Sort
排序
堆排序

什么是堆?
堆就是用数组实现的二叉树,所以它没有使用父指针或者子指针。堆根据“堆属性”来排序,“堆属性”决定了树中节点的位置
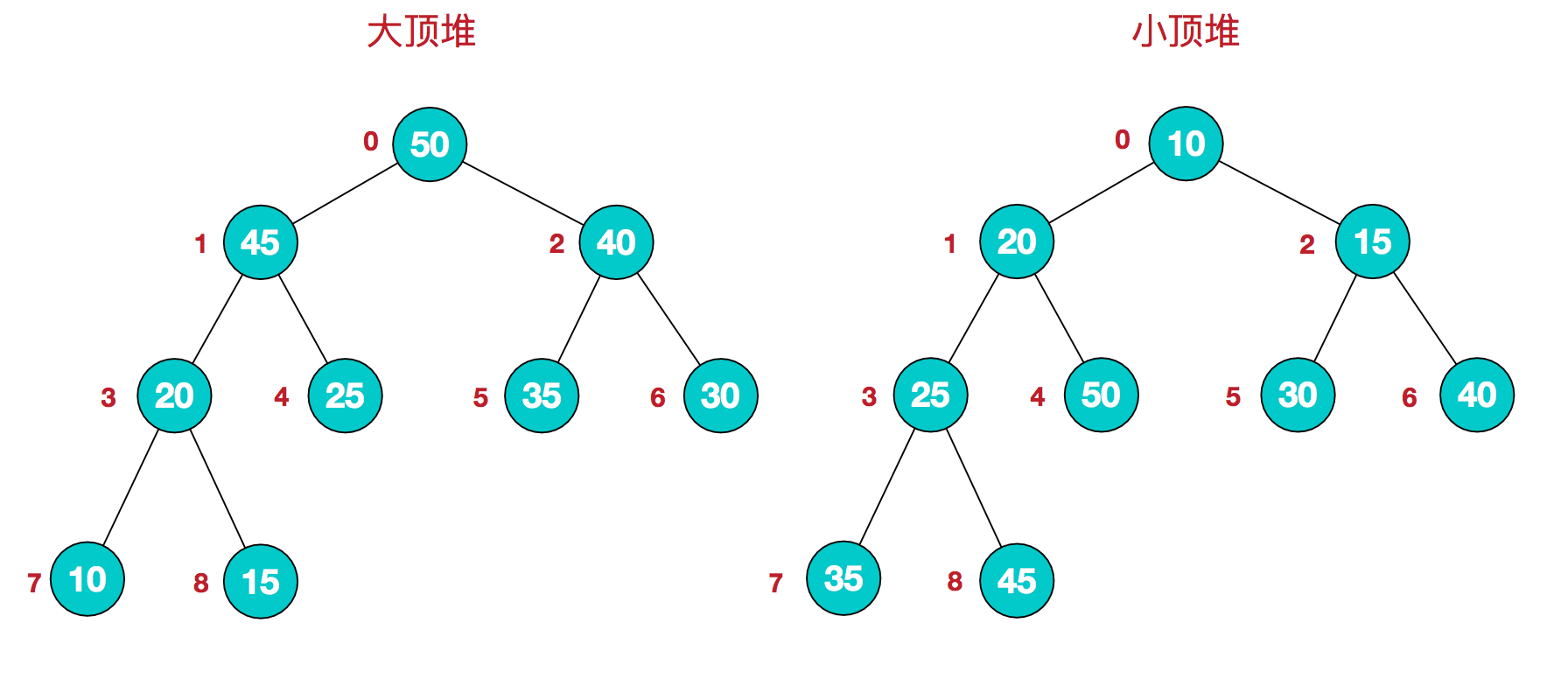
定义
通常堆是通过一维数组来实现的。在数组起始位置为0的情形中:
- 父节点i的左子节点在位置:2i+1
- 父节点i的右子节点在位置:2i+2
- 子节点i的父节点在位置:i/2 -1
- 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列
- 小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列

堆的操作
在堆的数据结构中,堆中的最大值总是位于根节点(在优先队列中使用堆的话堆中的最小值位于根节点)。堆中定义以下几种操作:
- 最大堆调整(Max Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
- 创建最大堆(Build Max Heap):将堆中的所有数据重新排序
- 堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
JUC中的优先级队列就是使用小顶堆来实现的
堆排序算法步骤
将待排序的数组初始化为大顶堆,该过程即建堆
将堆顶元素与最后一个元素进行交换,除去最后一个元素外可以组建为一个新的大顶堆
由于第二步堆顶元素跟最后一个元素交换后,新建立的堆不是大顶堆,需要重新建立大顶堆。重复上面的处理流程,直到堆中仅剩下一个元素
代码实现
1 | |
经典 Top K 问题
除了排序外,经常还利用大顶堆、小顶堆解决 Top K 问题
大顶堆: 从N个数中找出最小的K个
小顶堆:从N个数中找出最大的K个
核心思想:最大K个,先获取K个值,建立小顶堆。然后遍历 K~N的元素,与堆顶比较,元素比堆顶大则进行替换。然后再重新构建小顶堆。当循环多次后,堆顶能够过滤掉大部分数据
Top K 也能使用一个长度为K的链表进行排序,记录最大值和最小值(链头,链尾),然后循环K~N的元素进行比较,如果元素最小值<元素则从链表头部插入,如果元素>最大值则从链表尾部插入,值相等不插入,当链表超过K长度,修剪链表头部 (海量数据TOP K 数据漏斗思想)
实现
1 | |
Sort
https://wugengfeng.cn/2022/03/11/Sort/