBC相比,减少了获取连接,设置参数,获取结果等最少50%代码量 能很好兼容常见的关系型数据库 提供映射标签,支持对象与数据库的ORM映射 提供DAO层访问数据库 提供动态SQL标签,支持灵活实现SQL和SQL复用 总结 :面向SQL编程,与JDBC比较,数据库兼容性,提供DAO层,映射标签,动态SQL标签
半自动ORM框架,面向Sql开发,Sql开发量大 SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库 总结: SQL开发量大,数据库可移植性差
MyBatis专注于SQL本身,是一个足够灵活的DAO层解决方案 对性能要求高,并且业务数据复杂的系统,比如互联网,ERP等 总结: 灵活的DAO层解决方案,性能高
相同点
不同点
mybatis是一个半自动化的ORM框架,配置的是java对象与SQL语句执行结果的映射 ,多表关联配置简单 Hibernate是个全自动化的ORM框架,配置Java对象与数据库表的对应关系 ,多表关联配置复杂 Hibernate可以使用HQL 面向对象编程 Hibernate对比MySQL数据库可移植性更强,底层采用HQL屏蔽数据库差异性 总结: 半自动/自动ORM,HQL,数据库移植性
ORM(Object Relational Mapping) ,对象关系映射 。ORM是用于描述对象与数据库之间的映射元数据,将程序中的对自动的持久化到关系型数据库中 总结: 对象与数据库的映射,对象持久化到数据库
全自动ORM是将对象属性与数据库表字段进行一一对应,并将表的关联关系具体体现在实体关系中 Mybatsi使用映射标签将对象字段与SQL执行结果映射而不是和表映射,需要自己配置映射关系 总结: 参数全自动ORM,SQL执行结果映射
频繁创建数据量连接对象,自己管理事务,代码量大,影响系统性能 SQL语句定义,参数填充,结果获取存在硬编码,代码不够灵活 结果集处理存在重复代码,可维护性差 总结: 连接难维护,SQL硬编码,参数设置死板,处理结果集代码冗余
数据库链接创建 ,Mybatis允许配置连接池来管理数据库连接 SQL语句剥离,使用XML和注解将SQL语句和代码剥离,统一管理 动态SQL,提供动态标签解决JDBC参数设置不灵活缺点 结果映射,通过灵活配置将结果集映射到实体上 对JDBC进行封装,屏蔽底层复杂性 总结: 支持连接池管理连接,SQL统一管理,动态SQL标签,结果映射,屏蔽JDBC复杂性
创建SqlSessionFactory 通过SqlSessionFactory创建SqlSession 通过sqlsession执行数据库操作 调用session.commit()提交事务 调用session.close()关闭会话 **总结:**Mybatis通过门面设计模式封装了SqlSession会话层,对外屏蔽了Executor调用的复杂性
读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息 加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表 构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory 创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法 Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护 MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息 输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程 输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程 API接口层:提供给外部使用的接口API,开发人员通过这些本地API来操纵数据库。接口层一接收到调用请求就会调用数据处理层来完成具体的数据处理 数据处理层:负责具体的SQL查找、SQL解析、SQL执行和执行结果映射处理等。它主要的目的是根据调用的请求完成一次数据库操作 基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加载和缓存处理,这些都是共用的东西,将他们抽取出来作为最基础的组件。为上层的数据处理层提供最基础的支撑 **定义:**SQL 预编译指的是数据库驱动在发送 SQL 语句和参数给数据库之前对 SQL 语句进行编译,这样 数据库执行 SQL 时,就不需要重新编译
为什么
防止SQL注入 JDBC 中使用对象 PreparedStatement 来抽象预编译语句,使用预编译。预编译阶段可以优化 SQL 的执行。预编译之后的 SQL 多数情况下可以直接执行,数据库不需要再次编译,越复杂的SQL,编译的复杂度将越大,预编译阶段可以合并多次操作为一个操作。同时预编译语句对象可以重复利用 **** 总结: 防止SQL注入,减少数据库编译工作
通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致 通过 来映射字段名和实体类属性名的一一对应的关系 总结: SQL字段起别名,<resultMap>br>添加映射
在代码中添加通配符
在sql语句中拼接通配符,会引起sql注入
1 select * from foo where bar like '%${bar}%'
使用 concat 函数,推荐
1 select * from where name like concat('%', #{name})
总结: java字符串拼接,$字符串拼接,concat函数
BaseExecutor : 将Executor共性抽取出一个父类,提供一级缓存,事务,数据库基本操作 CachingExecutor : 提供二级缓存功能SimpleExecutor : 默认执行器,每次执行query或update都创建一个新的Statement对象,用完立即关闭Statement对象ReuseExecutor : 使用Sql作为Key,将Statement对象缓存起来,重复使用Statement减少SQL预编译次数(SqlSession范围重用)BatchExecutor : 执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),会合并sql语句总结: mybatis XML setting配置,yml 文件配置, DefaultSqlSessionFactory 参数传入
总结 :允许重载,只能有一个映射
分页
Mybatis 使用 RowBounds 对象进行分页,也可以直接编写 sql 实现分页,也可以使用Mybatis 的分页插件
插件原理
实现 Mybatis 提供的接口,实现自定义插件,在插件的拦截方法内拦截待执行的 sql,然后重写 sql
总结: RowBounds,编写SQL,使用分页插件,自定义插件,拦截sql且重写
第一种是使用 标签,逐一定义数据库列名和对象属性名之间的映射关系 第二种是使用sql列的别名功能,将列的别名书写为对象属性名 有了列名与属性名的映射关系后,Mybatis通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的 总结: <resultMap>,sql别名和字段名对应,反射创建对象并赋值
insert 方法总是返回一个int值 ,这个值代表的是插入的行数 update 方法返回一个int值,是受影响行数 xml中设置 useGeneratedKeys=“true” keyProperty=“id” 总结: useGeneratedKeys,keyProperty
下表占位符 #{arg0}, #{arg1} @Param注解 使用Map传参 使用实体传参 总结 :#{arg0},@Param
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载 ,association指的就是一对一,collection指的就是一对多查询,可以配置是否启用延迟加载lazyLoadingEnabled=true|false 原理:它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理 总结 :关联关系允许懒加载
Mybatis动态sql可以在Xml映射文件内,以标签的形式编写动态sql,执行原理是根据表达式的值完成逻辑判断并动态拼接sql的功能 通过动态sql标签灵活装配SQL Mybatis提供了9种动态sql标签: trim| where| set| foreach| if|choose| when| otherwise| bind 不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复 原因是Mybatis的配置中MapperStatement是根据 namespace+id 作为作为Map <String,MapperStatement>的key使用的 ,保证namespace+id不重复就行 总结 :MapperStatement -> namespace + id
一对一使用associate,一个类根据关联字段对应着一个类,实体类里声明另一个实体类 一对多使用collection,一个类根据关联字段对应着多个类,实体类里声明另一个实体类的List 多对一使用associate,多个类根据关联字段对应着一个类,实体类里声明另一个实体类 总结:associate,collection
基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源 总结 :一级缓存会话独享,二级缓存会话共享,一级缓存是SqlSession级别缓存,二级缓存是SqlSessionFactory级别缓存
总结 :实现 Interceptor接口,重写 intercept方法,注解配置拦截方法,配置文件配置插件